 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLiCADA -- Reservoir Computing using Linear Cellular Automata Design Algorithm
Aug 22, 2023In this paper, we present a novel algorithm to optimize the design of Reservoir Computing using Cellular Automata models for time series applications. Besides selecting the models' hyperparameters, the proposed algorithm particularly solves the open problem of linear Cellular Automaton rule selection. The selection method pre-selects only a few promising candidate rules out of an exponentially growing rule space. When applied to relevant benchmark datasets, the selected rules achieve low errors, with the best rules being among the top 5% of the overall rule space. The algorithm was developed based on mathematical analysis of linear Cellular Automaton properties and is backed by almost one million experiments, adding up to a computational runtime of nearly one year. Comparisons to other state-of-the-art time series models show that the proposed Reservoir Computing using Cellular Automata models have lower computational complexity, at the same time, achieve lower errors. Hence, our approach reduces the time needed for training and hyperparameter optimization by up to several orders of magnitude.
Skeleton Graph-based Ultrasound-CT Non-rigid Registration
May 14, 2023



Autonomous ultrasound (US) scanning has attracted increased attention, and it has been seen as a potential solution to overcome the limitations of conventional US examinations, such as inter-operator variations. However, it is still challenging to autonomously and accurately transfer a planned scan trajectory on a generic atlas to the current setup for different patients, particularly for thorax applications with limited acoustic windows. To address this challenge, we proposed a skeleton graph-based non-rigid registration to adapt patient-specific properties using subcutaneous bone surface features rather than the skin surface. To