 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Equivariant Neural Networks for Charge Density Prediction in Materials
Dec 08, 2023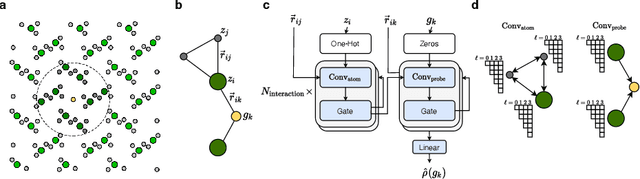

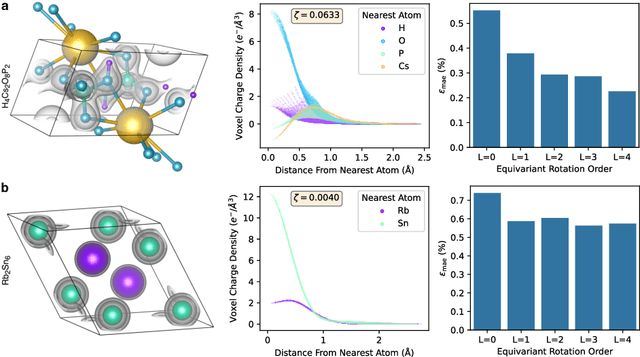
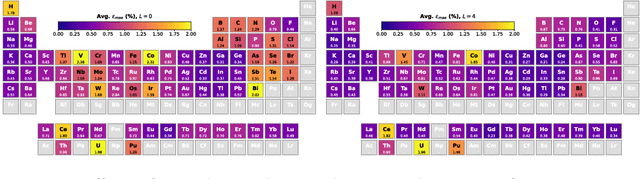
The calculation of electron density distribution using density functional theory (DFT) in materials and molecules is central to the study of their quantum and macro-scale properties, yet accurate and efficient calculation remains a long-standing challenge in the field of material science. This work introduces ChargE3Net, an E(3)-equivariant graph neural network for predicting electron density in atomic systems. ChargE3Net achieves equivariance through the use of higher-order tensor representations, and directly predicts the charge density at any arbitrary point in the system. We show that our method achieves greater performance than prior work on large and diverse sets of molecules and materials, and scales to larger systems than what is feasible to compute with DFT. Using predicted electron densities as an initialization, we show that fewer self-consistent iterations are required to converge DFT over the default initialization. In addition, we show that non-self-consistent calculations using the predicted electron densities can predict electronic and thermodynamic properties of materials at near-DFT accuracy.
Bidirectional Captioning for Clinically Accurate and Interpretable Models
Oct 30, 2023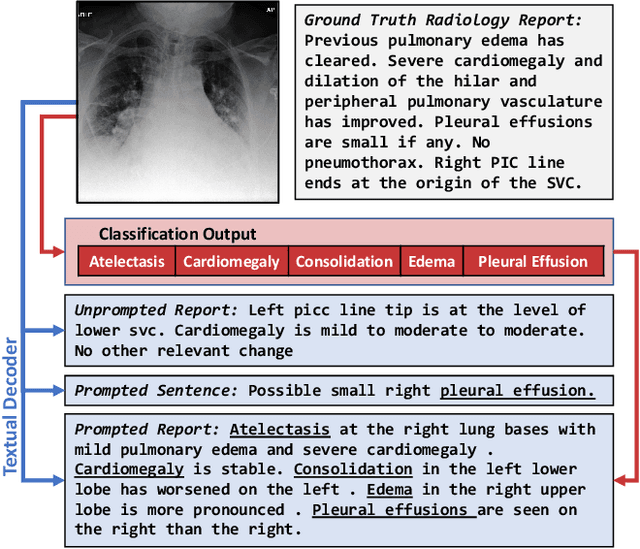
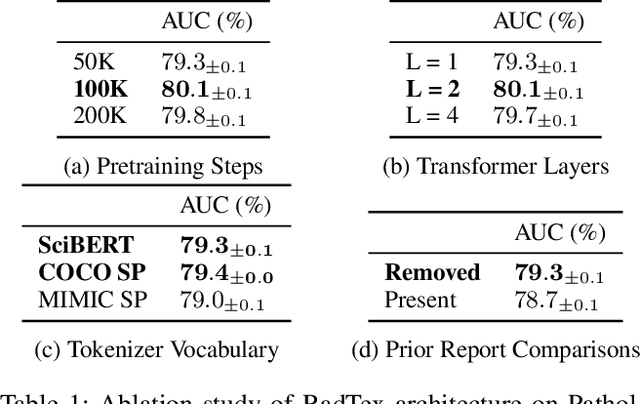
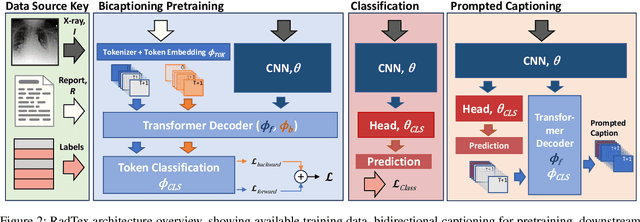
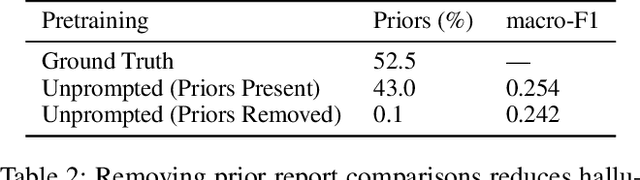
Vision-language pretraining has been shown to produce high-quality visual encoders which transfer efficiently to downstream computer vision tasks. While generative language models have gained widespread attention, image captioning has thus far been mostly overlooked as a form of cross-modal pretraining in favor of contrastive learning, especially in medical image analysis. In this paper, we experiment with bidirectional captioning of radiology reports as a form of pretraining and compare the quality and utility of learned embeddings with those from contrastive pretraining methods. We optimize a CNN encoder, transformer decoder architecture named RadTex for the radiology domain. Results show that not only does captioning pretraining yield visual encoders that are competitive with contrastive pretraining (CheXpert competition multi-label AUC of 89.4%), but also that our transformer decoder is capable of generating clinically relevant reports (captioning macro-F1 score of 0.349 using CheXpert labeler) and responding to prompts with targeted, interactive outputs.
