 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinaryCoP: Binary Neural Network-based COVID-19 Face-Mask Wear and Positioning Predictor on Edge Devices
Feb 06, 2021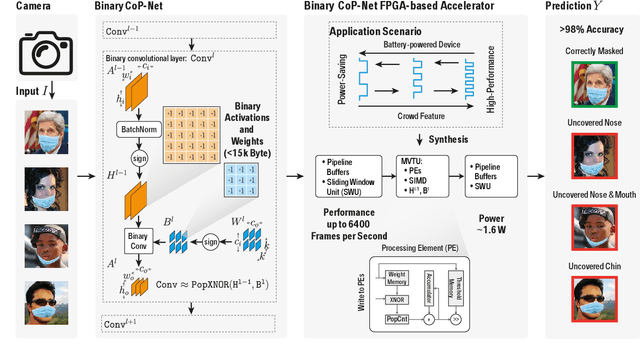
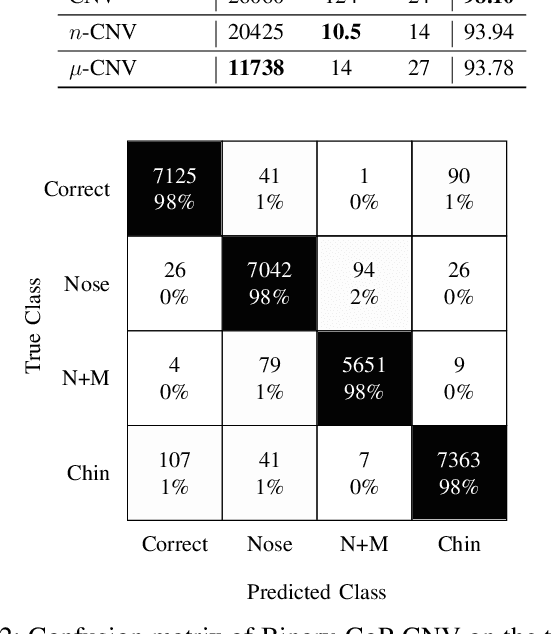
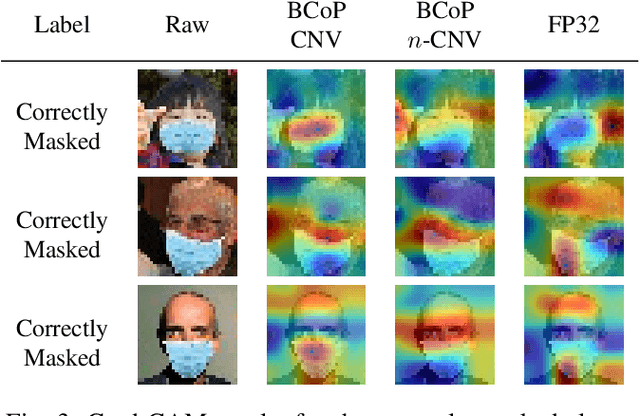
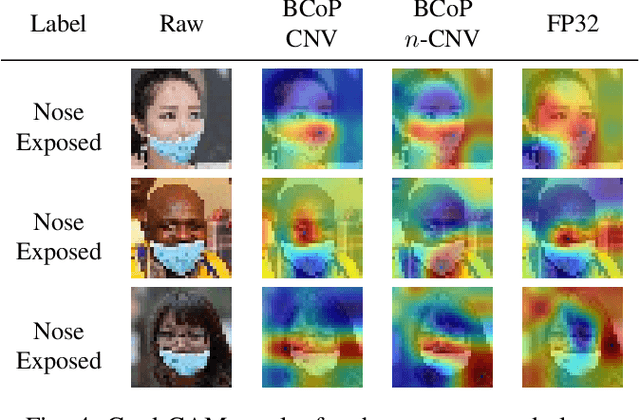
Face masks have long been used in many areas of everyday life to protect against the inhalation of hazardous fumes and particles. They also offer an effective solution in healthcare for bi-directional protection against air-borne diseases. Wearing and positioning the mask correctly is essential for its function. Convolutional neural networks (CNNs) offer an excellent solution for face recognition and classification of correct mask wearing and positioning. In the context of the ongoing COVID-19 pandemic, such algorithms can be used at entrances to corporate buildings, airports, shopping areas, and other indoor locations, to mitigate the spread of the virus. These application scenarios impose major challenges to the underlying compute platform. The inference hardware must be cheap, small and energy efficient, while providing sufficient memory and compute power to execute accurate CNNs at a reasonably low latency. To maintain data privacy of the public, all processing must remain on the edge-device, without any communication with cloud servers. To address these challenges, we present a low-power binary neural network classifier for correct facial-mask wear and positioning. The classification task is implemented on an embedded FPGA, performing high-throughput binary operations. Classification can take place at up to ~6400 frames-per-second, easily enabling multi-camera, speed-gate settings or statistics collection in crowd settings. When deployed on a single entrance or gate, the idle power consumption is reduced to 1.6W, improving the battery-life of the device. We achieve an accuracy of up to 98% for four wearing positions of the MaskedFace-Net dataset. To maintain equivalent classification accuracy for all face structures, skin-tones, hair types, and mask types, the algorithms are tested for their ability to generalize the relevant features over all subjects using the Grad-CAM approach.
