 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Fetal Anatomy with Kinematic Tree Log-Euclidean PolyRigid Transforms
Mar 02, 2026Automated analysis of articulated bodies is crucial in medical imaging. Existing surface-based models often ignore internal volumetric structures and rely on deformation methods that lack anatomical consistency guarantees. To address this problem, we introduce a differentiable volumetric body model based on the Skinned Multi-Person Linear (SMPL) formulation, driven by a new Kinematic Tree-based Log-Euclidean PolyRigid (KTPolyRigid) transform. KTPolyRigid resolves Lie algebra ambiguities associated with large, non-local articulated motions, and encourages smooth, bijective volumetric mappings. Evaluated on 53 fetal MRI volumes, KTPolyRigid yields deformation fields with significantly fewer folding artifacts. Furthermore, our framework enables robust groupwise image registration and a label-efficient, template-based segmentation of fetal organs. It provides a robust foundation for standardized volumetric analysis of articulated bodies in medical imaging.
Calibrating Expressions of Certainty
Oct 06, 2024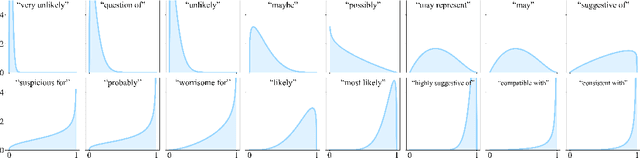
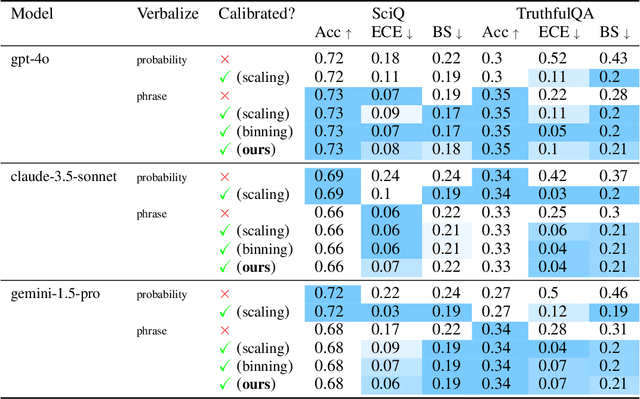
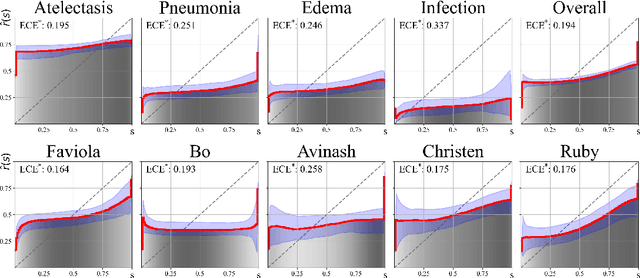
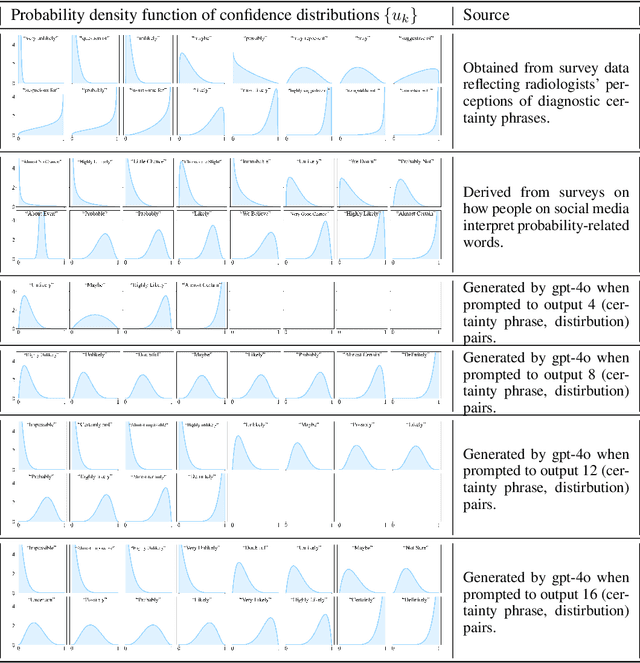
We present a novel approach to calibrating linguistic expressions of certainty, e.g., "Maybe" and "Likely". Unlike prior work that assigns a single score to each certainty phrase, we model uncertainty as distributions over the simplex to capture their semantics more accurately. To accommodate this new representation of certainty, we generalize existing measures of miscalibration and introduce a novel post-hoc calibration method. Leveraging these tools, we analyze the calibration of both humans (e.g., radiologists) and computational models (e.g., language models) and provide interpretable suggestions to improve their calibration.