this end, the self-organization mapping is successively used twice to unify the input point cloud and extract the key points, respectively. Afterward, the minimal spanning tree is employed to generate a tree graph to connect all extracted key points. To appropriately characterize the rib cartilage outline to match the source and target point cloud, the path extracted from the tree graph is optimized by maximally maintaining continuity throughout each rib. To validate the proposed approach, we manually extract the US cartilage point cloud from one volunteer and seven CT cartilage point clouds from different patients. The results demonstrate that the proposed graph-based registration is more effective and robust in adapting to the inter-patient variations than the ICP (distance error mean/SD: 5.0/1.9 mm vs 8.6/6.7 mm on seven CTs).
BreakingBED -- Breaking Binary and Efficient Deep Neural Networks by Adversarial Attacks
Mar 14, 2021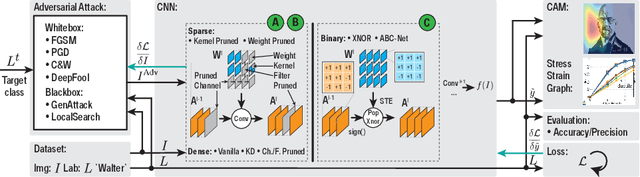
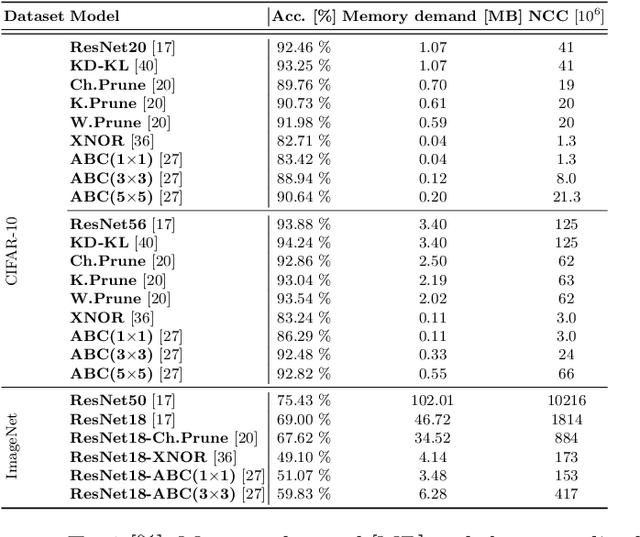
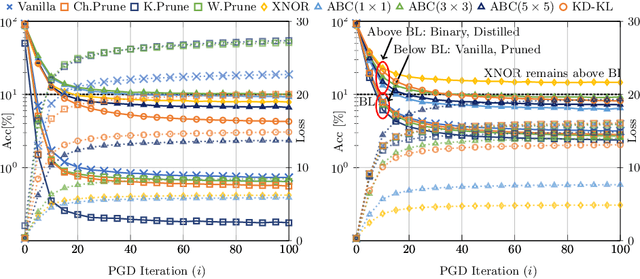
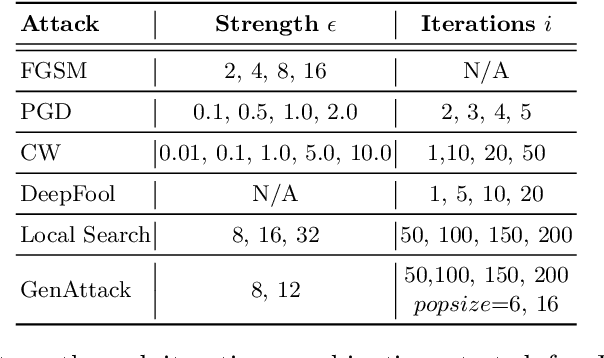
Deploying convolutional neural networks (CNNs) for embedded applications presents many challenges in balancing resource-efficiency and task-related accuracy. These two aspects have been well-researched in the field of CNN compression. In real-world applications, a third important aspect comes into play, namely the robustness of the CNN. In this paper, we thoroughly study the robustness of uncompressed, distilled, pruned and binarized neural networks against white-box and black-box adversarial attacks (FGSM, PGD, C&W, DeepFool, LocalSearch and GenAttack). These new insights facilitate defensive training schemes or reactive filtering methods, where the attack is detected and the input is discarded and/or cleaned. Experimental results are shown for distilled CNNs, agent-based state-of-the-art pruned models, and binarized neural networks (BNNs) such as XNOR-Net and ABC-Net, trained on CIFAR-10 and ImageNet datasets. We present evaluation methods to simplify the comparison between CNNs under different attack schemes using loss/accuracy levels, stress-strain graphs, box-plots and class activation mapping (CAM). Our analysis reveals susceptible behavior of uncompressed and pruned CNNs against all kinds of attacks. The distilled models exhibit their strength against all white box attacks with an exception of C&W. Furthermore, binary neural networks exhibit resilient behavior compared to their baselines and other compressed variants.
BinaryCoP: Binary Neural Network-based COVID-19 Face-Mask Wear and Positioning Predictor on Edge Devices
Feb 06, 2021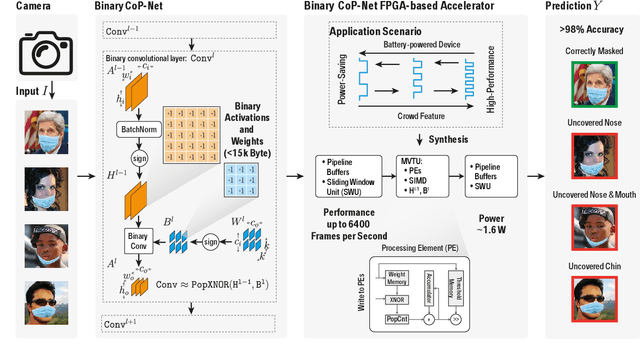
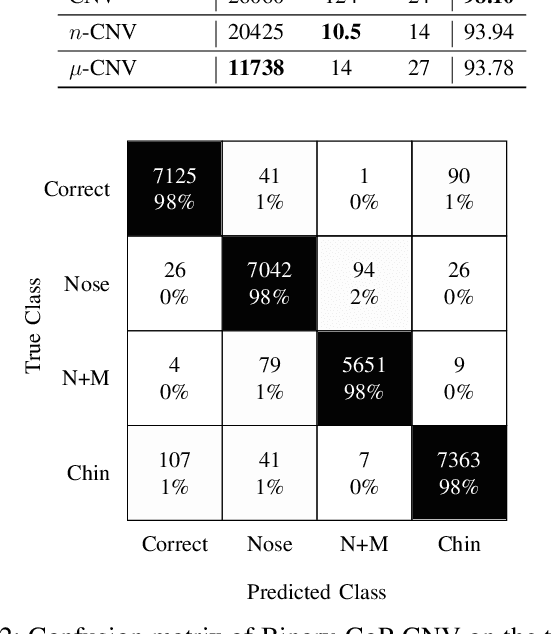
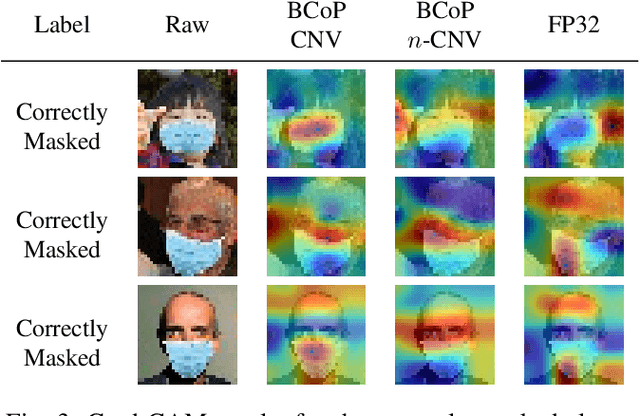
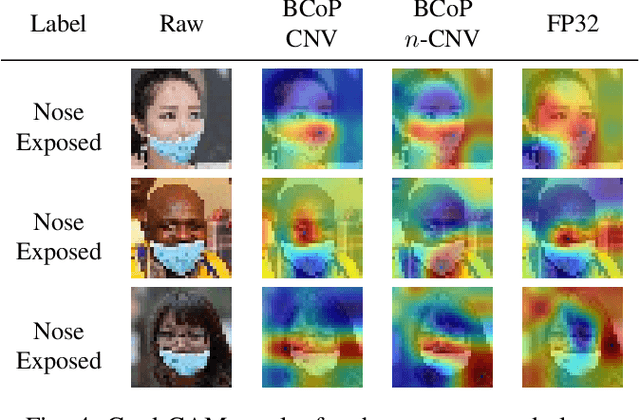
Face masks have long been used in many areas of everyday life to protect against the inhalation of hazardous fumes and particles. They also offer an effective solution in healthcare for bi-directional protection against air-borne diseases. Wearing and positioning the mask correctly is essential for its function. Convolutional neural networks (CNNs) offer an excellent solution for face recognition and classification of correct mask wearing and positioning. In the context of the ongoing COVID-19 pandemic, such algorithms can be used at entrances to corporate buildings, airports, shopping areas, and other indoor locations, to mitigate the spread of the virus. These application scenarios impose major challenges to the underlying compute platform. The inference hardware must be cheap, small and energy efficient, while providing sufficient memory and compute power to execute accurate CNNs at a reasonably low latency. To maintain data privacy of the public, all processing must remain on the edge-device, without any communication with cloud servers. To address these challenges, we