L2PF -- Learning to Prune Faster
Jan 07, 2021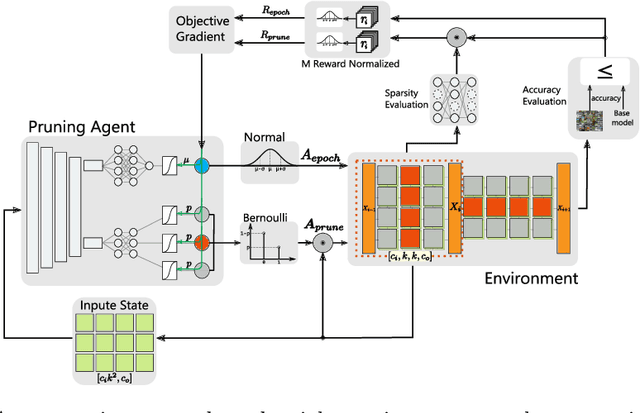
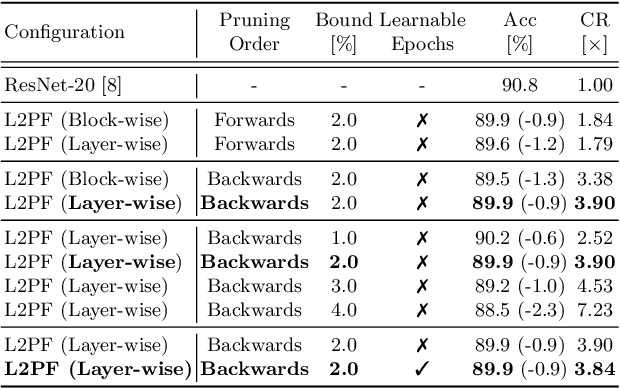
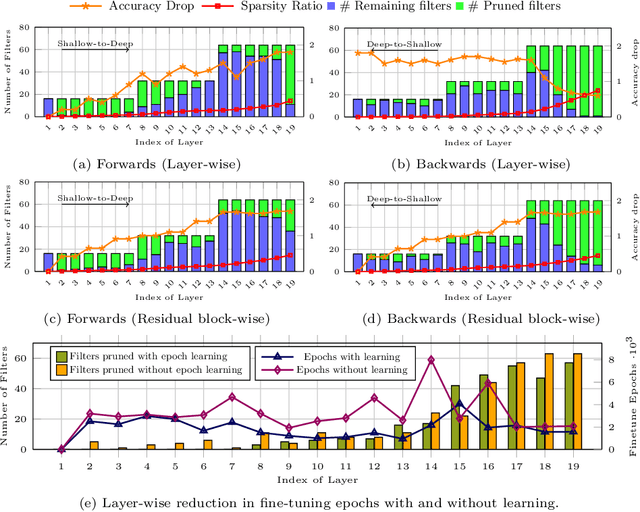
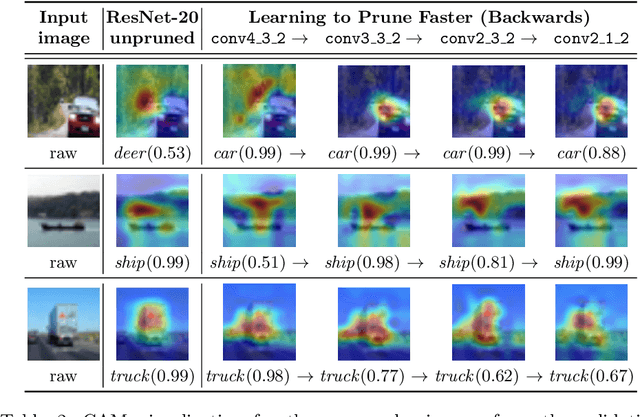
Various applications in the field of autonomous driving are based on convolutional neural networks (CNNs), especially for processing camera data. The optimization of such CNNs is a major challenge in continuous development. Newly learned features must be brought into vehicles as quickly as possible, and as such, it is not feasible to spend redundant GPU hours during compression. In this context, we present Learning to Prune Faster which details a multi-task, try-and-learn method, discretely learning redundant filters of the CNN and a continuous action of how long the layers have to be fine-tuned. This allows us to significantly speed up the convergence process of learning how to find an embedded-friendly filter-wise pruned CNN. For ResNet20, we have achieved a compression ratio of 3.84 x with minimal accuracy degradation. Compared to the state-of-the-art pruning method, we reduced the GPU hours by 1.71 x.