Intraoperative Registration by Cross-Modal Inverse Neural Rendering
Sep 18, 2024We present in this paper a novel approach for 3D/2D intraoperative registration during neurosurgery via cross-modal inverse neural rendering. Our approach separates implicit neural representation into two components, handling anatomical structure preoperatively and appearance intraoperatively. This disentanglement is achieved by controlling a Neural Radiance Field's appearance with a multi-style hypernetwork. Once trained, the implicit neural representation serves as a differentiable rendering engine, which can be used to estimate the surgical camera pose by minimizing the dissimilarity between its rendered images and the target intraoperative image. We tested our method on retrospective patients' data from clinical cases, showing that our method outperforms state-of-the-art while meeting current clinical standards for registration. Code and additional resources can be found at https://maxfehrentz.github.io/style-ngp/.
Unified Brain MR-Ultrasound Synthesis using Multi-Modal Hierarchical Representations
Sep 19, 2023We introduce MHVAE, a deep hierarchical variational auto-encoder (VAE) that synthesizes missing images from various modalities. Extending multi-modal VAEs with a hierarchical latent structure, we introduce a probabilistic formulation for fusing multi-modal images in a common latent representation while having the flexibility to handle incomplete image sets as input. Moreover, adversarial learning is employed to generate sharper images. Extensive experiments are performed on the challenging problem of joint intra-operative ultrasound (iUS) and Magnetic Resonance (MR) synthesis. Our model outperformed multi-modal VAEs, conditional GANs, and the current state-of-the-art unified method (ResViT) for synthesizing missing images, demonstrating the advantage of using a hierarchical latent representation and a principled probabilistic fusion operation. Our code is publicly available \url{https://github.com/ReubenDo/MHVAE}.
Sample-Specific Debiasing for Better Image-Text Models
Apr 25, 2023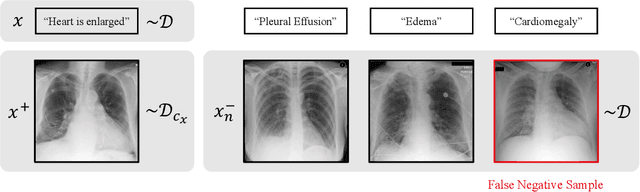
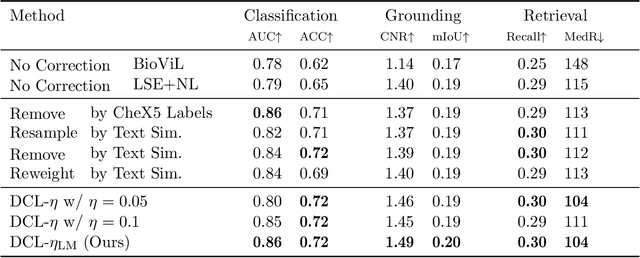
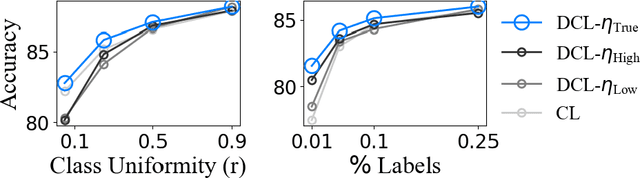

Self-supervised representation learning on image-text data facilitates crucial medical applications, such as image classification, visual grounding, and cross-modal retrieval. One common approach involves contrasting semantically similar (positive) and dissimilar (negative) pairs of data points. Drawing negative samples uniformly from the training data set introduces false negatives, i.e., samples that are treated as dissimilar but belong to the same class. In healthcare data, the underlying class distribution is nonuniform, implying that false negatives occur at a highly variable rate. To improve the quality of learned representations, we develop a novel approach that corrects for false negatives. Our method can be viewed as a variant of debiased constrastive learning that uses estimated sample-specific class probabilities. We provide theoretical analysis of the objective function and demonstrate the proposed approach on both image and paired image-text data sets. Our experiments demonstrate empirical advantages of sample-specific debiasing.
