 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreakingBED -- Breaking Binary and Efficient Deep Neural Networks by Adversarial Attacks
Mar 14, 2021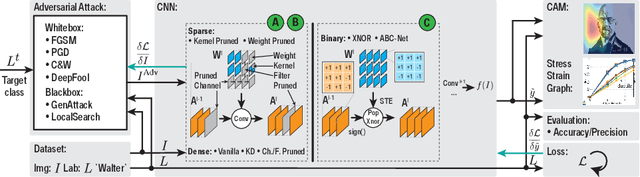
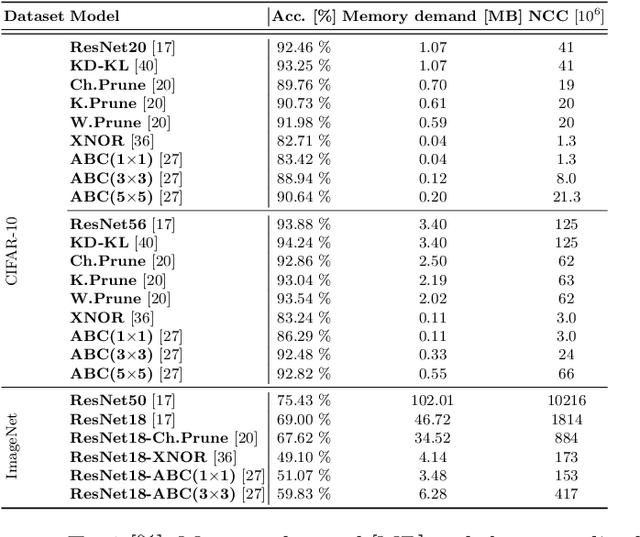
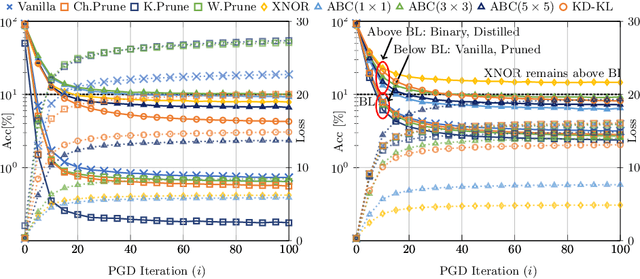
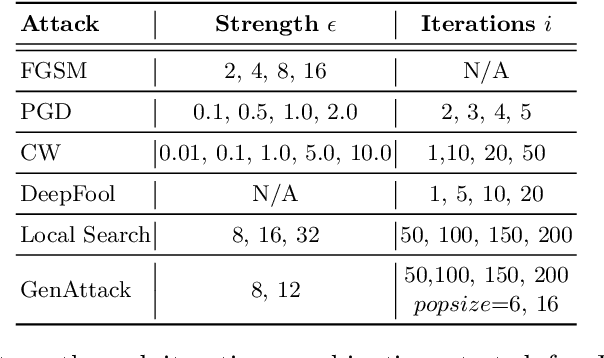
Deploying convolutional neural networks (CNNs) for embedded applications presents many challenges in balancing resource-efficiency and task-related accuracy. These two aspects have been well-researched in the field of CNN compression. In real-world applications, a third important aspect comes into play, namely the robustness of the CNN. In this paper, we thoroughly study the robustness of uncompressed, distilled, pruned and binarized neural networks against white-box and black-box adversarial attacks (FGSM, PGD, C&W, DeepFool, LocalSearch and GenAttack). These new insights facilitate defensive training schemes or reactive filtering methods, where the attack is detected and the input is discarded and/or cleaned. Experimental results are shown for distilled CNNs, agent-based state-of-the-art pruned models, and binarized neural networks (BNNs) such as XNOR-Net and ABC-Net, trained on CIFAR-10 and ImageNet datasets. We present evaluation methods to simplify the comparison between CNNs under different attack schemes using loss/accuracy levels, stress-strain graphs, box-plots and class activation mapping (CAM). Our analysis reveals susceptible behavior of uncompressed and pruned CNNs against all kinds of attacks. The distilled models exhibit their strength against all white box attacks with an exception of C&W. Furthermore, binary neural networks exhibit resilient behavior compared to their baselines and other compressed variants.
