 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Gaussian NeRF for Wide Field-of-View Ultrasound Reconstruction
Apr 27, 2026Wide Field-of-View (WFoV) reconstruction enhances 3D ultrasound imaging by providing valuable anatomical context for segmentation models and visualization. Clinical ultrasound volumes are predominantly acquired using convex probes, which generate expanding, diverging acoustic beams to maximize anatomical coverage. Stitching these sweeps together traditionally introduces significant compounding artifacts and aliasing due to depth-dependent resolution changes. Here, we introduce Ultra-Wide-NeRF, a Multivariate 3D Gaussian (MVG) NeRF-based method for WFoV ultrasound reconstruction. By explicitly modeling the complex beam geometry using distance-dependent convex volumetric sampling and anisotropic 3D Gaussians, our method inherently mitigates these compounding artifacts and provides anti-aliasing. Beyond simply reconstructing a static 3D grid, our NeRF-based approach yields a continuous neural representation of the tissue, enabling the synthesis of high-fidelity novel views from arbitrary virtual trajectories. We validate Ultra-Wide-NeRF for intracardiac echocardiography on phantom and porcine datasets, demonstrating that our method expands the spatial context important in intraoperative navigation. Code will be open-sourced upon publication.
UltraG-Ray: Physics-Based Gaussian Ray Casting for Novel Ultrasound View Synthesis
Mar 30, 2026Novel view synthesis (NVS) in ultrasound has gained attention as a technique for generating anatomically plausible views beyond the acquired frames, offering new capabilities for training clinicians or data augmentation. However, current methods struggle with complex tissue and view-dependent acoustic effects. Physics-based NVS aims to address these limitations by including the ultrasound image formation process into the simulation. Recent approaches combine a learnable implicit scene representation with an ultrasound-specific rendering module, yet a substantial gap between simulation and reality remains. In this work, we introduce UltraG-Ray, a novel ultrasound scene representation based on a learnable 3D Gaussian field, coupled to an efficient physics-based module for B-mode synthesis. We explicitly encode ultrasound-specific parameters, such as attenuation and reflection, into a Gaussian-based spatial representation and realize image synthesis within a novel ray casting scheme. In contrast to previous methods, this approach naturally captures view-dependent attenuation effects, thereby enabling the generation of physically informed B-mode images with increased realism. We compare our method to state-of-the-art and observe consistent gains in image quality metrics (up to 15% increase on MS-SSIM), demonstrating clear improvement in terms of realism of the synthesized ultrasound images.
OSCAR: Occupancy-based Shape Completion via Acoustic Neural Implicit Representations
Mar 09, 2026Accurate 3D reconstruction of vertebral anatomy from ultrasound is important for guiding minimally invasive spine interventions, but it remains challenging due to acoustic shadowing and view-dependent signal variations. We propose an occupancy-based shape completion method that reconstructs complete 3D anatomical geometry from partial ultrasound observations. Crucially for intra-operative applications, our approach extracts the anatomical surface directly from the image, avoiding the need for anatomical labels during inference. This label-free completion relies on a coupled latent space representing both the image appearance and the underlying anatomical shape. By leveraging a Neural Implicit Representation (NIR) that jointly models both spatial occupancy and acoustic interactions, the method uses acoustic parameters to become implicitly aware of the unseen regions without explicit shadowing labels through tracking acoustic signal transmission. We show that this method outperforms state-of-the-art shape completion for B-mode ultrasound by 80% in HD95 score. We validate our approach both in-silico and on phantom US images with registered mesh models from CT labels, demonstrating accurate reconstruction of occluded anatomy and robust generalization across diverse imaging conditions. Code and data will be released on publication.
