 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Haptic Model Mediated Teleoperation for Remote Ultrasound
Feb 11, 2025Tele-ultrasound has the potential greatly to improve health equity for countless remote communities. However, practical scenarios involve potentially large time delays which cause current implementations of telerobotic ultrasound (US) to fail. Using a local model of the remote environment to provide haptics to the expert operator can decrease teleoperation instability, but the delayed visual feedback remains problematic. This paper introduces a robotic tele-US system in which the local model is not only haptic, but also visual, by re-slicing and rendering a pre-acquired US sweep in real time to provide the operator a preview of what the delayed image will resemble. A prototype system is presented and tested with 15 volunteer operators. It is found that visual-haptic model-mediated teleoperation (MMT) compensates completely for time delays up to 1000 ms round trip in terms of operator effort and completion time while conventional MMT does not. Visual-haptic MMT also significantly outperforms MMT for longer time delays in terms of motion accuracy and force control. This proof-of-concept study suggests that visual-haptic MMT may facilitate remote robotic tele-US.
AI techniques for near real-time monitoring of contaminants in coastal waters on board future Phisat-2 mission
Apr 30, 2024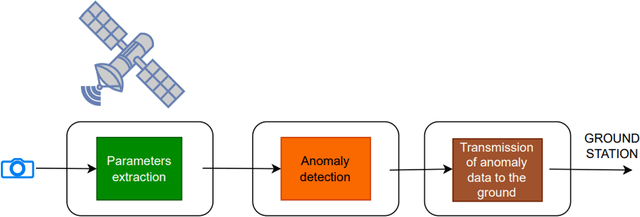
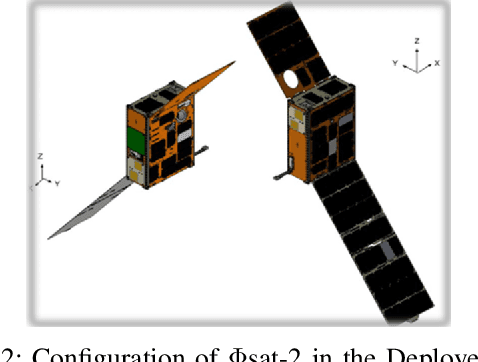
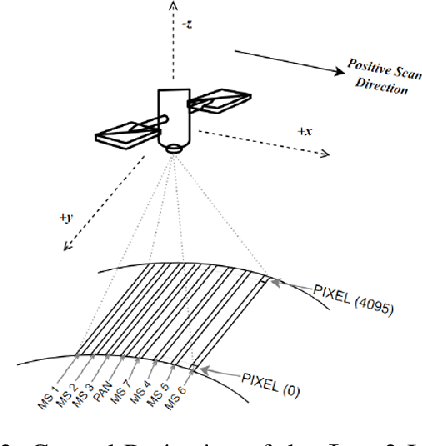
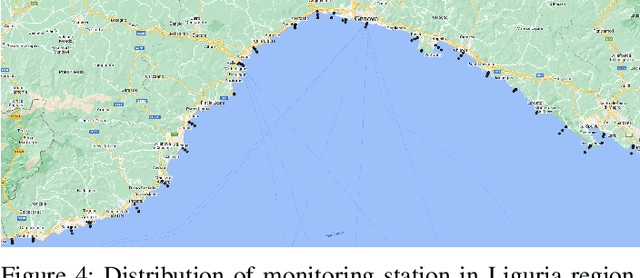
Differently from conventional procedures, the proposed solution advocates for a groundbreaking paradigm in water quality monitoring through the integration of satellite Remote Sensing (RS) data, Artificial Intelligence (AI) techniques, and onboard processing. The objective is to offer nearly real-time detection of contaminants in coastal waters addressing a significant gap in the existing literature. Moreover, the expected outcomes include substantial advancements in environmental monitoring, public health protection, and resource conservation. The specific focus of our study is on the estimation of Turbidity and pH parameters, for their implications on human and aquatic health. Nevertheless, the designed framework can be extended to include other parameters of interest in the water environment and beyond. Originating from our participation in the European Space Agency (ESA) OrbitalAI Challenge, this article describes the distinctive opportunities and issues for the contaminants monitoring on the Phisat-2 mission. The specific characteristics of this mission, with the tools made available, will be presented, with the methodology proposed by the authors for the onboard monitoring of water contaminants in near real-time. Preliminary promising results are discussed and in progress and future work introduced.
