 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensor Generalization for Adaptive Sensing in Event-based Object Detection via Joint Distribution Training
Feb 26, 2026Bio-inspired event cameras have recently attracted significant research due to their asynchronous and low-latency capabilities. These features provide a high dynamic range and significantly reduce motion blur. However, because of the novelty in the nature of their output signals, there is a gap in the variability of available data and a lack of extensive analysis of the parameters characterizing their signals. This paper addresses these issues by providing readers with an in-depth understanding of how intrinsic parameters affect the performance of a model trained on event data, specifically for object detection. We also use our findings to expand the capabilities of the downstream model towards sensor-agnostic robustness.
LiREC-Net: A Target-Free and Learning-Based Network for LiDAR, RGB, and Event Calibration
Feb 25, 2026Advanced autonomous systems rely on multi-sensor fusion for safer and more robust perception. To enable effective fusion, calibrating directly from natural driving scenes (i.e., target-free) with high accuracy is crucial for precise multi-sensor alignment. Existing learning-based calibration methods are typically designed for only a single pair of sensor modalities (i.e., a bi-modal setup). Unlike these methods, we propose LiREC-Net, a target-free, learning-based calibration network that jointly calibrates multiple sensor modality pairs, including LiDAR, RGB, and event data, within a unified framework. To reduce redundant computation and improve efficiency, we introduce a shared LiDAR representation that leverages features from both its 3D nature and projected depth map, ensuring better consistency across modalities. Trained and evaluated on established datasets, such as KITTI and DSEC, our LiREC-Net achieves competitive performance to bi-modal models and sets a new strong baseline for the tri-modal use case.
SF3D-RGB: Scene Flow Estimation from Monocular Camera and Sparse LiDAR
Feb 25, 2026Scene flow estimation is an extremely important task in computer vision to support the perception of dynamic changes in the scene. For robust scene flow, learning-based approaches have recently achieved impressive results using either image-based or LiDAR-based modalities. However, these methods have tended to focus on the use of a single modality. To tackle these problems, we present a deep learning architecture, SF3D-RGB, that enables sparse scene flow estimation using 2D monocular images and 3D point clouds (e.g., acquired by LiDAR) as inputs. Our architecture is an end-to-end model that first encodes information from each modality into features and fuses them together. Then, the fused features enhance a graph matching module for better and more robust mapping matrix computation to generate an initial scene flow. Finally, a residual scene flow module further refines the initial scene flow. Our model is designed to strike a balance between accuracy and efficiency. Furthermore, experiments show that our proposed method outperforms single-modality methods and achieves better scene flow accuracy on real-world datasets while using fewer parameters compared to other state-of-the-art methods with fusion.
SAILS: Segment Anything with Incrementally Learned Semantics for Task-Invariant and Training-Free Continual Learning
Feb 16, 2026Continual learning remains constrained by the need for repeated retraining, high computational costs, and the persistent challenge of forgetting. These factors significantly limit the applicability of continuous learning in real-world settings, as iterative model updates require significant computational resources and inherently exacerbate forgetting. We present SAILS -- Segment Anything with Incrementally Learned Semantics, a training-free framework for Class-Incremental Semantic Segmentation (CISS) that sidesteps these challenges entirely. SAILS leverages foundational models to decouple CISS into two stages: Zero-shot region extraction using Segment Anything Model (SAM), followed by semantic association through prototypes in a fixed feature space. SAILS incorporates selective intra-class clustering, resulting in multiple prototypes per class to better model intra-class variability. Our results demonstrate that, despite requiring no incremental training, SAILS typically surpasses the performance of existing training-based approaches on standard CISS datasets, particularly in long and challenging task sequences where forgetting tends to be most severe. By avoiding parameter updates, SAILS completely eliminates forgetting and maintains consistent, task-invariant performance. Furthermore, SAILS exhibits positive backward transfer, where the introduction of new classes can enhance performance on previous classes.
