 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Fusion: 3D Object Detection using Calibration-Free Transformer Feature Fusion
Dec 14, 2023



The state of the art in 3D object detection using sensor fusion heavily relies on calibration quality, which is difficult to maintain in large scale deployment outside a lab environment. We present the first calibration-free approach for 3D object detection. Thus, eliminating the need for complex and costly calibration procedures. Our approach uses transformers to map the features between multiple views of different sensors at multiple abstraction levels. In an extensive evaluation for object detection, we not only show that our approach outperforms single modal setups by 14.1% in BEV mAP, but also that the transformer indeed learns mapping. By showing calibration is not necessary for sensor fusion, we hope to motivate other researchers following the direction of calibration-free fusion. Additionally, resulting approaches have a substantial resilience against rotation and translation changes.
Object Permanence in Object Detection Leveraging Temporal Priors at Inference Time
Nov 28, 2022Object permanence is the concept that objects do not suddenly disappear in the physical world. Humans understand this concept at young ages and know that another person is still there, even though it is temporarily occluded. Neural networks currently often struggle with this challenge. Thus, we introduce explicit object permanence into two stage detection approaches drawing inspiration from particle filters. At the core, our detector uses the predictions of previous frames as additional proposals for the current one at inference time. Experiments confirm the feedback loop improving detection performance by a up to 10.3 mAP with little computational overhead. Our approach is suited to extend two-stage detectors for stabilized and reliable detections even under heavy occlusion. Additionally, the ability to apply our method without retraining an existing model promises wide application in real-world tasks.
HPERL: 3D Human Pose Estimation from RGB and LiDAR
Oct 16, 2020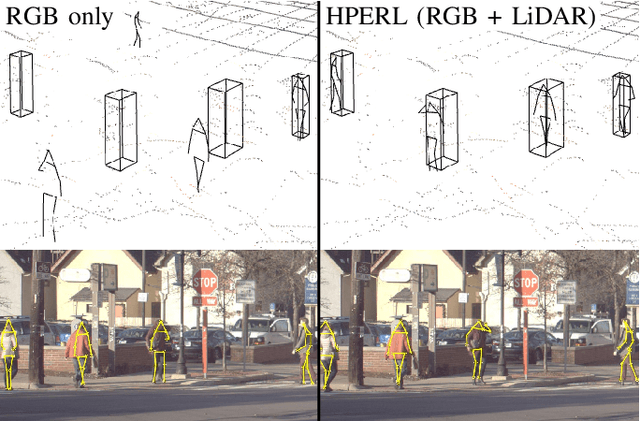
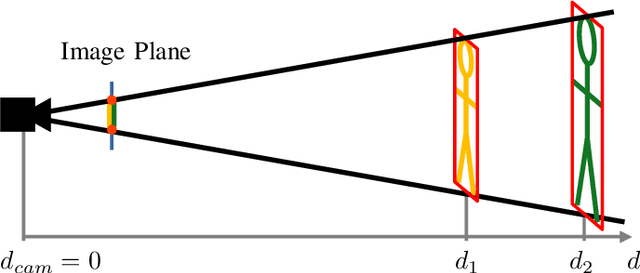
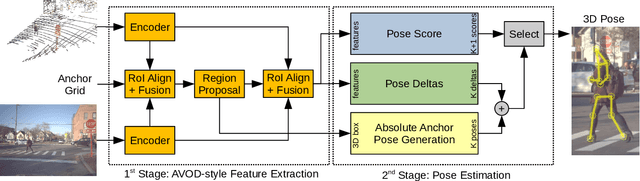
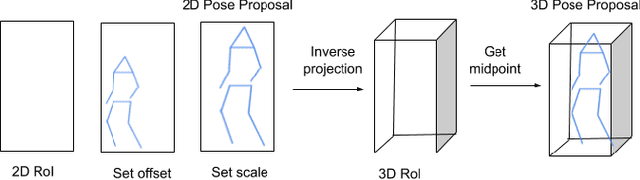
In-the-wild human pose estimation has a huge potential for various fields, ranging from animation and action recognition to intention recognition and prediction for autonomous driving. The current state-of-the-art is focused only on RGB and RGB-D approaches for predicting the 3D human pose. However, not using precise LiDAR depth information limits the performance and leads to very inaccurate absolute pose estimation. With LiDAR sensors becoming more affordable and common on robots and autonomous vehicle setups, we propose an end-to-end architecture using RGB and LiDAR to predict the absolute 3D human pose with unprecedented precision. Additionally, we introduce a weakly-supervised approach to generate 3D predictions using 2D pose annotations from PedX [1]. This allows for many new opportunities in the field of 3D human pose estimation.
