 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Chain-of-Thought Reasoning Across Languages
Aug 20, 2025

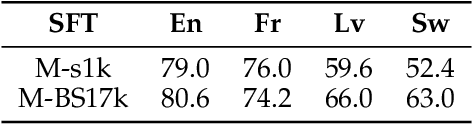

Scaling inference through long chains-of-thought (CoTs) has unlocked impressive reasoning capabilities in large language models (LLMs), yet the reasoning process remains almost exclusively English-centric. We construct translated versions of two popular English reasoning datasets, fine-tune Qwen 2.5 (7B) and Qwen 3 (8B) models, and present a systematic study of long CoT generation across French, Japanese, Latvian, and Swahili. Our experiments reveal three key findings. First, the efficacy of using English as a pivot language varies by language: it provides no benefit for French, improves performance when used as the reasoning language for Japanese and Latvian, and proves insufficient for Swahili where both task comprehension and reasoning remain poor. Second, extensive multilingual pretraining in Qwen 3 narrows but does not eliminate the cross-lingual performance gap. A lightweight fine-tune using only 1k traces still improves performance by over 30\% in Swahili. Third, data quality versus scale trade-offs are language dependent: small, carefully curated datasets suffice for English and French, whereas larger but noisier corpora prove more effective for Swahili and Latvian. Together, these results clarify when and why long CoTs transfer across languages and provide translated datasets to foster equitable multilingual reasoning research.
Using Language Models to Disambiguate Lexical Choices in Translation
Nov 08, 2024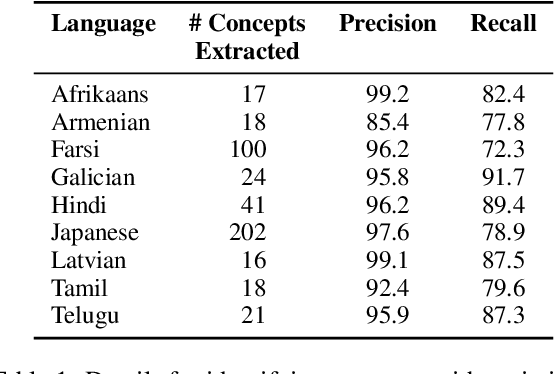
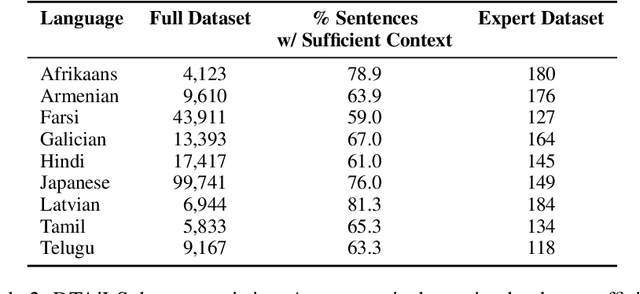
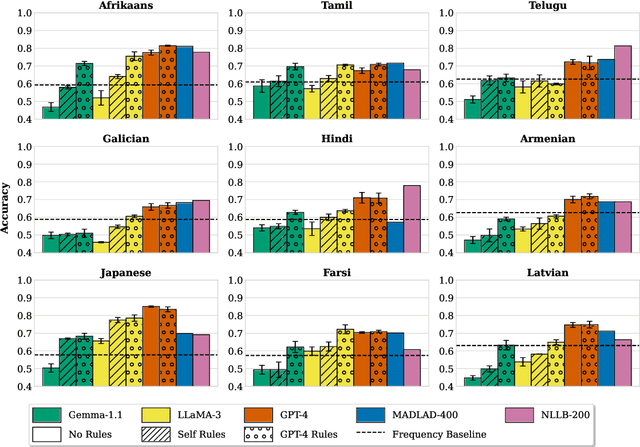
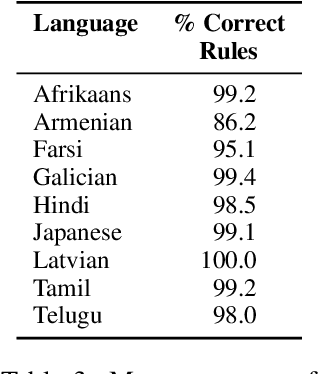
In translation, a concept represented by a single word in a source language can have multiple variations in a target language. The task of lexical selection requires using context to identify which variation is most appropriate for a source text. We work with native speakers of nine languages to create DTAiLS, a dataset of 1,377 sentence pairs that exhibit cross-lingual concept variation when translating from English. We evaluate recent LLMs and neural machine translation systems on DTAiLS, with the best-performing model, GPT-4, achieving from 67 to 85% accuracy across languages. Finally, we use language models to generate English rules describing target-language concept variations. Providing weaker models with high-quality lexical rules improves accuracy substantially, in some cases reaching or outperforming GPT-4.