Deep Learning for Detection and Localization of B-Lines in Lung Ultrasound
Feb 15, 2023



Lung ultrasound (LUS) is an important imaging modality used by emergency physicians to assess pulmonary congestion at the patient bedside. B-line artifacts in LUS videos are key findings associated with pulmonary congestion. Not only can the interpretation of LUS be challenging for novice operators, but visual quantification of B-lines remains subject to observer variability. In this work, we investigate the strengths and weaknesses of multiple deep learning approaches for automated B-line detection and localization in LUS videos. We curate and publish, BEDLUS, a new ultrasound dataset comprising 1,419 videos from 113 patients with a total of 15,755 expert-annotated B-lines. Based on this dataset, we present a benchmark of established deep learning methods applied to the task of B-line detection. To pave the way for interpretable quantification of B-lines, we propose a novel "single-point" approach to B-line localization using only the point of origin. Our results show that (a) the area under the receiver operating characteristic curve ranges from 0.864 to 0.955 for the benchmarked detection methods, (b) within this range, the best performance is achieved by models that leverage multiple successive frames as input, and (c) the proposed single-point approach for B-line localization reaches an F1-score of 0.65, performing on par with the inter-observer agreement. The dataset and developed methods can facilitate further biomedical research on automated interpretation of lung ultrasound with the potential to expand the clinical utility.
Using Multiple Instance Learning to Build Multimodal Representations
Dec 11, 2022Image-text multimodal representation learning aligns data across modalities and enables important medical applications, e.g., image classification, visual grounding, and cross-modal retrieval. In this work, we establish a connection between multimodal representation learning and multiple instance learning. Based on this connection, we propose a generic framework for constructing permutation-invariant score functions with many existing multimodal representation learning approaches as special cases. Furthermore, we use the framework to derive a novel contrastive learning approach and demonstrate that our method achieves state-of-the-art results on a number of downstream tasks.
A Novel Supervised Contrastive Regression Framework for Prediction of Neurocognitive Measures Using Multi-Site Harmonized Diffusion MRI Tractography
Oct 13, 2022
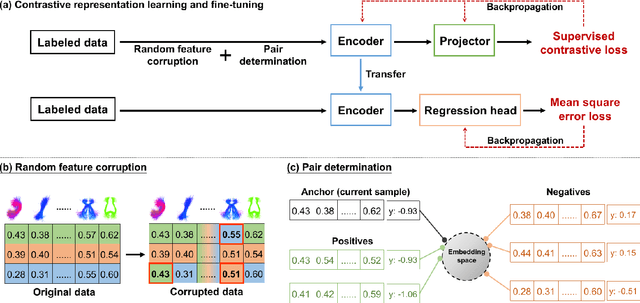
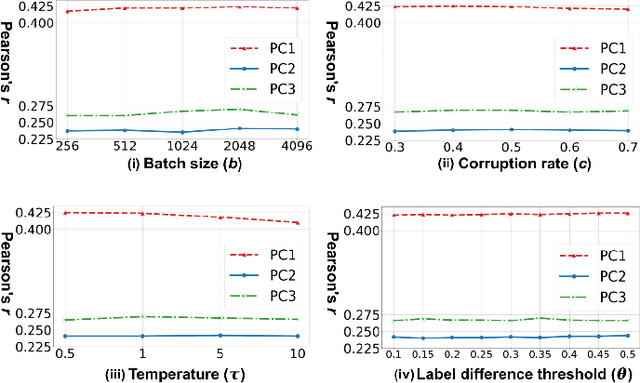
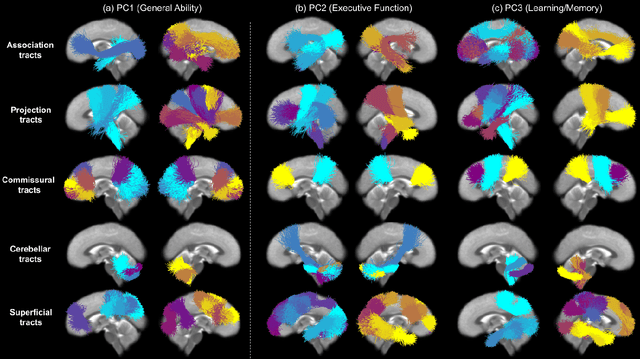