LRPD: Long Range 3D Pedestrian Detection Leveraging Specific Strengths of LiDAR and RGB
Jun 17, 2020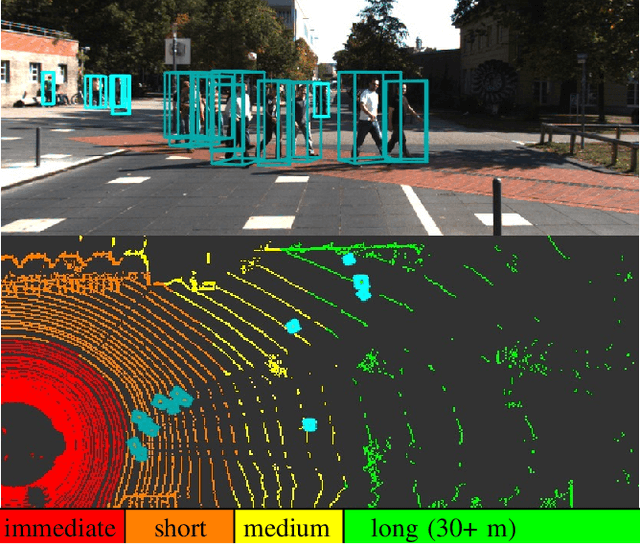
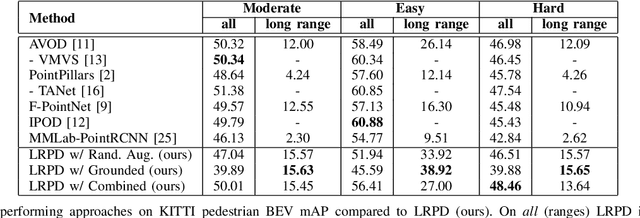
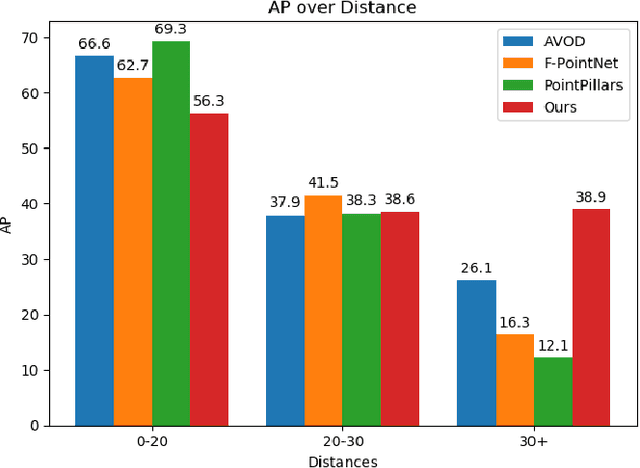
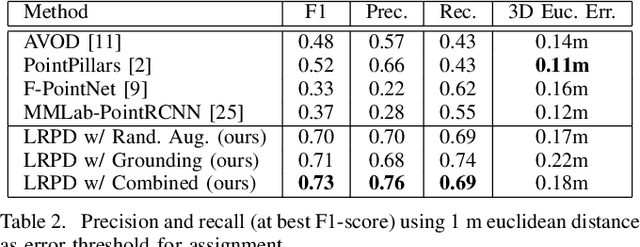
While short range 3D pedestrian detection is sufficient for emergency breaking, long range detections are required for smooth breaking and gaining trust in autonomous vehicles. The current state-of-the-art on the KITTI benchmark performs suboptimal in detecting the position of pedestrians at long range. Thus, we propose an approach specifically targeting long range 3D pedestrian detection (LRPD), leveraging the density of RGB and the precision of LiDAR. Therefore, for proposals, RGB instance segmentation and LiDAR point based proposal generation are combined, followed by a second stage using both sensor modalities symmetrically. This leads to a significant improvement in mAP on long range compared to the current state-of-the art. The evaluation of our LRPD approach was done on the pedestrians from the KITTI benchmark.