Domain-Incremental Semantic Segmentation for Autonomous Driving under Adverse Driving Conditions
Jan 09, 2025



Semantic segmentation for autonomous driving is an even more challenging task when faced with adverse driving conditions. Standard models trained on data recorded under ideal conditions show a deteriorated performance in unfavorable weather or illumination conditions. Fine-tuning on the new task or condition would lead to overwriting the previously learned information resulting in catastrophic forgetting. Adapting to the new conditions through traditional domain adaption methods improves the performance on the target domain at the expense of the source domain. Addressing these issues, we propose an architecture-based domain-incremental learning approach called Progressive Semantic Segmentation (PSS). PSS is a task-agnostic, dynamically growing collection of domain-specific segmentation models. The task of inferring the domain and subsequently selecting the appropriate module for segmentation is carried out using a collection of convolutional autoencoders. We extensively evaluate our proposed approach using several datasets at varying levels of granularity in the categorization of adverse driving conditions. Furthermore, we demonstrate the generalization of the proposed approach to similar and unseen domains.
Modality-Incremental Learning with Disjoint Relevance Mapping Networks for Image-based Semantic Segmentation
Nov 26, 2024



In autonomous driving, environment perception has significantly advanced with the utilization of deep learning techniques for diverse sensors such as cameras, depth sensors, or infrared sensors. The diversity in the sensor stack increases the safety and contributes to robustness against adverse weather and lighting conditions. However, the variance in data acquired from different sensors poses challenges. In the context of continual learning (CL), incremental learning is especially challenging for considerably large domain shifts, e.g. different sensor modalities. This amplifies the problem of catastrophic forgetting. To address this issue, we formulate the concept of modality-incremental learning and examine its necessity, by contrasting it with existing incremental learning paradigms. We propose the use of a modified Relevance Mapping Network (RMN) to incrementally learn new modalities while preserving performance on previously learned modalities, in which relevance maps are disjoint. Experimental results demonstrate that the prevention of shared connections in this approach helps alleviate the problem of forgetting within the constraints of a strict continual learning framework.
AnonyNoise: Anonymizing Event Data with Smart Noise to Outsmart Re-Identification and Preserve Privacy
Nov 25, 2024The increasing capabilities of deep neural networks for re-identification, combined with the rise in public surveillance in recent years, pose a substantial threat to individual privacy. Event cameras were initially considered as a promising solution since their output is sparse and therefore difficult for humans to interpret. However, recent advances in deep learning proof that neural networks are able to reconstruct high-quality grayscale images and re-identify individuals using data from event cameras. In our paper, we contribute a crucial ethical discussion on data privacy and present the first event anonymization pipeline to prevent re-identification not only by humans but also by neural networks. Our method effectively introduces learnable data-dependent noise to cover personally identifiable information in raw event data, reducing attackers' re-identification capabilities by up to 60%, while maintaining substantial information for the performing of downstream tasks. Moreover, our anonymization generalizes well on unseen data and is robust against image reconstruction and inversion attacks. Code: https://github.com/dfki-av/AnonyNoise
ShapeAug++: More Realistic Shape Augmentation for Event Data
Sep 17, 2024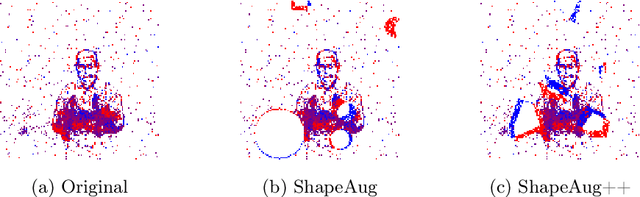
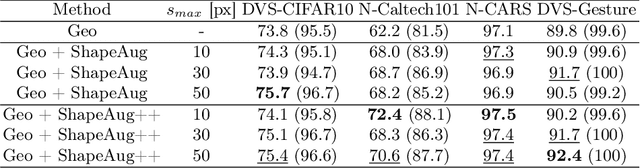
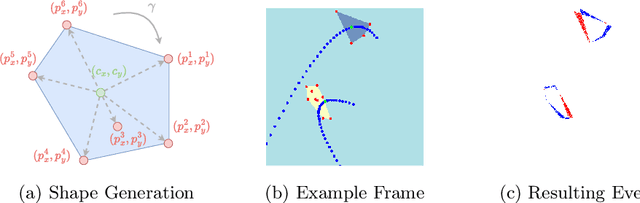
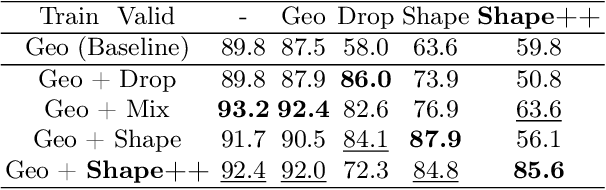
The novel Dynamic Vision Sensors (DVSs) gained a great amount of attention recently as they are superior compared to RGB cameras in terms of latency, dynamic range and energy consumption. This is particularly of interest for autonomous applications since event cameras are able to alleviate motion blur and allow for night vision. One challenge in real-world autonomous settings is occlusion where foreground objects hinder the view on traffic participants in the background. The ShapeAug method addresses this problem by using simulated events resulting from objects moving on linear paths for event data augmentation. However, the shapes and movements lack complexity, making the simulation fail to resemble the behavior of objects in the real world. Therefore in this paper, we propose ShapeAug++, an extended version of ShapeAug which involves randomly generated polygons as well as curved movements. We show the superiority of our method on multiple DVS classification datasets, improving the top-1 accuracy by up to 3.7% compared to ShapeAug.