Graph Contrastive Learning for Materials
Nov 24, 2022


Recent work has shown the potential of graph neural networks to efficiently predict material properties, enabling high-throughput screening of materials. Training these models, however, often requires large quantities of labelled data, obtained via costly methods such as ab initio calculations or experimental evaluation. By leveraging a series of material-specific transformations, we introduce CrystalCLR, a framework for constrastive learning of representations with crystal graph neural networks. With the addition of a novel loss function, our framework is able to learn representations competitive with engineered fingerprinting methods. We also demonstrate that via model finetuning, contrastive pretraining can improve the performance of graph neural networks for prediction of material properties and significantly outperform traditional ML models that use engineered fingerprints. Lastly, we observe that CrystalCLR produces material representations that form clusters by compound class.
Developing Modular Autonomous Capabilities for sUAS Operations
Nov 01, 2022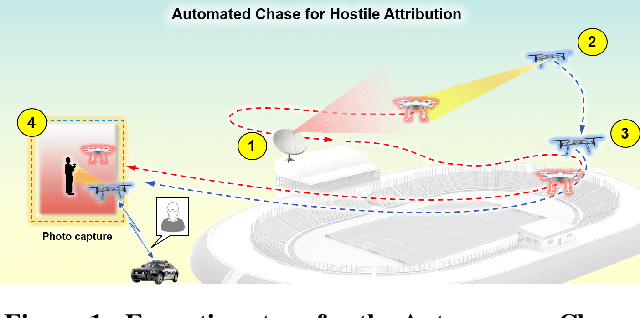
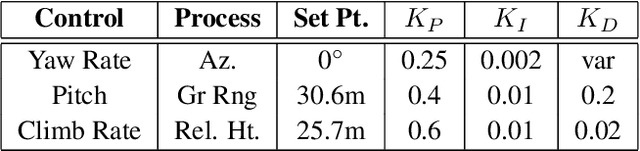

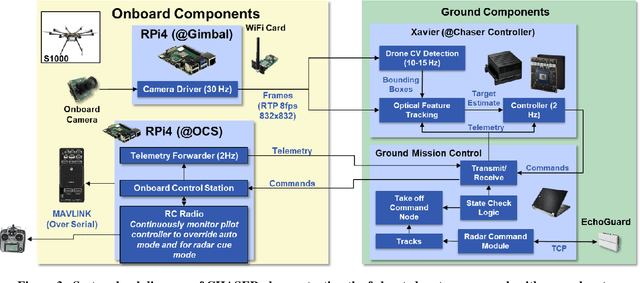
Small teams in the field can benefit from the capabilities provided by small Uncrewed Aerial Systems (sUAS) for missions such as reconnaissance, hostile attribution, remote emplacement, and search and rescue. The mobility, communications, and flexible payload capacity of sUAS can offer teams new levels of situational awareness and enable more highly coordinated missions than previously possible. However, piloting such aircraft for specific missions draws personnel away from other mission-critical tasks, increasing the load on remaining personnel while also increasing complexity of operations. For wider adoption and use of sUAS for security and humanitarian missions, safe and robust autonomy must be employed to reduce this burden on small teams. In this paper, we present the development of the Collaborative-UAS for Hostile Attribution, Surveillance, Emplacement, and Reconnaissance (CHASER) testbed, for rapidly prototyping capabilities that will reduce strain on small teams through sensor-guided autonomous control. We attempt to address autonomy needs unfilled by commercial sUAS platforms by creating and testing a series of composable modules that can be configured to support multiple missions. Methods implemented and presented here include radar track correlation, on-board computer vision target detection, target position estimation, closed-loop relative position control, and efficient search of a 3D volume for target acquisition. We configure and test a series of these modules in an example mission, executing a fully autonomous chase of an intruding sUAS in live flight, and demonstrating the success of the modularized autonomy approach. We present performance results from simulation or live flight tests for each module. Lastly, we describe the software architecture that we have developed for flexible controls and comment on how the capabilities presented may enable additional missions.