L2PF -- Learning to Prune Faster
Jan 07, 2021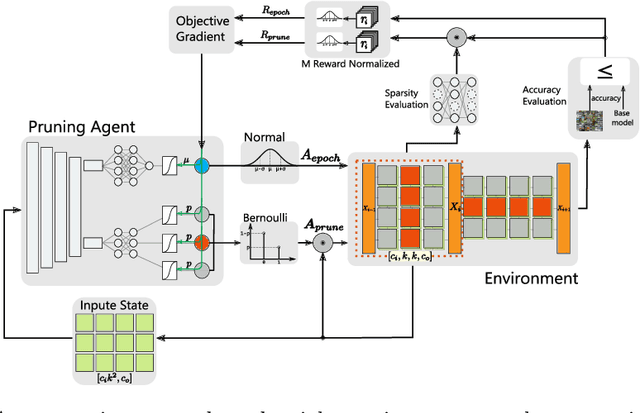
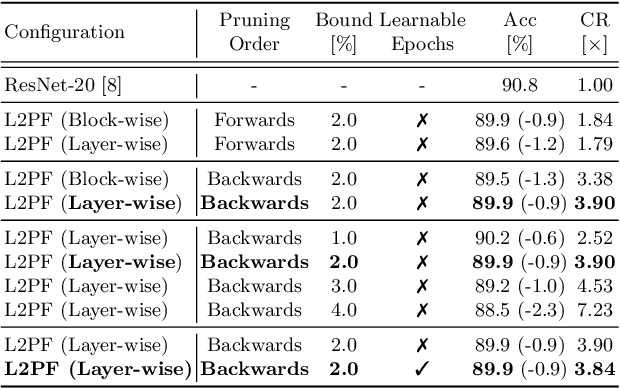
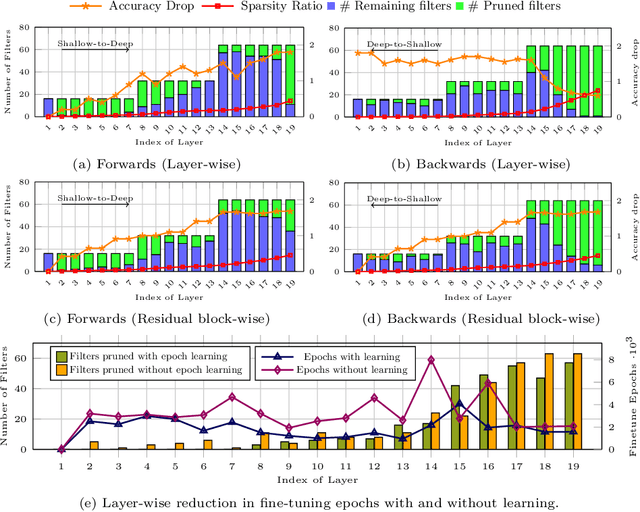
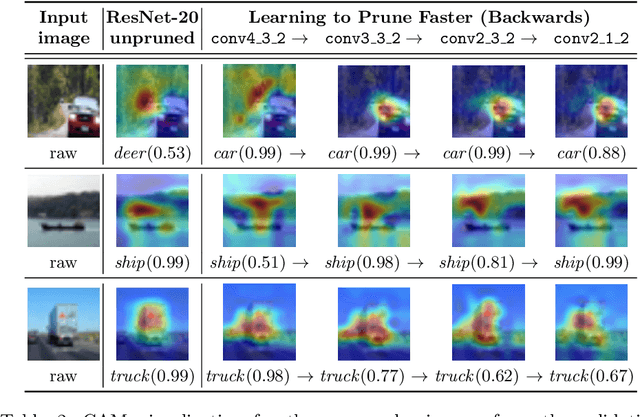
Various applications in the field of autonomous driving are based on convolutional neural networks (CNNs), especially for processing camera data. The optimization of such CNNs is a major challenge in continuous development. Newly learned features must be brought into vehicles as quickly as possible, and as such, it is not feasible to spend redundant GPU hours during compression. In this context, we present Learning to Prune Faster which details a multi-task, try-and-learn method, discretely learning redundant filters of the CNN and a continuous action of how long the layers have to be fine-tuned. This allows us to significantly speed up the convergence process of learning how to find an embedded-friendly filter-wise pruned CNN. For ResNet20, we have achieved a compression ratio of 3.84 x with minimal accuracy degradation. Compared to the state-of-the-art pruning method, we reduced the GPU hours by 1.71 x.
MonoComb: A Sparse-to-Dense Combination Approach for Monocular Scene Flow
Nov 12, 2020



Contrary to the ongoing trend in automotive applications towards usage of more diverse and more sensors, this work tries to solve the complex scene flow problem under a monocular camera setup, i.e. using a single sensor. Towards this end, we exploit the latest achievements in single image depth estimation, optical flow, and sparse-to-dense interpolation and propose a monocular combination approach (MonoComb) to compute dense scene flow. MonoComb uses optical flow to relate reconstructed 3D positions over time and interpolates occluded areas. This way, existing monocular methods are outperformed in dynamic foreground regions which leads to the second best result among the competitors on the challenging KITTI 2015 scene flow benchmark.