Monitoring water contaminants in coastal areas through ML algorithms leveraging atmospherically corrected Sentinel-2 data
Jan 08, 2024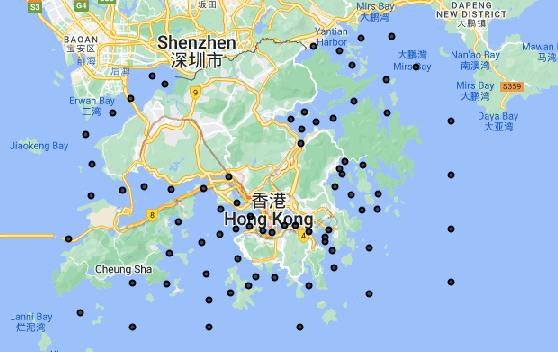

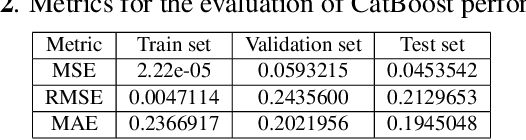
Monitoring water contaminants is of paramount importance, ensuring public health and environmental well-being. Turbidity, a key parameter, poses a significant problem, affecting water quality. Its accurate assessment is crucial for safeguarding ecosystems and human consumption, demanding meticulous attention and action. For this, our study pioneers a novel approach to monitor the Turbidity contaminant, integrating CatBoost Machine Learning (ML) with high-resolution data from Sentinel-2 Level-2A. Traditional methods are labor-intensive while CatBoost offers an efficient solution, excelling in predictive accuracy. Leveraging atmospherically corrected Sentinel-2 data through the Google Earth Engine (GEE), our study contributes to scalable and precise Turbidity monitoring. A specific tabular dataset derived from Hong Kong contaminants monitoring stations enriches our study, providing region-specific insights. Results showcase the viability of this integrated approach, laying the foundation for adopting advanced techniques in global water quality management.
Optimizing Fault-Tolerant Quality-Guaranteed Sensor Deployments for UAV Localization in Critical Areas via Computational Geometry
Dec 05, 2023The increasing spreading of small commercial Unmanned Aerial Vehicles (UAVs, aka drones) presents serious threats for critical areas such as airports, power plants, governmental and military facilities. In fact, such UAVs can easily disturb or jam radio communications, collide with other flying objects, perform espionage activity, and carry offensive payloads, e.g., weapons or explosives. A central problem when designing surveillance solutions for the localization of unauthorized UAVs in critical areas is to decide how many triangulating sensors to use, and where to deploy them to optimise both coverage and cost effectiveness. In this article, we compute deployments of triangulating sensors for UAV localization, optimizing a given blend of metrics, namely: coverage under multiple sensing quality levels, cost-effectiveness, fault-tolerance. We focus on large, complex 3D regions, which exhibit obstacles (e.g., buildings), varying terrain elevation, different coverage priorities, constraints on possible sensors placement. Our novel approach relies on computational geometry and statistical model checking, and enables the effective use of off-the-shelf AI-based black-box optimizers. Moreover, our method allows us to compute a closed-form, analytical representation of the region uncovered by a sensor deployment, which provides the means for rigorous, formal certification of the quality of the latter. We show the practical feasibility of our approach by computing optimal sensor deployments for UAV localization in two large, complex 3D critical regions, the Rome Leonardo Da Vinci International Airport (FCO) and the Vienna International Center (VIC), using NOMAD as our state-of-the-art underlying optimization engine. Results show that we can compute optimal sensor deployments within a few hours on a standard workstation and within minutes on a small parallel infrastructure.