present a low-power binary neural network classifier for correct facial-mask wear and positioning. The classification task is implemented on an embedded FPGA, performing high-throughput binary operations. Classification can take place at up to ~6400 frames-per-second, easily enabling multi-camera, speed-gate settings or statistics collection in crowd settings. When deployed on a single entrance or gate, the idle power consumption is reduced to 1.6W, improving the battery-life of the device. We achieve an accuracy of up to 98% for four wearing positions of the MaskedFace-Net dataset. To maintain equivalent classification accuracy for all face structures, skin-tones, hair types, and mask types, the algorithms are tested for their ability to generalize the relevant features over all subjects using the Grad-CAM approach.
L2PF -- Learning to Prune Faster
Jan 07, 2021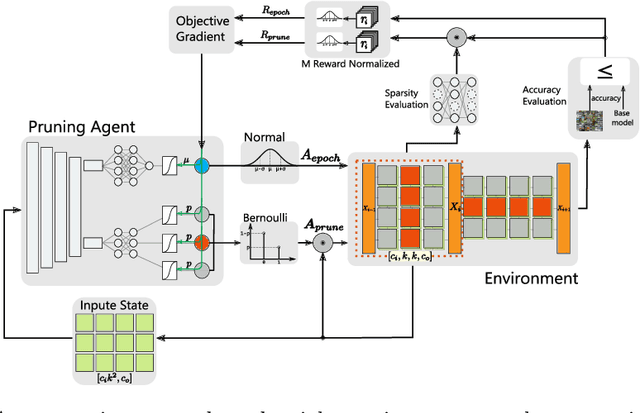
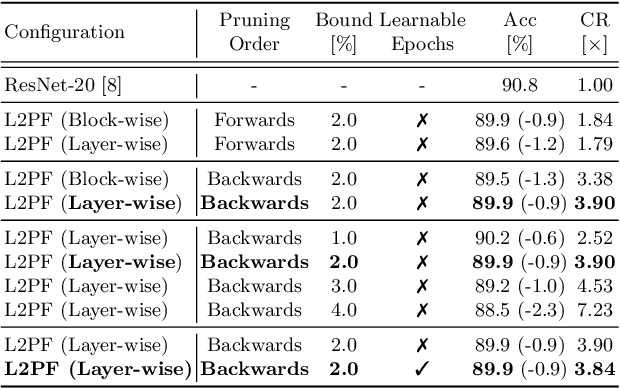
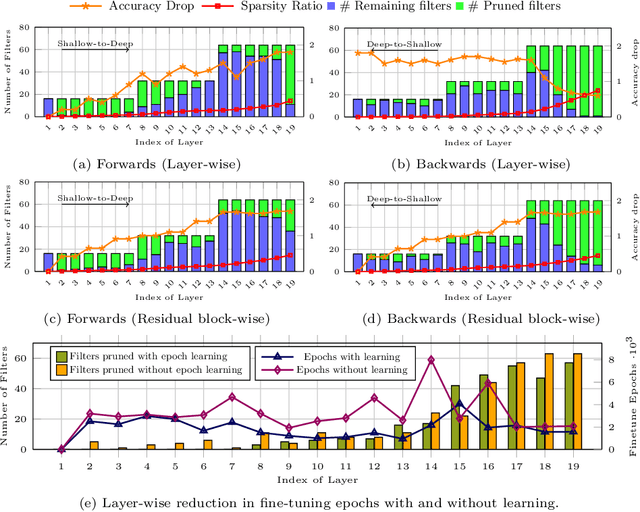
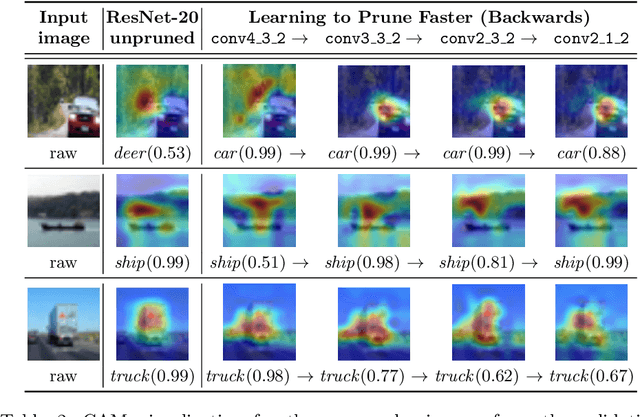
Various applications in the field of autonomous driving are based on convolutional neural networks (CNNs), especially for processing camera data. The optimization of such CNNs is a major challenge in continuous development. Newly learned features must be brought into vehicles as quickly as possible, and as such, it is not feasible to spend redundant GPU hours during compression. In this context, we present Learning to Prune Faster which details a multi-task, try-and-learn method, discretely learning redundant filters of the CNN and a continuous action of how long the layers have to be fine-tuned. This allows us to significantly speed up the convergence process of learning how to find an embedded-friendly filter-wise pruned CNN. For ResNet20, we have achieved a compression ratio of 3.84 x with minimal accuracy degradation. Compared to the state-of-the-art pruning method, we reduced the GPU hours by 1.71 x.