Bidirectional Captioning for Clinically Accurate and Interpretable Models
Oct 30, 2023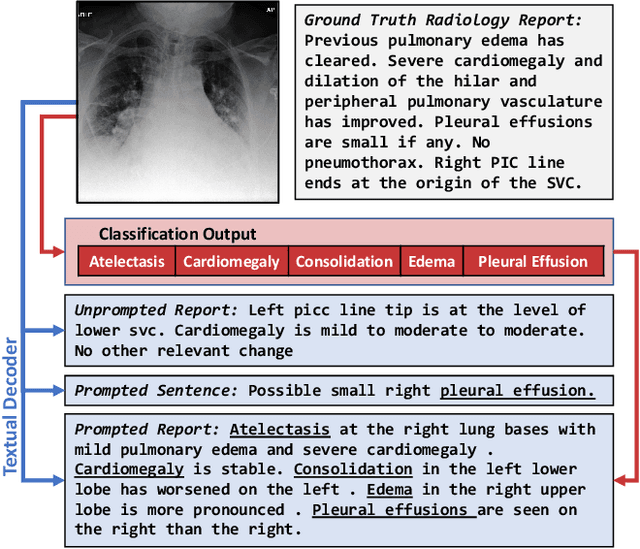
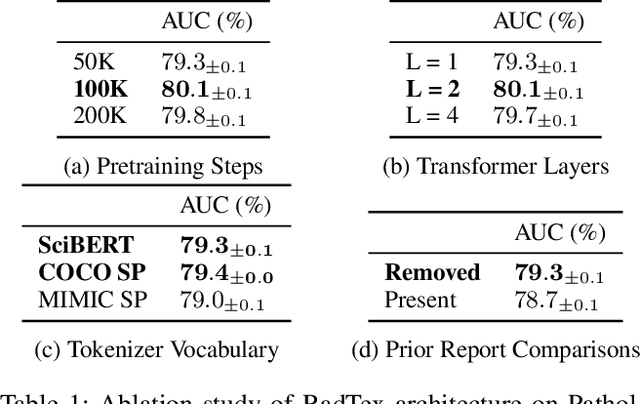
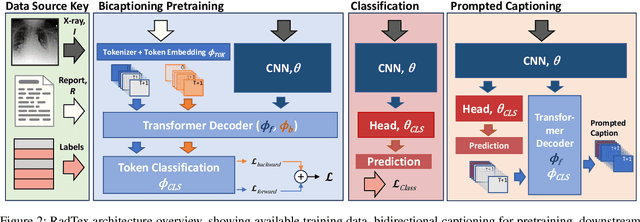
Vision-language pretraining has been shown to produce high-quality visual encoders which transfer efficiently to downstream computer vision tasks. While generative language models have gained widespread attention, image captioning has thus far been mostly overlooked as a form of cross-modal pretraining in favor of contrastive learning, especially in medical image analysis. In this paper, we experiment with bidirectional captioning of radiology reports as a form of pretraining and compare the quality and utility of learned embeddings with those from contrastive pretraining methods. We optimize a CNN encoder, transformer decoder architecture named RadTex for the radiology domain. Results show that not only does captioning pretraining yield visual encoders that are competitive with contrastive pretraining (CheXpert competition multi-label AUC of 89.4%), but also that our transformer decoder is capable of generating clinically relevant reports (captioning macro-F1 score of 0.349 using CheXpert labeler) and responding to prompts with targeted, interactive outputs.