ALF: Autoencoder-based Low-rank Filter-sharing for Efficient Convolutional Neural Networks
Jul 27, 2020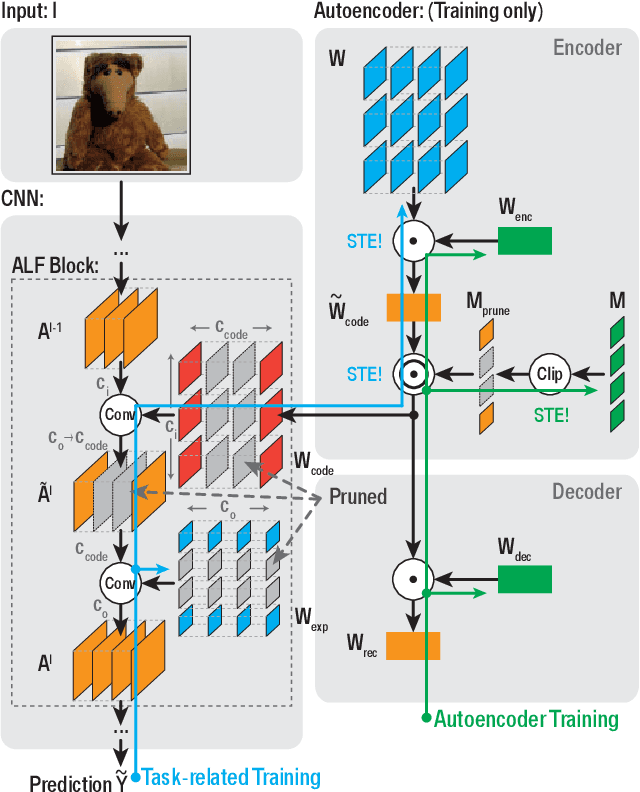
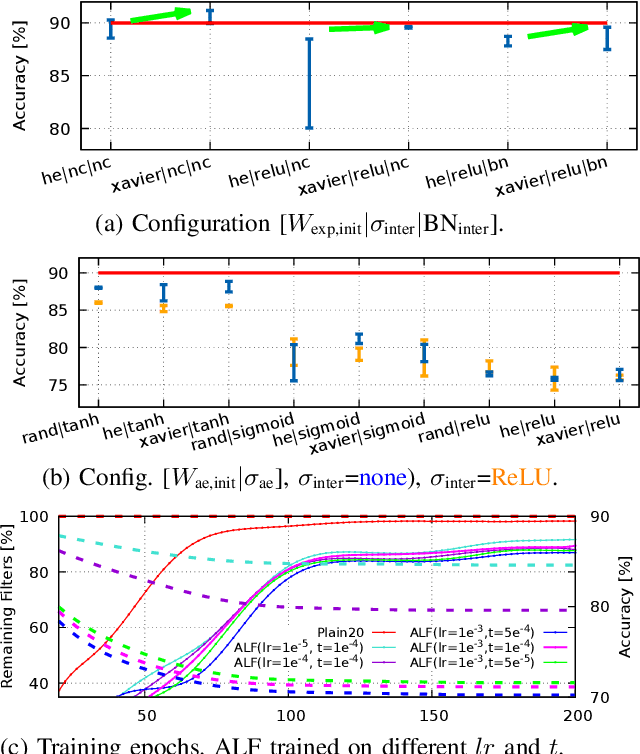

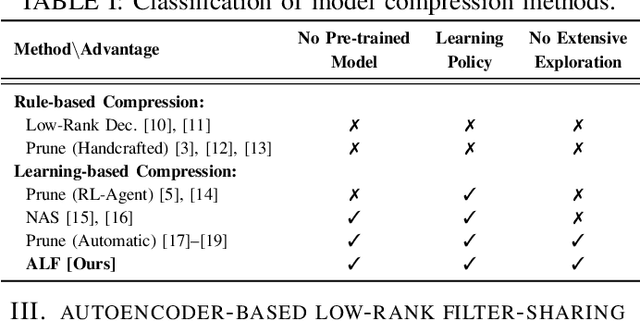
Closing the gap between the hardware requirements of state-of-the-art convolutional neural networks and the limited resources constraining embedded applications is the next big challenge in deep learning research. The computational complexity and memory footprint of such neural networks are typically daunting for deployment in resource constrained environments. Model compression techniques, such as pruning, are emphasized among other optimization methods for solving this problem. Most existing techniques require domain expertise or result in irregular sparse representations, which increase the burden of deploying deep learning applications on embedded hardware accelerators. In this paper, we propose the autoencoder-based low-rank filter-sharing technique technique (ALF). When applied to various networks, ALF is compared to state-of-the-art pruning methods, demonstrating its efficient compression capabilities on theoretical metrics as well as on an accurate, deterministic hardware-model. In our experiments, ALF showed a reduction of 70\% in network parameters, 61\% in operations and 41\% in execution time, with minimal loss in accuracy.