Neuroimaging-based prediction of neurocognitive measures is valuable for studying how the brain's structure relates to cognitive function. However, the accuracy of prediction using popular linear regression models is relatively low. We propose Supervised Contrastive Regression (SCR), a simple yet effective method that allows full supervision for contrastive learning in regression tasks. SCR performs supervised contrastive representation learning by using the absolute difference between continuous regression labels (i.e. neurocognitive scores) to determine positive and negative pairs. We apply SCR to analyze a large-scale dataset including multi-site harmonized diffusion MRI and neurocognitive data from 8735 participants in the Adolescent Brain Cognitive Development (ABCD) Study. We extract white matter microstructural measures using a fine parcellation of white matter tractography into fiber clusters. We predict three scores related to domains of higher-order cognition (general cognitive ability, executive function, and learning/memory). To identify important fiber clusters for prediction of these neurocognitive scores, we propose a permutation feature importance method for high-dimensional data. We find that SCR improves the accuracy of neurocognitive score prediction compared to other state-of-the-art methods. We find that the most predictive fiber clusters are predominantly located within the superficial white matter and projection tracts, particularly the superficial frontal white matter and striato-frontal connections. Overall, our results demonstrate the utility of contrastive representation learning methods for regression, and in particular for improving neuroimaging-based prediction of higher-order cognitive abilities.
SuperWarp: Supervised Learning and Warping on U-Net for Invariant Subvoxel-Precise Registration
May 15, 2022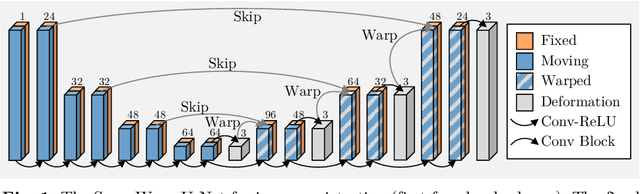

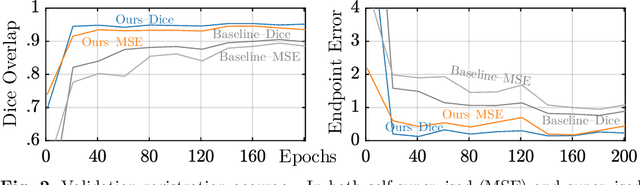

In recent years, learning-based image registration methods have gradually moved away from direct supervision with target warps to instead use self-supervision, with excellent results in several registration benchmarks. These approaches utilize a loss function that penalizes the intensity differences between the fixed and moving images, along with a suitable regularizer on the deformation. In this paper, we argue that the relative failure of supervised registration approaches can in part be blamed on the use of regular U-Nets, which are jointly tasked with feature extraction, feature matching, and estimation of deformation. We introduce one simple but crucial modification to the U-Net that disentangles feature extraction and matching from deformation prediction, allowing the U-Net to warp the features, across levels, as the deformation field is evolved. With this modification, direct supervision using target warps begins to outperform self-supervision approaches that require segmentations, presenting new directions for registration when images do not have segmentations. We hope that our findings in this preliminary workshop paper will re-ignite research interest in supervised image registration techniques. Our code is publicly available from https://github.com/balbasty/superwarp.
