 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$V_1$: Unifying Generation and Self-Verification for Parallel Reasoners
Mar 04, 2026Test-time scaling for complex reasoning tasks shows that leveraging inference-time compute, by methods such as independently sampling and aggregating multiple solutions, results in significantly better task outcomes. However, a critical bottleneck is verification: sampling is only effective if correct solutions can be reliably identified among candidates. While existing approaches typically evaluate candidates independently via scalar scoring, we demonstrate that models are substantially stronger at pairwise self-verification. Leveraging this insight, we introduce $V_1$, a framework that unifies generation and verification through efficient pairwise ranking. $V_1$ comprises two components: $V_1$-Infer, an uncertainty-guided algorithm using a tournament-based ranking that dynamically allocates self-verification compute to candidate pairs whose relative correctness is most uncertain; and $V_1$-PairRL, an RL framework that jointly trains a single model as both generator and pairwise self-verifier, ensuring the verifier adapts to the generator's evolving distribution. On code generation (LiveCodeBench, CodeContests, SWE-Bench) and math reasoning (AIME, HMMT) benchmarks, $V_1$-Infer improves Pass@1 by up to $10%$ over pointwise verification and outperforms recent test-time scaling methods while being significantly more efficient. Furthermore, $V_1$-PairRL achieves $7$--$9%$ test-time scaling gains over standard RL and pointwise joint training, and improves base Pass@1 by up to 8.7% over standard RL in a code-generation setting.
Linear Script Representations in Speech Foundation Models Enable Zero-Shot Transliteration
Jan 06, 2026Multilingual speech foundation models such as Whisper are trained on web-scale data, where data for each language consists of a myriad of regional varieties. However, different regional varieties often employ different scripts to write the same language, rendering speech recognition output also subject to non-determinism in the output script. To mitigate this problem, we show that script is linearly encoded in the activation space of multilingual speech models, and that modifying activations at inference time enables direct control over output script. We find the addition of such script vectors to activations at test time can induce script change even in unconventional language-script pairings (e.g. Italian in Cyrillic and Japanese in Latin script). We apply this approach to inducing post-hoc control over the script of speech recognition output, where we observe competitive performance across all model sizes of Whisper.
ABBEL: LLM Agents Acting through Belief Bottlenecks Expressed in Language
Dec 23, 2025As the length of sequential decision-making tasks increases, it becomes computationally impractical to keep full interaction histories in context. We introduce a general framework for LLM agents to maintain concise contexts through multi-step interaction: Acting through Belief Bottlenecks Expressed in Language (ABBEL), and methods to further improve ABBEL agents with RL post-training. ABBEL replaces long multi-step interaction history by a belief state, i.e., a natural language summary of what has been discovered about task-relevant unknowns. Under ABBEL, at each step the agent first updates a prior belief with the most recent observation from the environment to form a posterior belief, then uses only the posterior to select an action. We systematically evaluate frontier models under ABBEL across six diverse multi-step environments, finding that ABBEL supports generating interpretable beliefs while maintaining near-constant memory use over interaction steps. However, bottleneck approaches are generally prone to error propagation, which we observe causing inferior performance when compared to the full context setting due to errors in belief updating. Therefore, we train LLMs to generate and act on beliefs within the ABBEL framework via reinforcement learning (RL). We experiment with belief grading, to reward higher quality beliefs, as well as belief length penalties to reward more compressed beliefs. Our experiments demonstrate the ability of RL to improve ABBEL's performance beyond the full context setting, while using less memory than contemporaneous approaches.
Visually Prompted Benchmarks Are Surprisingly Fragile
Dec 19, 2025



A key challenge in evaluating VLMs is testing models' ability to analyze visual content independently from their textual priors. Recent benchmarks such as BLINK probe visual perception through visual prompting, where questions about visual content are paired with coordinates to which the question refers, with the coordinates explicitly marked in the image itself. While these benchmarks are an important part of VLM evaluation, we find that existing models are surprisingly fragile to seemingly irrelevant details of visual prompting: simply changing a visual marker from red to blue can completely change rankings among models on a leaderboard. By evaluating nine commonly-used open- and closed-source VLMs on two visually prompted tasks, we demonstrate how details in benchmark setup, including visual marker design and dataset size, have a significant influence on model performance and leaderboard rankings. These effects can even be exploited to lift weaker models above stronger ones; for instance, slightly increasing the size of the visual marker results in open-source InternVL3-8B ranking alongside or better than much larger proprietary models like Gemini 2.5 Pro. We further show that low-level inference choices that are often ignored in benchmarking, such as JPEG compression levels in API calls, can also cause model lineup changes. These details have substantially larger impacts on visually prompted benchmarks than on conventional semantic VLM evaluations. To mitigate this instability, we curate existing datasets to create VPBench, a larger visually prompted benchmark with 16 visual marker variants. VPBench and additional analysis tools are released at https://lisadunlap.github.io/vpbench/.