Autonomous Robotic Screening of Tubular Structures based only on Real-Time Ultrasound Imaging Feedback
Oct 30, 2020

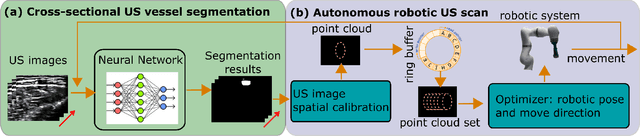
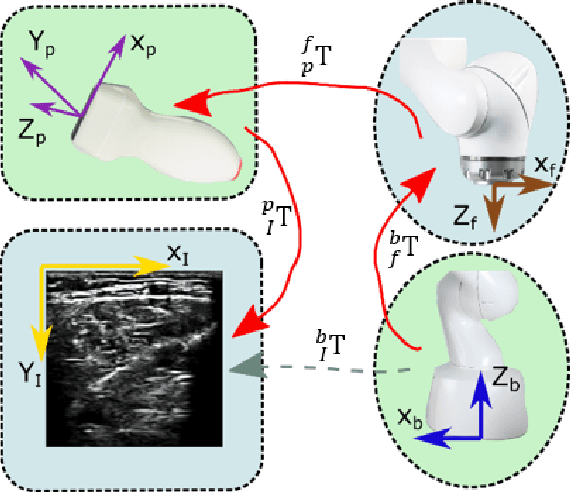
Ultrasound (US) imaging is widely employed for diagnosis and staging of peripheral vascular diseases (PVD), mainly due to its high availability and the fact it does not emit radiation. However, high inter-operator variability and a lack of repeatability of US image acquisition hinder the implementation of extensive screening programs. To address this challenge, we propose an end-to-end workflow for automatic robotic US screening of tubular structures using only the real-time US imaging feedback. We first train a U-Net for real-time segmentation of the vascular structure from cross-sectional US images. Then, we represent the detected vascular structure as a 3D point cloud and use it to estimate the longitudinal axis of the target tubular structure and its mean radius by solving a constrained non-linear optimization problem. Iterating the previous processes, the US probe is automatically aligned to the orientation normal to the target tubular tissue and adjusted online to center the tracked tissue based on the spatial calibration. The real-time segmentation result is evaluated both on a phantom and in-vivo on brachial arteries of volunteers. In addition, the whole process is validated both in simulation and physical phantoms. The mean absolute radius error and orientation error ($\pm$ SD) in the simulation are $1.16\pm0.1~mm$ and $2.7\pm3.3^{\circ}$, respectively. On a gel phantom, these errors are $1.95\pm2.02~mm$ and $3.3\pm2.4^{\circ}$. This shows that the method is able to automatically screen tubular tissues with an optimal probe orientation (i.e. normal to the vessel) and at the same to accurately estimate the mean radius, both in real-time.
ALF: Autoencoder-based Low-rank Filter-sharing for Efficient Convolutional Neural Networks
Jul 27, 2020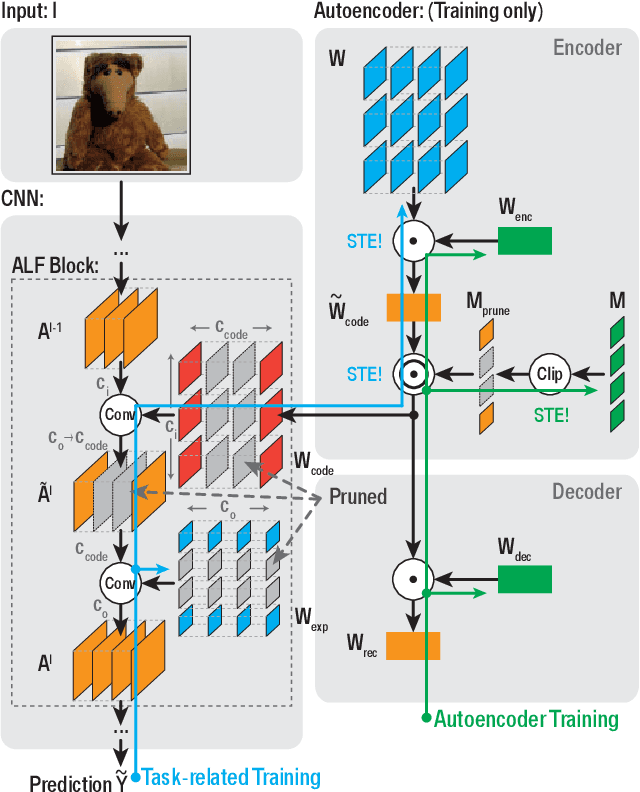
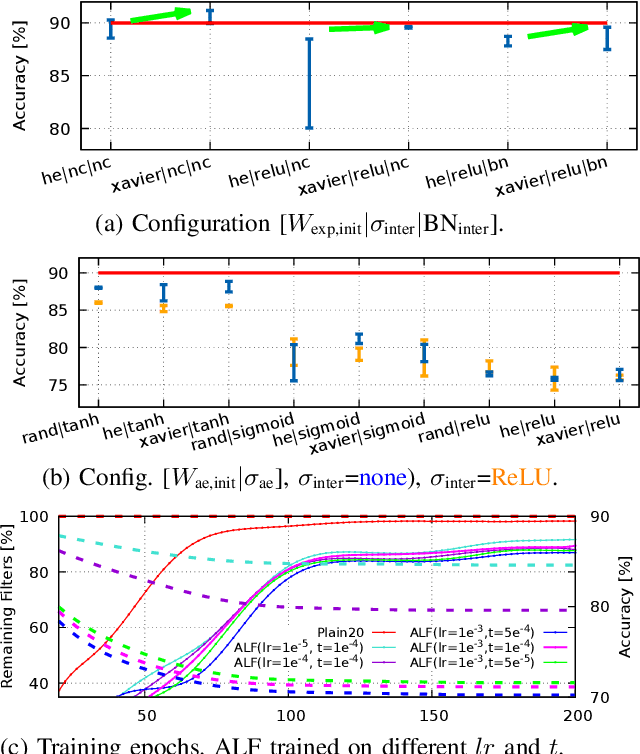

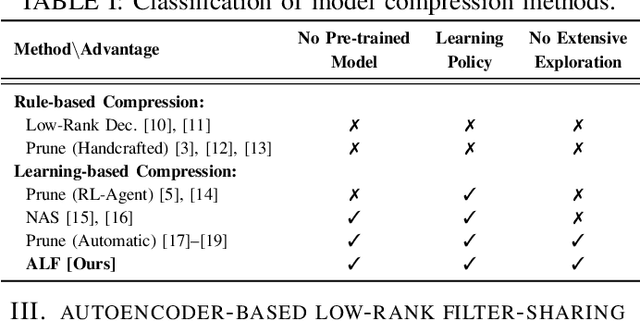