RadTex: Learning Efficient Radiograph Representations from Text Reports
Aug 05, 2022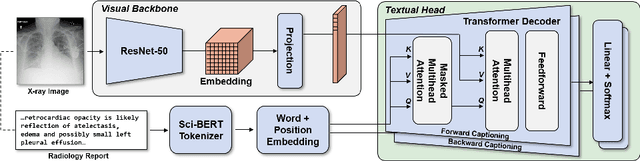
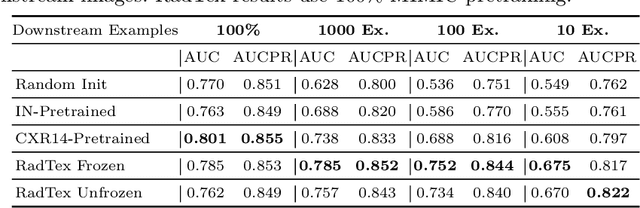
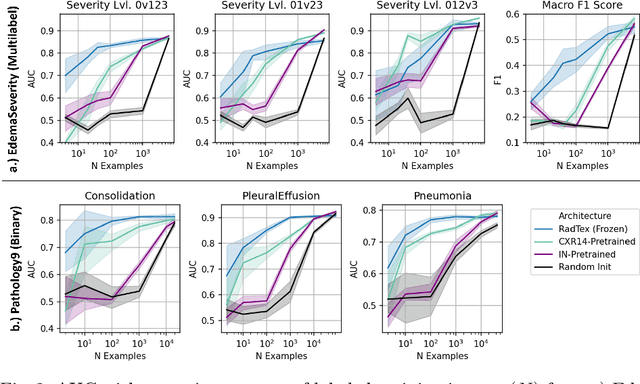
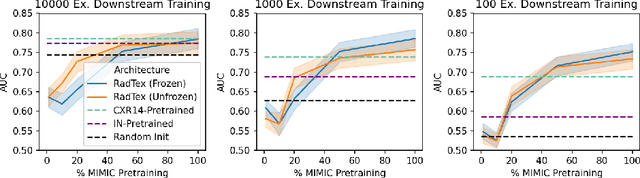
Automated analysis of chest radiography using deep learning has tremendous potential to enhance the clinical diagnosis of diseases in patients. However, deep learning models typically require large amounts of annotated data to achieve high performance -- often an obstacle to medical domain adaptation. In this paper, we build a data-efficient learning framework that utilizes radiology reports to improve medical image classification performance with limited labeled data (fewer than 1000 examples). Specifically, we examine image-captioning pretraining to learn high-quality medical image representations that train on fewer examples. Following joint pretraining of a convolutional encoder and transformer decoder, we transfer the learned encoder to various classification tasks. Averaged over 9 pathologies, we find that our model achieves higher classification performance than ImageNet-supervised and in-domain supervised pretraining when labeled training data is limited.
Multimodal Representation Learning via Maximization of Local Mutual Information
Mar 08, 2021
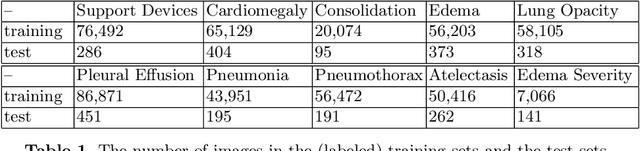
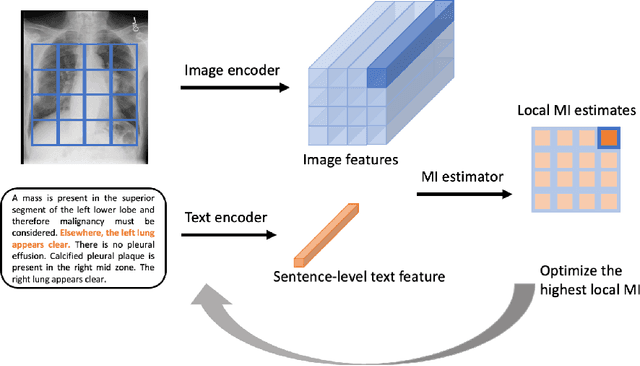
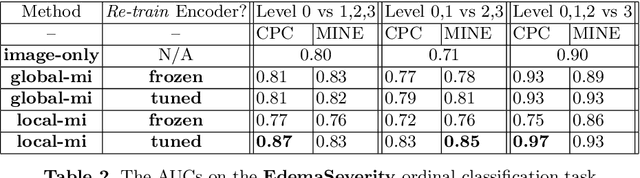
We propose and demonstrate a representation learning approach by maximizing the mutual information between local features of images and text. The goal of this approach is to learn useful image representations by taking advantage of the rich information contained in the free text that describes the findings in the image. Our method learns image and text encoders by encouraging the resulting representations to exhibit high local mutual information. We make use of recent advances in mutual information estimation with neural network discriminators. We argue that, typically, the sum of local mutual information is a lower bound on the global mutual information. Our experimental results in the downstream image classification tasks demonstrate the advantages of using local features for image-text representation learning.