Long Chain-of-Thought Reasoning Across Languages
Aug 20, 2025

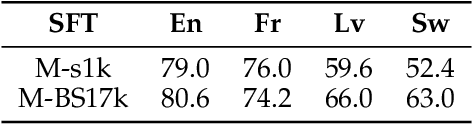

Scaling inference through long chains-of-thought (CoTs) has unlocked impressive reasoning capabilities in large language models (LLMs), yet the reasoning process remains almost exclusively English-centric. We construct translated versions of two popular English reasoning datasets, fine-tune Qwen 2.5 (7B) and Qwen 3 (8B) models, and present a systematic study of long CoT generation across French, Japanese, Latvian, and Swahili. Our experiments reveal three key findings. First, the efficacy of using English as a pivot language varies by language: it provides no benefit for French, improves performance when used as the reasoning language for Japanese and Latvian, and proves insufficient for Swahili where both task comprehension and reasoning remain poor. Second, extensive multilingual pretraining in Qwen 3 narrows but does not eliminate the cross-lingual performance gap. A lightweight fine-tune using only 1k traces still improves performance by over 30\% in Swahili. Third, data quality versus scale trade-offs are language dependent: small, carefully curated datasets suffice for English and French, whereas larger but noisier corpora prove more effective for Swahili and Latvian. Together, these results clarify when and why long CoTs transfer across languages and provide translated datasets to foster equitable multilingual reasoning research.
Learning Adaptive Parallel Reasoning with Language Models
Apr 21, 2025Scaling inference-time computation has substantially improved the reasoning capabilities of language models. However, existing methods have significant limitations: serialized chain-of-thought approaches generate overly long outputs, leading to increased latency and exhausted context windows, while parallel methods such as self-consistency suffer from insufficient coordination, resulting in redundant computations and limited performance gains. To address these shortcomings, we propose Adaptive Parallel Reasoning (APR), a novel reasoning framework that enables language models to orchestrate both serialized and parallel computations end-to-end. APR generalizes existing reasoning methods by enabling adaptive multi-threaded inference using spawn() and join() operations. A key innovation is our end-to-end reinforcement learning strategy, optimizing both parent and child inference threads to enhance task success rate without requiring predefined reasoning structures. Experiments on the Countdown reasoning task demonstrate significant benefits of APR: (1) higher performance within the same context window (83.4% vs. 60.0% at 4k context); (2) superior scalability with increased computation (80.1% vs. 66.6% at 20k total tokens); (3) improved accuracy at equivalent latency (75.2% vs. 57.3% at approximately 5,000ms). APR represents a step towards enabling language models to autonomously optimize their reasoning processes through adaptive allocation of computation.