Equivariant Filters for Efficient Tracking in 3D Imaging
Mar 18, 2021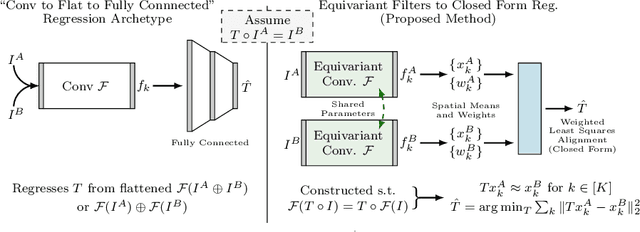

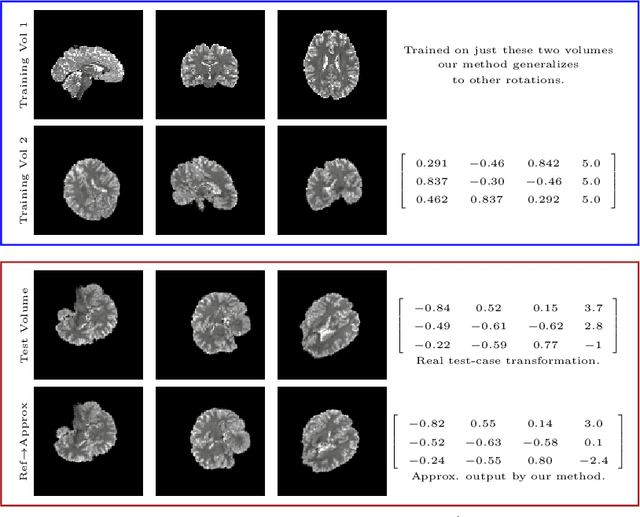
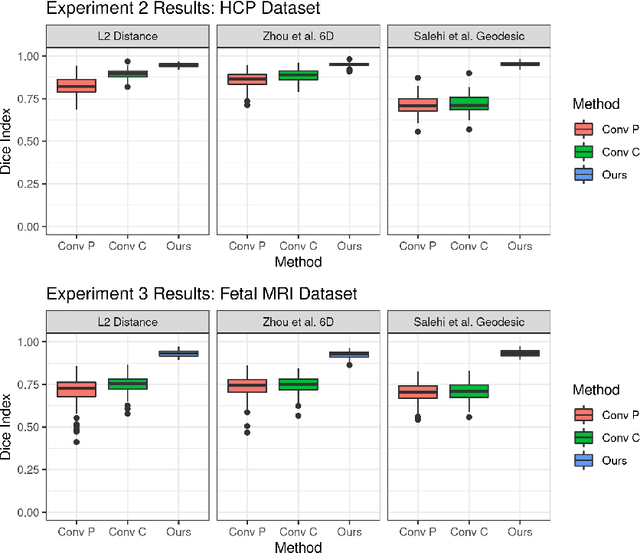
We demonstrate an object tracking method for {3D} images with fixed computational cost and state-of-the-art performance. Previous methods predicted transformation parameters from convolutional layers. We instead propose an architecture that does not include either flattening of convolutional features or fully connected layers, but instead relies on equivariant filters to preserve transformations between inputs and outputs (e.g. rot./trans. of inputs rotate/translate outputs). The transformation is then derived in closed form from the outputs of the filters. This method is useful for applications requiring low latency, such as real-time tracking. We demonstrate our model on synthetically augmented adult brain MRI, as well as fetal brain MRI, which is the intended use-case.