 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoveal-pit inspired filtering of DVS spike response
May 29, 2021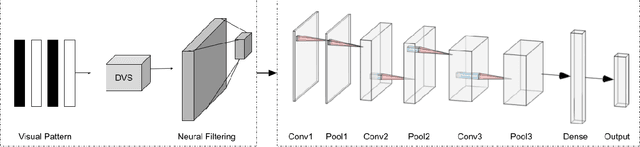
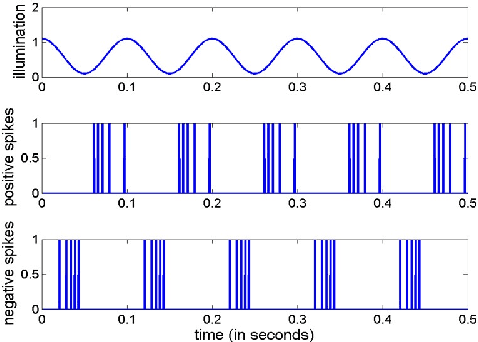

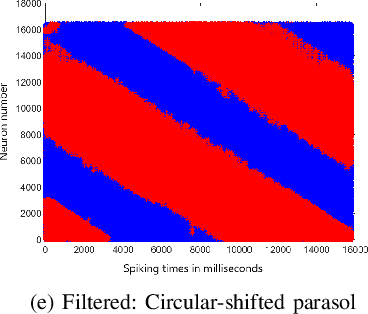
In this paper, we present results of processing Dynamic Vision Sensor (DVS) recordings of visual patterns with a retinal model based on foveal-pit inspired Difference of Gaussian (DoG) filters. A DVS sensor was stimulated with varying number of vertical white and black bars of different spatial frequencies moving horizontally at a constant velocity. The output spikes generated by the DVS sensor were applied as input to a set of DoG filters inspired by the receptive field structure of the primate visual pathway. In particular, these filters mimic the receptive fields of the midget and parasol ganglion cells (spiking neurons of the retina) that sub-serve the photo-receptors of the foveal-pit. The features extracted with the foveal-pit model are used for further classification using a spiking convolutional neural network trained with a backpropagation variant adapted for spiking neural networks.
Implementing a foveal-pit inspired filter in a Spiking Convolutional Neural Network: a preliminary study
May 29, 2021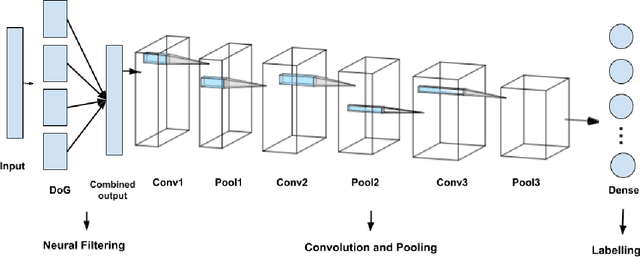



We have presented a Spiking Convolutional Neural Network (SCNN) that incorporates retinal foveal-pit inspired Difference of Gaussian filters and rank-order encoding. The model is trained using a variant of the backpropagation algorithm adapted to work with spiking neurons, as implemented in the Nengo library. We have evaluated the performance of our model on two publicly available datasets - one for digit recognition task, and the other for vehicle recognition task. The network has achieved up to 90% accuracy, where loss is calculated using the cross-entropy function. This is an improvement over around 57% accuracy obtained with the alternate approach of performing the classification without any kind of neural filtering. Overall, our proof-of-concept study indicates that introducing biologically plausible filtering in existing SCNN architecture will work well with noisy input images such as those in our vehicle recognition task. Based on our results, we plan to enhance our SCNN by integrating lateral inhibition-based redundancy reduction prior to rank-ordering, which will further improve the classification accuracy by the network.
HPERL: 3D Human Pose Estimation from RGB and LiDAR
Oct 16, 2020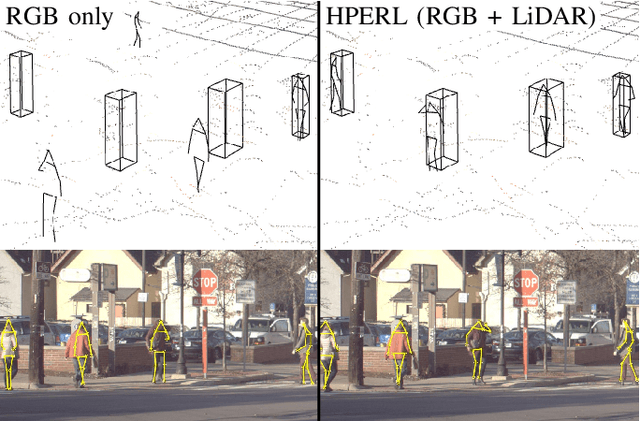
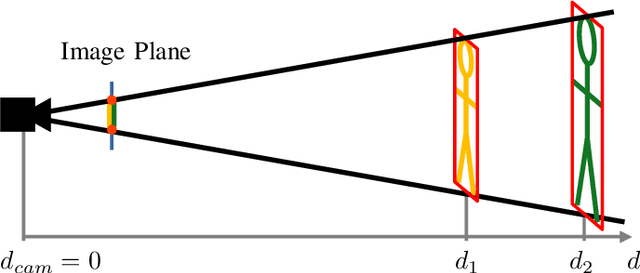
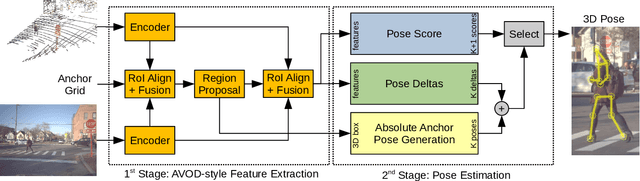
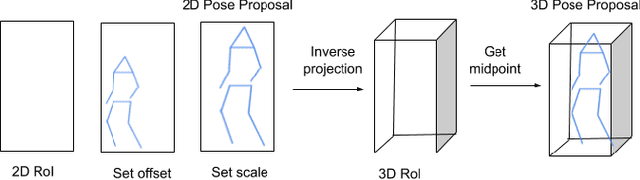
In-the-wild human pose estimation has a huge potential for various fields, ranging from animation and action recognition to intention recognition and prediction for autonomous driving. The current state-of-the-art is focused only on RGB and RGB-D approaches for predicting the 3D human pose. However, not using precise LiDAR depth information limits the performance and leads to very inaccurate absolute pose estimation. With LiDAR sensors becoming more affordable and common on robots and autonomous vehicle setups, we propose an end-to-end architecture using RGB and LiDAR to predict the absolute 3D human pose with unprecedented precision. Additionally, we introduce a weakly-supervised approach to generate 3D predictions using 2D pose annotations from PedX [1]. This allows for many new opportunities in the field of 3D human pose estimation.