A Deep Temporal Fusion Framework for Scene Flow Using a Learnable Motion Model and Occlusions
Nov 04, 2020


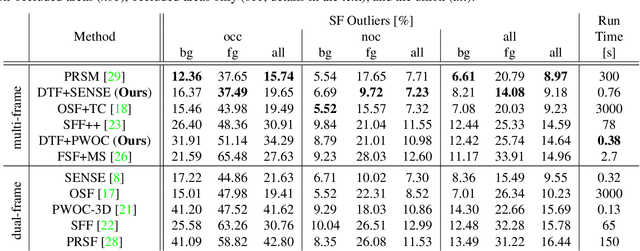
Motion estimation is one of the core challenges in computer vision. With traditional dual-frame approaches, occlusions and out-of-view motions are a limiting factor, especially in the context of environmental perception for vehicles due to the large (ego-) motion of objects. Our work proposes a novel data-driven approach for temporal fusion of scene flow estimates in a multi-frame setup to overcome the issue of occlusion. Contrary to most previous methods, we do not rely on a constant motion model, but instead learn a generic temporal relation of motion from data. In a second step, a neural network combines bi-directional scene flow estimates from a common reference frame, yielding a refined estimate and a natural byproduct of occlusion masks. This way, our approach provides a fast multi-frame extension for a variety of scene flow estimators, which outperforms the underlying dual-frame approaches.
SSGP: Sparse Spatial Guided Propagation for Robust and Generic Interpolation
Aug 21, 2020


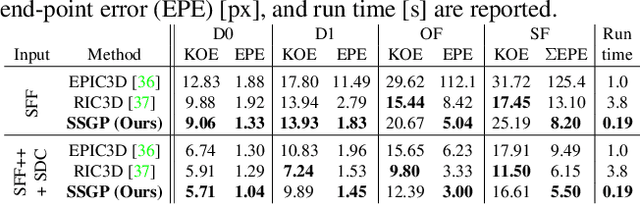
Interpolation of sparse pixel information towards a dense target resolution finds its application across multiple disciplines in computer vision. State-of-the-art interpolation of motion fields applies model-based interpolation that makes use of edge information extracted from the target image. For depth completion, data-driven learning approaches are widespread. Our work is inspired by latest trends in depth completion that tackle the problem of dense guidance for sparse information. We extend these ideas and create a