 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Captioning for Clinically Accurate and Interpretable Models
Paper and Code
Oct 30, 2023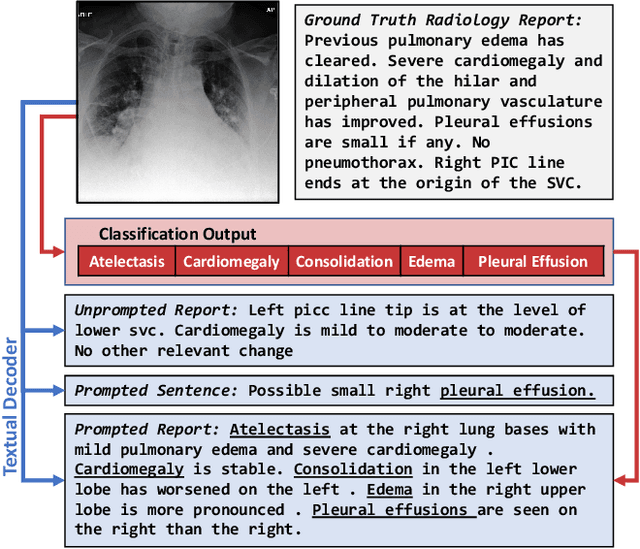
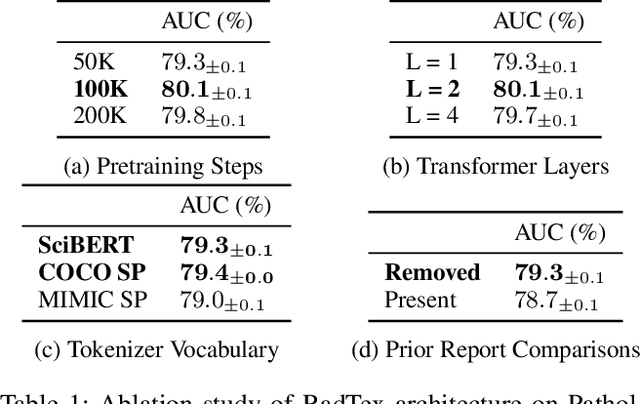
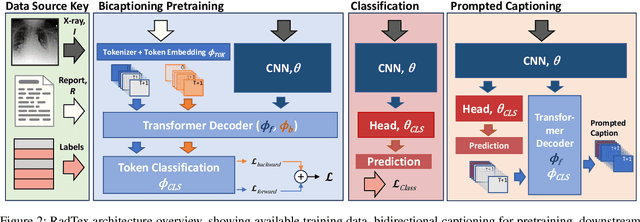
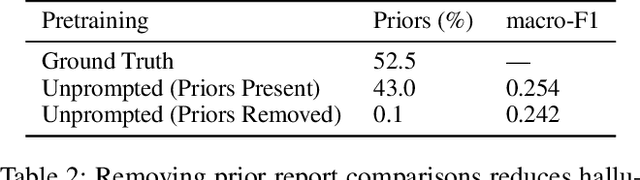
Vision-language pretraining has been shown to produce high-quality visual encoders which transfer efficiently to downstream computer vision tasks. While generative language models have gained widespread attention, image captioning has thus far been mostly overlooked as a form of cross-modal pretraining in favor of contrastive learning, especially in medical image analysis. In this paper, we experiment with bidirectional captioning of radiology reports as a form of pretraining and compare the quality and utility of learned embeddings with those from contrastive pretraining methods. We optimize a CNN encoder, transformer decoder architecture named RadTex for the radiology domain. Results show that not only does captioning pretraining yield visual encoders that are competitive with contrastive pretraining (CheXpert competition multi-label AUC of 89.4%), but also that our transformer decoder is capable of generating clinically relevant reports (captioning macro-F1 score of 0.349 using CheXpert labeler) and responding to prompts with targeted, interactive outputs.