US-X Complete: A Multi-Modal Approach to Anatomical 3D Shape Recovery
Nov 19, 2025Ultrasound offers a radiation-free, cost-effective solution for real-time visualization of spinal landmarks, paraspinal soft tissues and neurovascular structures, making it valuable for intraoperative guidance during spinal procedures. However, ultrasound suffers from inherent limitations in visualizing complete vertebral anatomy, in particular vertebral bodies, due to acoustic shadowing effects caused by bone. In this work, we present a novel multi-modal deep learning method for completing occluded anatomical structures in 3D ultrasound by leveraging complementary information from a single X-ray image. To enable training, we generate paired training data consisting of: (1) 2D lateral vertebral views that simulate X-ray scans, and (2) 3D partial vertebrae representations that mimic the limited visibility and occlusions encountered during ultrasound spine imaging. Our method integrates morphological information from both imaging modalities and demonstrates significant improvements in vertebral reconstruction (p < 0.001) compared to state of art in 3D ultrasound vertebral completion. We perform phantom studies as an initial step to future clinical translation, and achieve a more accurate, complete volumetric lumbar spine visualization overlayed on the ultrasound scan without the need for registration with preoperative modalities such as computed tomography. This demonstrates that integrating a single X-ray projection mitigates ultrasound's key limitation while preserving its strengths as the primary imaging modality. Code and data can be found at https://github.com/miruna20/US-X-Complete
UltrON: Ultrasound Occupancy Networks
Sep 10, 2025In free-hand ultrasound imaging, sonographers rely on expertise to mentally integrate partial 2D views into 3D anatomical shapes. Shape reconstruction can assist clinicians in this process. Central to this task is the choice of shape representation, as it determines how accurately and efficiently the structure can be visualized, analyzed, and interpreted. Implicit representations, such as SDF and occupancy function, offer a powerful alternative to traditional voxel- or mesh-based methods by modeling continuous, smooth surfaces with compact storage, avoiding explicit discretization. Recent studies demonstrate that SDF can be effectively optimized using annotations derived from segmented B-mode ultrasound images. Yet, these approaches hinge on precise annotations, overlooking the rich acoustic information embedded in B-mode intensity. Moreover, implicit representation approaches struggle with the ultrasound's view-dependent nature and acoustic shadowing artifacts, which impair reconstruction. To address the problems resulting from occlusions and annotation dependency, we propose an occupancy-based representation and introduce \gls{UltrON} that leverages acoustic features to improve geometric consistency in weakly-supervised optimization regime. We show that these features can be obtained from B-mode images without additional annotation cost. Moreover, we propose a novel loss function that compensates for view-dependency in the B-mode images and facilitates occupancy optimization from multiview ultrasound. By incorporating acoustic properties, \gls{UltrON} generalizes to shapes of the same anatomy. We show that \gls{UltrON} mitigates the limitations of occlusions and sparse labeling and paves the way for more accurate 3D reconstruction. Code and dataset will be available at https://github.com/magdalena-wysocki/ultron.
Shape Completion and Real-Time Visualization in Robotic Ultrasound Spine Acquisitions
Aug 12, 2025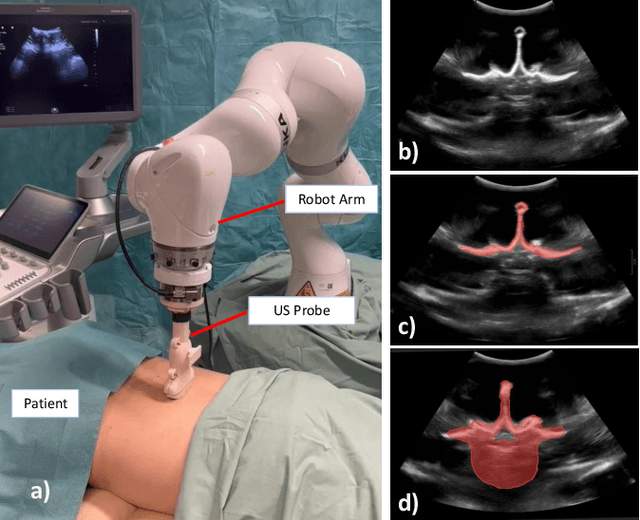
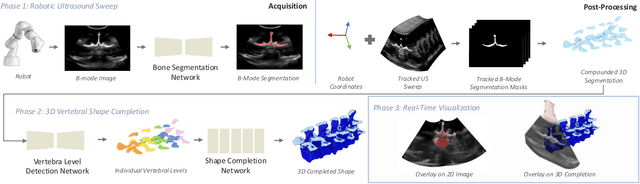
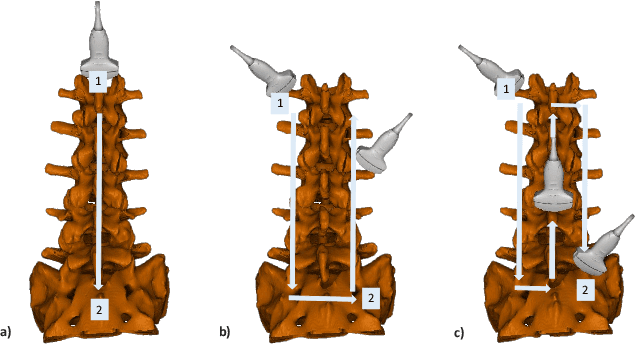
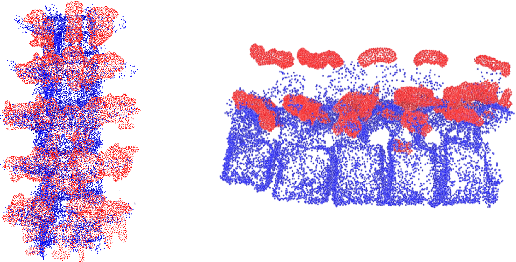
Ultrasound (US) imaging is increasingly used in spinal procedures due to its real-time, radiation-free capabilities; however, its effectiveness is hindered by shadowing artifacts that obscure deeper tissue structures. Traditional approaches, such as CT-to-US registration, incorporate anatomical information from preoperative CT scans to guide interventions, but they are limited by complex registration requirements, differences in spine curvature, and the need for recent CT imaging. Recent shape completion methods can offer an alternative by reconstructing spinal structures in US data, while being pretrained on large set of publicly available CT scans. However, these approaches are typically offline and have limited reproducibility. In this work, we introduce a novel integrated system that combines robotic ultrasound with real-time shape completion to enhance spinal visualization. Our robotic platform autonomously acquires US sweeps of the lumbar spine, extracts vertebral surfaces from ultrasound, and reconstructs the complete anatomy using a deep learning-based shape completion network. This framework provides interactive, real-time visualization with the capability to autonomously repeat scans and can enable navigation to target locations. This can contribute to better consistency, reproducibility, and understanding of the underlying anatomy. We validate our approach through quantitative experiments assessing shape completion accuracy and evaluations of multiple spine acquisition protocols on a phantom setup. Additionally, we present qualitative results of the visualization on a volunteer scan.