generic cross-domain architecture that can be applied for a multitude of interpolation problems like optical flow, scene flow, or depth completion. In our experiments, we show that our proposed concept of Sparse Spatial Guided Propagation (SSGP) achieves improvements to robustness, accuracy, or speed compared to specialized algorithms.
ALF: Autoencoder-based Low-rank Filter-sharing for Efficient Convolutional Neural Networks
Jul 27, 2020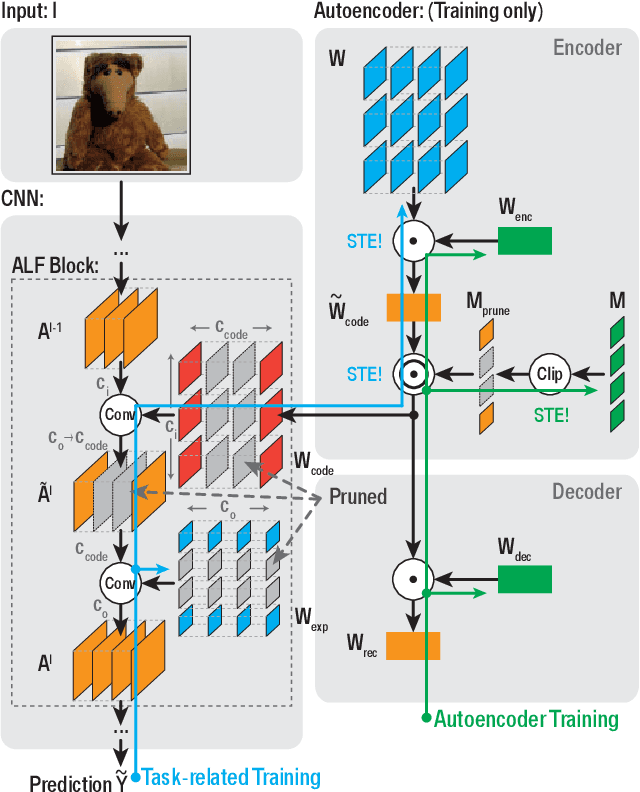
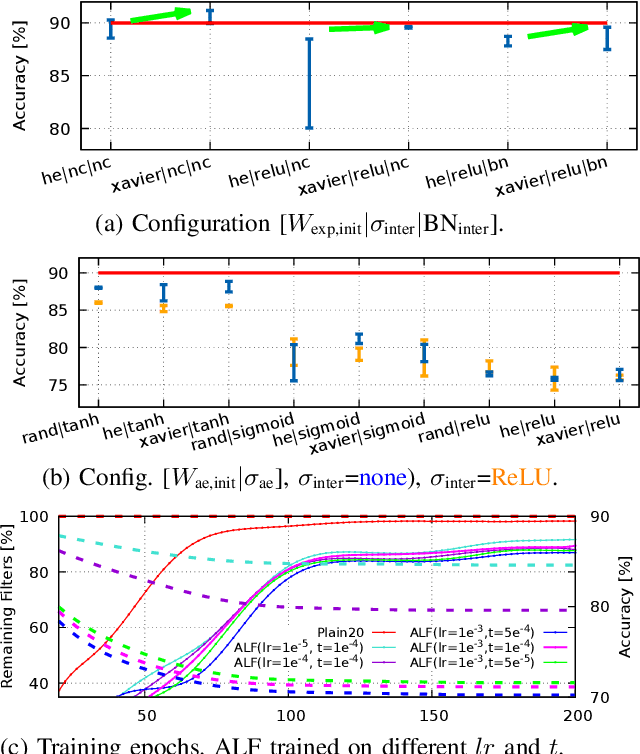

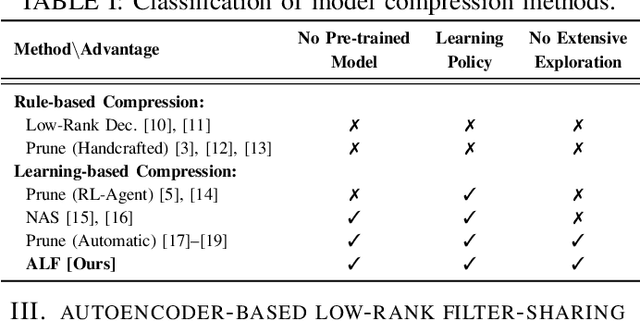
Closing the gap between the hardware requirements of state-of-the-art convolutional neural networks and the limited resources constraining embedded applications is the next big challenge in deep learning research. The computational complexity and memory footprint of such neural networks are typically daunting for deployment in resource constrained environments. Model compression techniques, such as pruning, are emphasized among other optimization methods for solving this problem. Most existing techniques require domain expertise or result in irregular sparse representations, which increase the burden of deploying deep learning applications on embedded hardware accelerators. In this paper, we propose the autoencoder-based low-rank filter-sharing technique technique (ALF). When applied to various networks, ALF is compared to state-of-the-art pruning methods, demonstrating its efficient compression capabilities on theoretical metrics as well as on an accurate, deterministic hardware-model. In our experiments, ALF showed a reduction of 70\% in network parameters, 61\% in operations and 41\% in execution time, with minimal loss in accuracy.