Implicit Neural Representations for Breathing-compensated Volume Reconstruction in Robotic Ultrasound Aorta Screening
Nov 08, 2023Ultrasound (US) imaging is widely used in diagnosing and staging abdominal diseases due to its lack of non-ionizing radiation and prevalent availability. However, significant inter-operator variability and inconsistent image acquisition hinder the widespread adoption of extensive screening programs. Robotic ultrasound systems have emerged as a promising solution, offering standardized acquisition protocols and the possibility of automated acquisition. Additionally, these systems enable access to 3D data via robotic tracking, enhancing volumetric reconstruction for improved ultrasound interpretation and precise disease diagnosis. However, the interpretability of 3D US reconstruction of abdominal images can be affected by the patient's breathing motion. This study introduces a method to compensate for breathing motion in 3D US compounding by leveraging implicit neural representations. Our approach employs a robotic ultrasound system for automated screenings. To demonstrate the method's effectiveness, we evaluate our proposed method for the diagnosis and monitoring of abdominal aorta aneurysms as a representative use case. Our experiments demonstrate that our proposed pipeline facilitates robust automated robotic acquisition, mitigating artifacts from breathing motion, and yields smoother 3D reconstructions for enhanced screening and medical diagnosis.
Autonomous Robotic Screening of Tubular Structures based only on Real-Time Ultrasound Imaging Feedback
Oct 30, 2020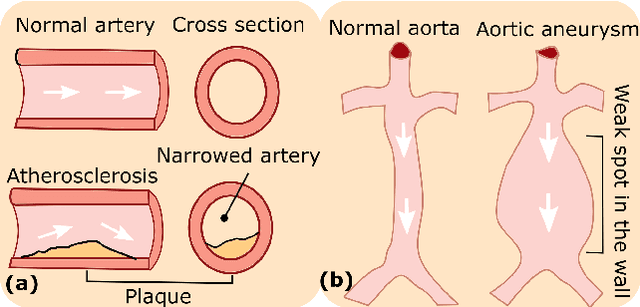

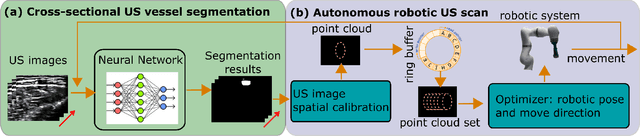
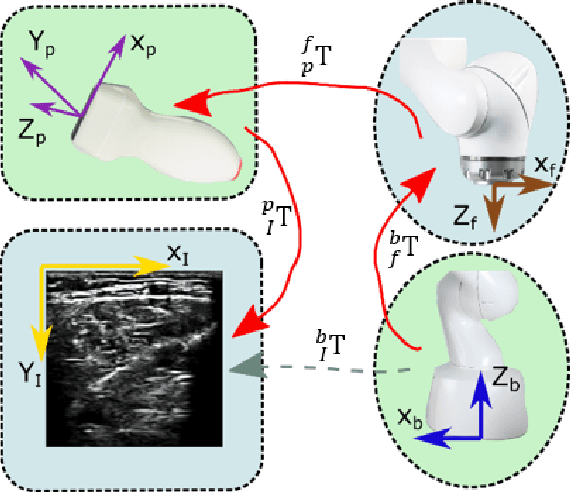
Ultrasound (US) imaging is widely employed for diagnosis and staging of peripheral vascular diseases (PVD), mainly due to its high availability and the fact it does not emit radiation. However, high inter-operator variability and a lack of repeatability of US image acquisition hinder the implementation of extensive screening programs. To address this challenge, we propose an end-to-end workflow for automatic robotic US screening of tubular structures using only the real-time US imaging feedback. We first train a U-Net for real-time segmentation of the vascular structure from cross-sectional US images. Then, we represent the detected vascular structure as a 3D point cloud and use it to estimate the longitudinal axis of the target tubular structure and its mean radius by solving a constrained non-linear optimization problem. Iterating the previous processes, the US probe is automatically aligned to the orientation normal to the target tubular tissue and adjusted online to center the tracked tissue based on the spatial calibration. The real-time segmentation result is evaluated both on a phantom and in-vivo on brachial arteries of volunteers. In addition, the whole process is validated both in simulation and physical phantoms. The mean absolute radius error and orientation error ($\pm$ SD) in the simulation are $1.16\pm0.1~mm$ and $2.7\pm3.3^{\circ}$, respectively. On a gel phantom, these errors are $1.95\pm2.02~mm$ and $3.3\pm2.4^{\circ}$. This shows that the method is able to automatically screen tubular tissues with an optimal probe orientation (i.e. normal to the vessel) and at the same to accurately estimate the mean radius, both in real-time.