CLEO: Continual Learning of Evolving Ontologies
Jul 11, 2024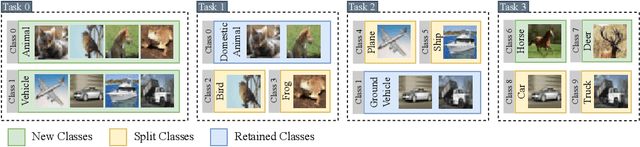
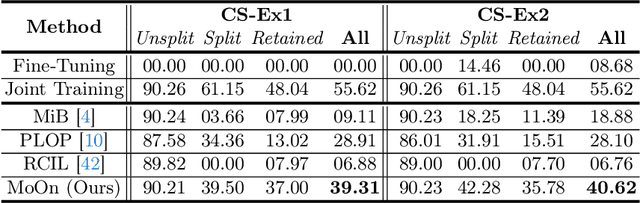

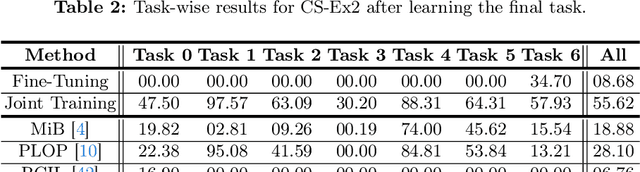
Continual learning (CL) addresses the problem of catastrophic forgetting in neural networks, which occurs when a trained model tends to overwrite previously learned information, when presented with a new task. CL aims to instill the lifelong learning characteristic of humans in intelligent systems, making them capable of learning continuously while retaining what was already learned. Current CL problems involve either learning new domains (domain-incremental) or new and previously unseen classes (class-incremental). However, general learning processes are not just limited to learning information, but also refinement of existing information. In this paper, we define CLEO - Continual Learning of Evolving Ontologies, as a new incremental learning setting under CL to tackle evolving classes. CLEO is motivated by the need for intelligent systems to adapt to real-world ontologies that change over time, such as those in autonomous driving. We use Cityscapes, PASCAL VOC, and Mapillary Vistas to define the task settings and demonstrate the applicability of CLEO. We highlight the shortcomings of existing CIL methods in adapting to CLEO and propose a baseline solution, called Modelling Ontologies (MoOn). CLEO is a promising new approach to CL that addresses the challenge of evolving ontologies in real-world applications. MoOn surpasses previous CL approaches in the context of CLEO.
EgoFlowNet: Non-Rigid Scene Flow from Point Clouds with Ego-Motion Support
Jul 03, 2024Recent weakly-supervised methods for scene flow estimation from LiDAR point clouds are limited to explicit reasoning on object-level. These methods perform multiple iterative optimizations for each rigid object, which makes them vulnerable to clustering robustness. In this paper, we propose our EgoFlowNet - a point-level scene flow estimation network trained in a weakly-supervised manner and without object-based abstraction. Our approach predicts a binary segmentation mask that implicitly drives two parallel branches for ego-motion and scene flow. Unlike previous methods, we provide both branches with all input points and carefully integrate the binary mask into the feature extraction and losses. We also use a shared cost volume with local refinement that is updated at multiple scales without explicit clustering or rigidity assumptions. On realistic KITTI scenes, we show that our EgoFlowNet performs better than state-of-the-art methods in the presence of ground surface points.