Binary DAD-Net: Binarized Driveable Area Detection Network for Autonomous Driving
Jun 15, 2020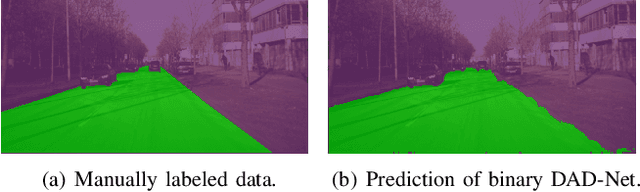
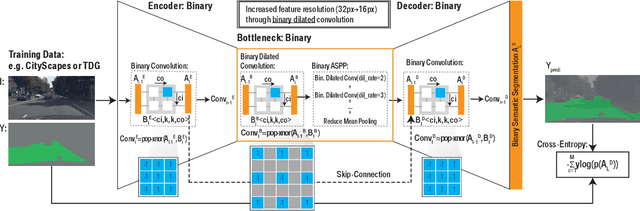
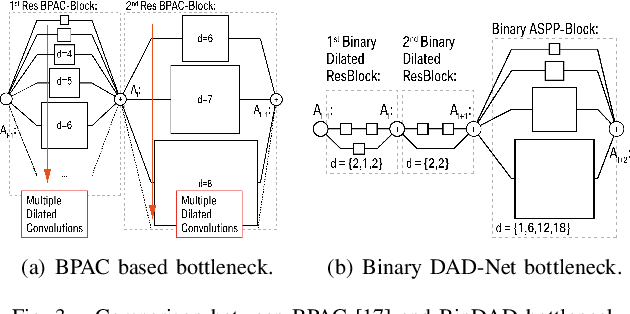

Driveable area detection is a key component for various applications in the field of autonomous driving (AD), such as ground-plane detection, obstacle detection and maneuver planning. Additionally, bulky and over-parameterized networks can be easily forgone and replaced with smaller networks for faster inference on embedded systems. The driveable area detection, posed as a two class segmentation task, can be efficiently modeled with slim binary networks. This paper proposes a novel binarized driveable area detection network (binary DAD-Net), which uses only binary weights and activations in the encoder, the bottleneck, and the decoder part. The latent space of the bottleneck is efficiently increased (x32 -> x16 downsampling) through binary dilated convolutions, learning more complex features. Along with automatically generated training data, the binary DAD-Net outperforms state-of-the-art semantic segmentation networks on public datasets. In comparison to a full-precision model, our approach has a x14.3 reduced compute complexity on an FPGA and it requires only 0.9MB memory resources. Therefore, commodity SIMD-based AD-hardware is capable of accelerating the binary DAD-Net.
An Empirical Evaluation Study on the Training of SDC Features for Dense Pixel Matching
Apr 12, 2019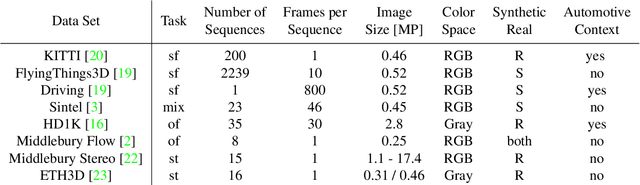


Training a deep neural network is a non-trivial task. Not only the tuning of hyperparameters, but also the gathering and selection of training data, the design of the loss function, and the construction of training schedules is important to get the most out of a model. In this study, we perform a set of experiments all related to these issues. The model for which different training strategies are investigated is the recently presented SDC descriptor network (stacked dilated convolution). It is used to describe images on pixel-level for dense matching tasks. Our work analyzes SDC in more detail, validates some best practices for training deep neural networks, and provides insights into training with multiple domain data.
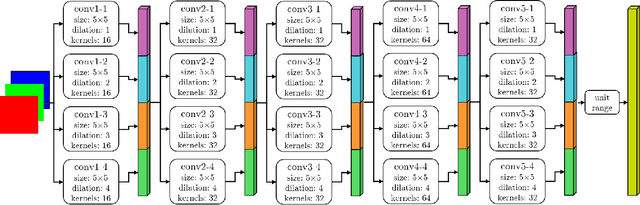
SDC - Stacked Dilated Convolution: A Unified Descriptor Network for Dense Matching Tasks
Apr 05, 2019



Dense pixel matching is important for many computer vision tasks such as disparity and flow estimation. We present a robust, unified descriptor network that considers a large context region with high spatial variance. Our network has a very large receptive field and avoids striding layers to maintain spatial resolution. These properties are achieved by creating a novel neural network layer that consists of multiple, parallel, stacked dilated convolutions (SDC). Several of these layers are combined to form our SDC descriptor network. In our experiments, we show that our SDC features outperform state-of-the-art feature descriptors in terms of accuracy and robustness. In addition, we demonstrate the superior performance of SDC in state-of-the-art stereo matching, optical flow and scene flow algorithms on several famous public benchmarks.
SceneFlowFields++: Multi-frame Matching, Visibility Prediction, and Robust Interpolation for Scene Flow Estimation
Feb 26, 2019



State-of-the-art scene flow algorithms pursue the conflicting targets of accuracy, run time, and robustness. With the successful concept of pixel-wise matching and sparse-to-dense interpolation, we push the limits of scene flow estimation. Avoiding strong assumptions on the domain or the problem yields a more robust algorithm. This algorithm is fast because we avoid explicit regularization during matching, which allows an efficient computation. Using image information from multiple time steps and explicit visibility prediction based on previous results, we achieve competitive performances on different data sets. Our contributions and results are evaluated in comparative experiments. Overall, we present an accurate scene flow algorithm that is faster and more generic than any individual benchmark leader.