Automated Focal Loss for Image based Object Detection
Apr 19, 2019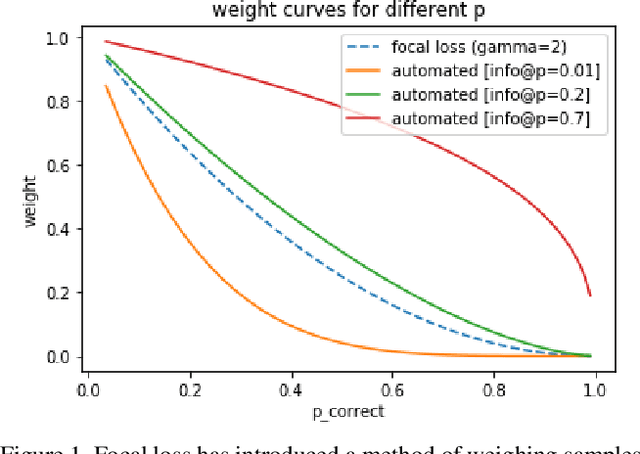
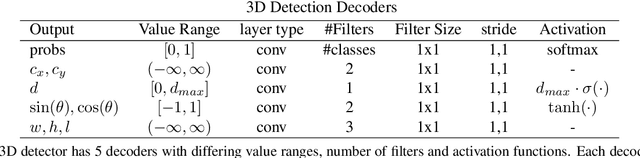
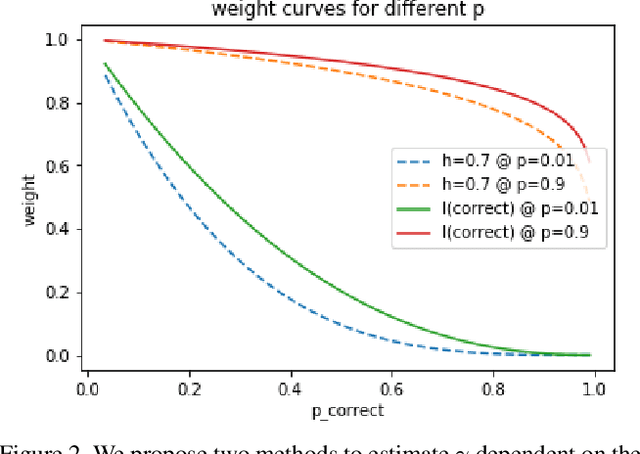
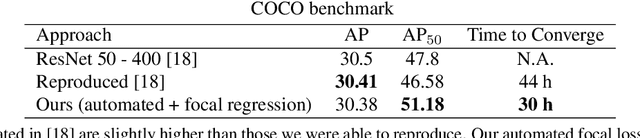
Current state-of-the-art object detection algorithms still suffer the problem of imbalanced distribution of training data over object classes and background. Recent work introduced a new loss function called focal loss to mitigate this problem, but at the cost of an additional hyperparameter. Manually tuning this hyperparameter for each training task is highly time-consuming. With automated focal loss we introduce a new loss function which substitutes this hyperparameter by a parameter that is automatically adapted during the training progress and controls the amount of focusing on hard training examples. We show on the COCO benchmark that this leads to an up to 30% faster training convergence. We further introduced a focal regression loss which on the more challenging task of 3D vehicle detection outperforms other loss functions by up to 1.8 AOS and can be used as a value range independent metric for regression.