HyperSORT: Self-Organising Robust Training with hyper-networks
Jun 26, 2025Medical imaging datasets often contain heterogeneous biases ranging from erroneous labels to inconsistent labeling styles. Such biases can negatively impact deep segmentation networks performance. Yet, the identification and characterization of such biases is a particularly tedious and challenging task. In this paper, we introduce HyperSORT, a framework using a hyper-network predicting UNets' parameters from latent vectors representing both the image and annotation variability. The hyper-network parameters and the latent vector collection corresponding to each data sample from the training set are jointly learned. Hence, instead of optimizing a single neural network to fit a dataset, HyperSORT learns a complex distribution of UNet parameters where low density areas can capture noise-specific patterns while larger modes robustly segment organs in differentiated but meaningful manners. We validate our method on two 3D abdominal CT public datasets: first a synthetically perturbed version of the AMOS dataset, and TotalSegmentator, a large scale dataset containing real unknown biases and errors. Our experiments show that HyperSORT creates a structured mapping of the dataset allowing the identification of relevant systematic biases and erroneous samples. Latent space clusters yield UNet parameters performing the segmentation task in accordance with the underlying learned systematic bias. The code and our analysis of the TotalSegmentator dataset are made available: https://github.com/ImFusionGmbH/HyperSORT
Skelite: Compact Neural Networks for Efficient Iterative Skeletonization
Mar 10, 2025



Skeletonization extracts thin representations from images that compactly encode their geometry and topology. These representations have become an important topological prior for preserving connectivity in curvilinear structures, aiding medical tasks like vessel segmentation. Existing compatible skeletonization algorithms face significant trade-offs: morphology-based approaches are computationally efficient but prone to frequent breakages, while topology-preserving methods require substantial computational resources. We propose a novel framework for training iterative skeletonization algorithms with a learnable component. The framework leverages synthetic data, task-specific augmentation, and a model distillation strategy to learn compact neural networks that produce thin, connected skeletons with a fully differentiable iterative algorithm. Our method demonstrates a 100 times speedup over topology-constrained algorithms while maintaining high accuracy and generalizing effectively to new domains without fine-tuning. Benchmarking and downstream validation in 2D and 3D tasks demonstrate its computational efficiency and real-world applicability
UltraRay: Full-Path Ray Tracing for Enhancing Realism in Ultrasound Simulation
Jan 10, 2025



Traditional ultrasound simulators solve the wave equation to model pressure distribution fields, achieving high accuracy but requiring significant computational time and resources. To address this, ray tracing approaches have been introduced, modeling wave propagation as rays interacting with boundaries and scatterers. However, existing models simplify ray propagation, generating echoes at interaction points without considering return paths to the sensor. This can result in unrealistic artifacts and necessitates careful scene tuning for plausible results. We propose a novel ultrasound simulation pipeline that utilizes a ray tracing algorithm to generate echo data, tracing each ray from the transducer through the scene and back to the sensor. To replicate advanced ultrasound imaging, we introduce a ray emission scheme optimized for plane wave imaging, incorporating delay and steering capabilities. Furthermore, we integrate a standard signal processing pipeline to simulate end-to-end ultrasound image formation. We showcase the efficacy of the proposed pipeline by modeling synthetic scenes featuring highly reflective objects, such as bones. In doing so, our proposed approach, UltraRay, not only enhances the overall visual quality but also improves the realism of the simulated images by accurately capturing secondary reflections and reducing unnatural artifacts. By building on top of a differentiable framework, the proposed pipeline lays the groundwork for a fast and differentiable ultrasound simulation tool necessary for gradient-based optimization, enabling advanced ultrasound beamforming strategies, neural network integration, and accurate inverse scene reconstruction.
Intraoperative Registration by Cross-Modal Inverse Neural Rendering
Sep 18, 2024We present in this paper a novel approach for 3D/2D intraoperative registration during neurosurgery via cross-modal inverse neural rendering. Our approach separates implicit neural representation into two components, handling anatomical structure preoperatively and appearance intraoperatively. This disentanglement is achieved by controlling a Neural Radiance Field's appearance with a multi-style hypernetwork. Once trained, the implicit neural representation serves as a differentiable rendering engine, which can be used to estimate the surgical camera pose by minimizing the dissimilarity between its rendered images and the target intraoperative image. We tested our method on retrospective patients' data from clinical cases, showing that our method outperforms state-of-the-art while meeting current clinical standards for registration. Code and additional resources can be found at https://maxfehrentz.github.io/style-ngp/.