CFCM: Segmentation via Coarse to Fine Context Memory
Jun 04, 2018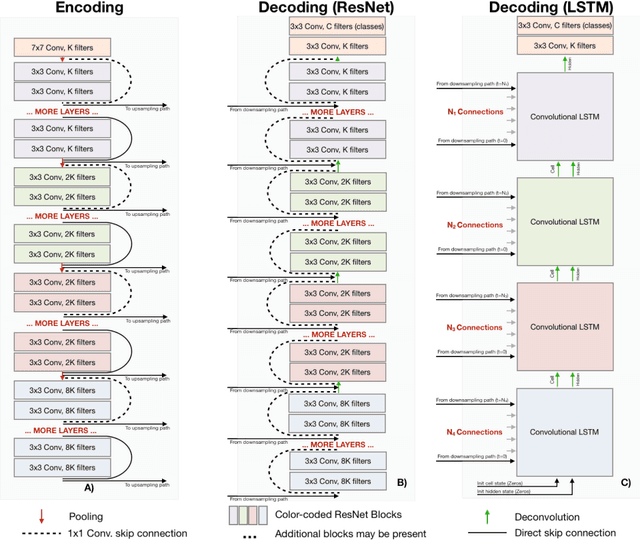
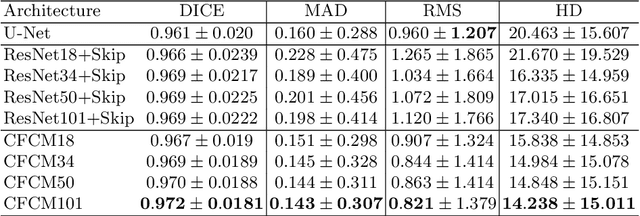
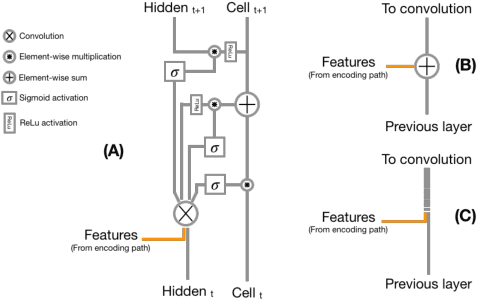
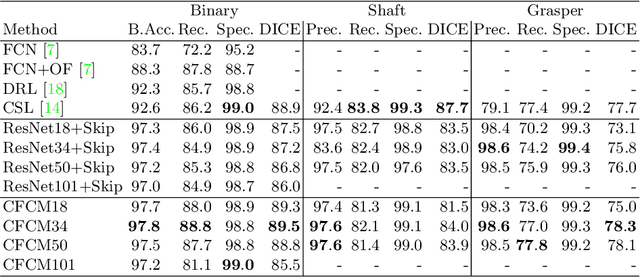
Recent neural-network-based architectures for image segmentation make extensive usage of feature forwarding mechanisms to integrate information from multiple scales. Although yielding good results, even deeper architectures and alternative methods for feature fusion at different resolutions have been scarcely investigated for medical applications. In this work we propose to implement segmentation via an encoder-decoder architecture which differs from any other previously published method since (i) it employs a very deep architecture based on residual learning and (ii) combines features via a convolutional Long Short Term Memory (LSTM), instead of concatenation or summation. The intuition is that the memory mechanism implemented by LSTMs can better integrate features from different scales through a coarse-to-fine strategy; hence the name Coarse-to-Fine Context Memory (CFCM). We demonstrate the remarkable advantages of this approach on two datasets: the Montgomery county lung segmentation dataset, and the EndoVis 2015 challenge dataset for surgical instrument segmentation.