Closing the gap between the hardware requirements of state-of-the-art convolutional neural networks and the limited resources constraining embedded applications is the next big challenge in deep learning research. The computational complexity and memory footprint of such neural networks are typically daunting for deployment in resource constrained environments. Model compression techniques, such as pruning, are emphasized among other optimization methods for solving this problem. Most existing techniques require domain expertise or result in irregular sparse representations, which increase the burden of deploying deep learning applications on embedded hardware accelerators. In this paper, we propose the autoencoder-based low-rank filter-sharing technique technique (ALF). When applied to various networks, ALF is compared to state-of-the-art pruning methods, demonstrating its efficient compression capabilities on theoretical metrics as well as on an accurate, deterministic hardware-model. In our experiments, ALF showed a reduction of 70\% in network parameters, 61\% in operations and 41\% in execution time, with minimal loss in accuracy.
Binary DAD-Net: Binarized Driveable Area Detection Network for Autonomous Driving
Jun 15, 2020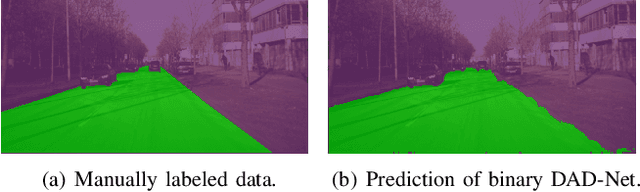
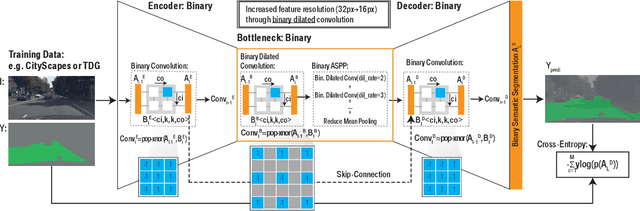
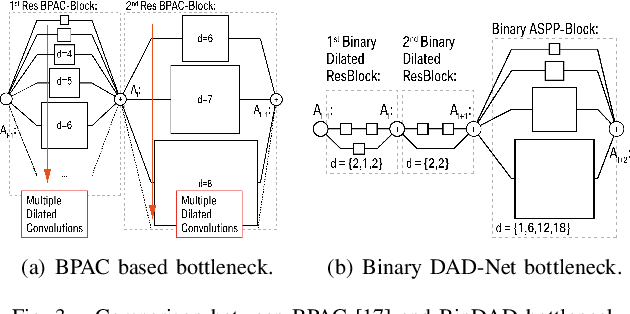

Driveable area detection is a key component for various applications in the field of autonomous driving (AD), such as ground-plane detection, obstacle detection and maneuver planning. Additionally, bulky and over-parameterized networks can be easily forgone and replaced with smaller networks for faster inference on embedded systems. The driveable area detection, posed as a two class segmentation task, can be efficiently modeled with slim binary networks. This paper proposes a novel binarized driveable area detection network (binary DAD-Net), which uses only binary weights and activations in the encoder, the bottleneck, and the decoder part. The latent space of the bottleneck is efficiently increased (x32 -> x16 downsampling) through binary dilated convolutions, learning more complex features. Along with automatically generated training data, the binary DAD-Net outperforms state-of-the-art semantic segmentation networks on public datasets. In comparison to a full-precision model, our approach has a x14.3 reduced compute complexity on an FPGA and it requires only 0.9MB memory resources. Therefore, commodity SIMD-based AD-hardware is capable of accelerating the binary DAD-Net.