TULIP: Towards Unified Language-Image Pretraining
Mar 19, 2025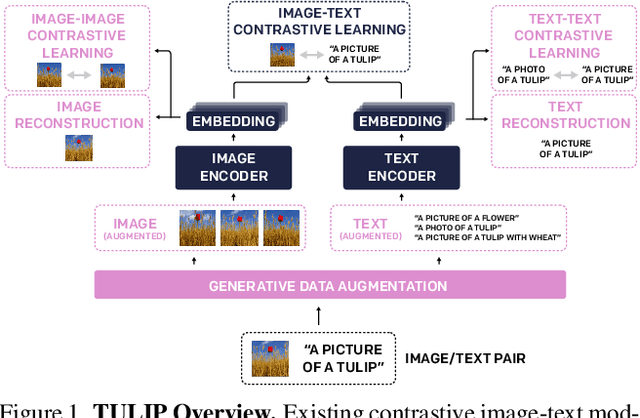
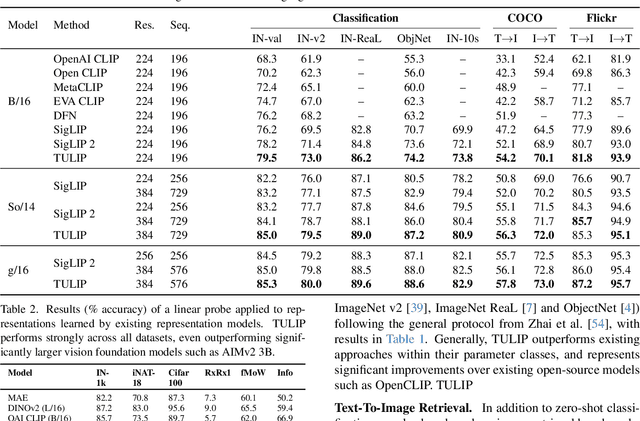
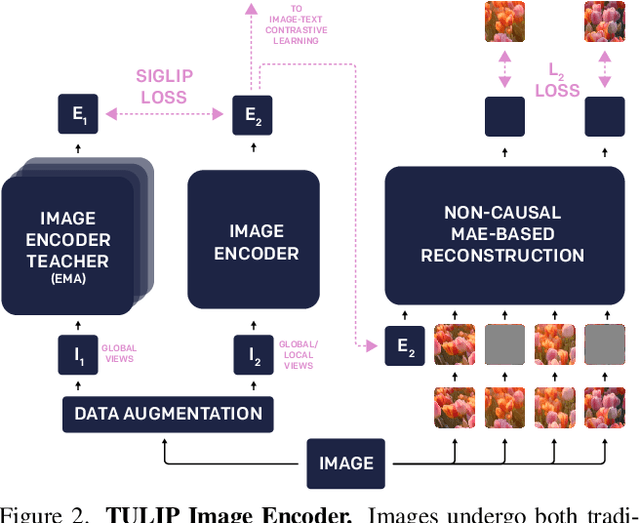
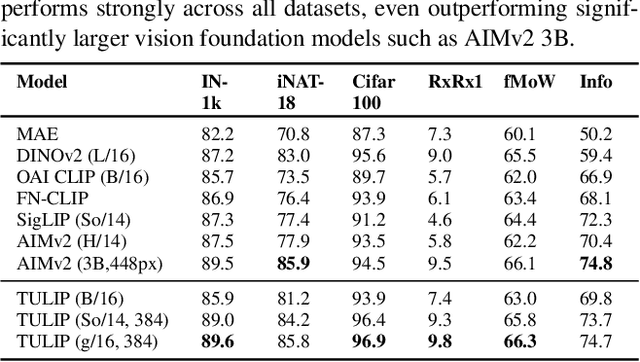
Despite the recent success of image-text contrastive models like CLIP and SigLIP, these models often struggle with vision-centric tasks that demand high-fidelity image understanding, such as counting, depth estimation, and fine-grained object recognition. These models, by performing language alignment, tend to prioritize high-level semantics over visual understanding, weakening their image understanding. On the other hand, vision-focused models are great at processing visual information but struggle to understand language, limiting their flexibility for language-driven tasks. In this work, we introduce TULIP, an open-source, drop-in replacement for existing CLIP-like models. Our method leverages generative data augmentation, enhanced image-image and text-text contrastive learning, and image/text reconstruction regularization to learn fine-grained visual features while preserving global semantic alignment. Our approach, scaling to over 1B parameters, outperforms existing state-of-the-art (SOTA) models across multiple benchmarks, establishing a new SOTA zero-shot performance on ImageNet-1K, delivering up to a $2\times$ enhancement over SigLIP on RxRx1 in linear probing for few-shot classification, and improving vision-language models, achieving over $3\times$ higher scores than SigLIP on MMVP. Our code/checkpoints are available at https://tulip-berkeley.github.io
AutoPresent: Designing Structured Visuals from Scratch
Jan 01, 2025
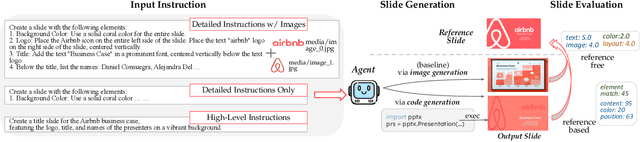
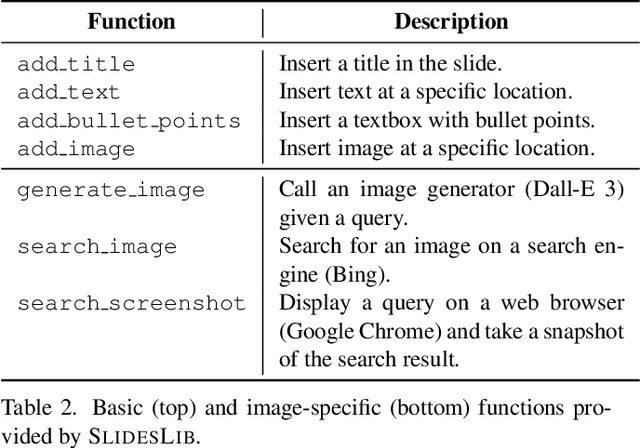
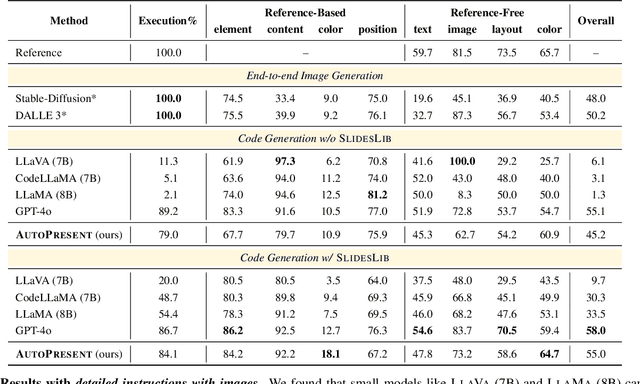
Designing structured visuals such as presentation slides is essential for communicative needs, necessitating both content creation and visual planning skills. In this work, we tackle the challenge of automated slide generation, where models produce slide presentations from natural language (NL) instructions. We first introduce the SlidesBench benchmark, the first benchmark for slide generation with 7k training and 585 testing examples derived from 310 slide decks across 10 domains. SlidesBench supports evaluations that are (i)reference-based to measure similarity to a target slide, and (ii)reference-free to measure the design quality of