Resource Prediction for Humanoid Robots
May 12, 2014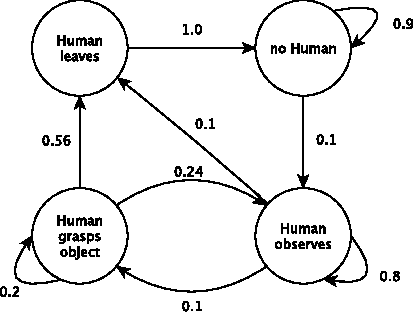
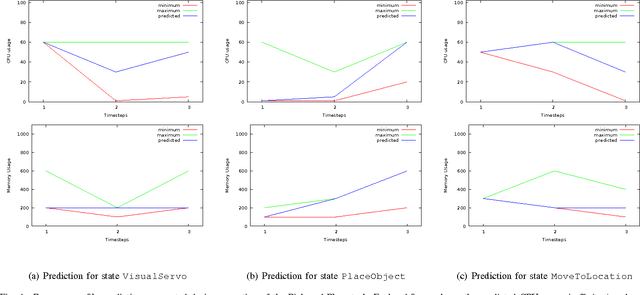
Humanoid robots are designed to operate in human centered environments where they execute a multitude of challenging tasks, each differing in complexity, resource requirements, and execution time. In such highly dynamic surroundings it is desirable to anticipate upcoming situations in order to predict future resource requirements such as CPU or memory usage. Resource prediction information is essential for detecting upcoming resource bottlenecks or conflicts and can be used enhance resource negotiation processes or to perform speculative resource allocation. In this paper we present a prediction model based on Markov chains for predicting the behavior of the humanoid robot ARMAR-III in human robot interaction scenarios. Robot state information required by the prediction algorithm is gathered through self-monitoring and combined with environmental context information. Adding resource profiles allows generating probability distributions of possible future resource demands. Online learning of model parameters is made possible through disclosure mechanisms provided by the robot framework ArmarX.
Resource-Aware Programming for Robotic Vision
May 12, 2014
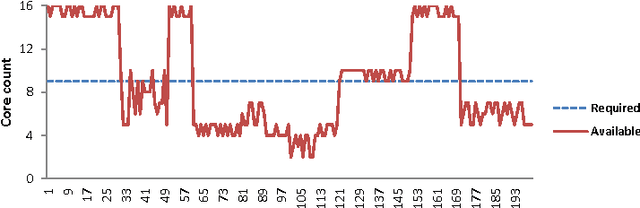
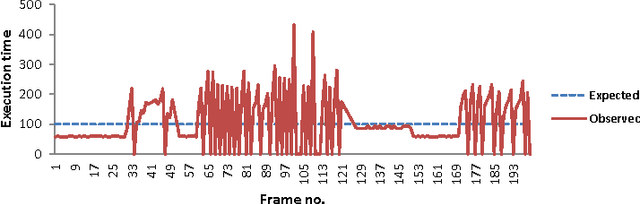
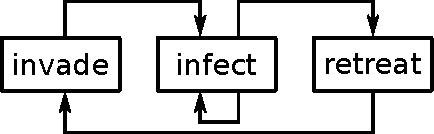
Humanoid robots are designed to operate in human centered environments. They face changing, dynamic environments in which they need to fulfill a multitude of challenging tasks. Such tasks differ in complexity, resource requirements, and execution time. Latest computer architectures of humanoid robots consist of several industrial PCs containing single- or dual-core processors. According to the SIA roadmap for semiconductors, many-core chips with hundreds to thousands of cores are expected to be available in the next decade. Utilizing the full power of a chip with huge amounts of resources requires new computing paradigms and methodologies. In this paper, we analyze a resource-aware computing methodology named Invasive Computing, to address these challenges. The benefits and limitations of the new programming model is analyzed using two widely used computer vision algorithms, the Harris Corner detector and SIFT (Scale Invariant Feature Transform) feature matching. The result indicate that the new programming model together with the extensions within the application layer, makes them highly adaptable; leading to better quality in the results obtained.