generated slides alone. We benchmark end-to-end image generation and program generation methods with a variety of models, and find that programmatic methods produce higher-quality slides in user-interactable formats. Built on the success of program generation, we create AutoPresent, an 8B Llama-based model trained on 7k pairs of instructions paired with code for slide generation, and achieve results comparable to the closed-source model GPT-4o. We further explore iterative design refinement where the model is tasked to self-refine its own output, and we found that this process improves the slide's quality. We hope that our work will provide a basis for future work on generating structured visuals.
Training Software Engineering Agents and Verifiers with SWE-Gym
Dec 30, 2024



We present SWE-Gym, the first environment for training real-world software engineering (SWE) agents. SWE-Gym contains 2,438 real-world Python task instances, each comprising a codebase with an executable runtime environment, unit tests, and a task specified in natural language. We use SWE-Gym to train language model based SWE agents , achieving up to 19% absolute gains in resolve rate on the popular SWE-Bench Verified and Lite test sets. We also experiment with inference-time scaling through verifiers trained on agent trajectories sampled from SWE-Gym. When combined with our fine-tuned SWE agents, we achieve 32.0% and 26.0% on SWE-Bench Verified and Lite, respectively, reflecting a new state-of-the-art for open-weight SWE agents. To facilitate further research, we publicly release SWE-Gym, models, and agent trajectories.
Evaluating Model Perception of Color Illusions in Photorealistic Scenes
Dec 09, 2024



We study the perception of color illusions by vision-language models. Color illusion, where a person's visual system perceives color differently from actual color, is well-studied in human vision. However, it remains underexplored whether vision-language models (VLMs), trained on large-scale human data, exhibit similar perceptual biases when confronted with such color illusions. We propose an automated framework for generating color illusion images, resulting in RCID (Realistic Color Illusion Dataset), a dataset of 19,000 realistic illusion images. Our experiments show that all studied VLMs exhibit perceptual biases similar human vision. Finally, we train a model to distinguish both human perception and actual pixel differences.