 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreakingBED -- Breaking Binary and Efficient Deep Neural Networks by Adversarial Attacks
Mar 14, 2021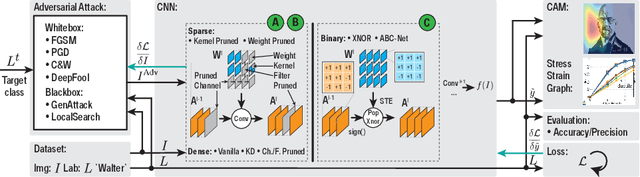
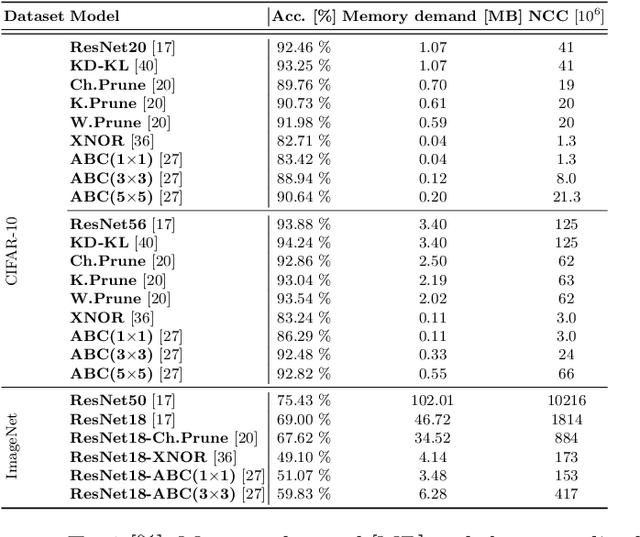
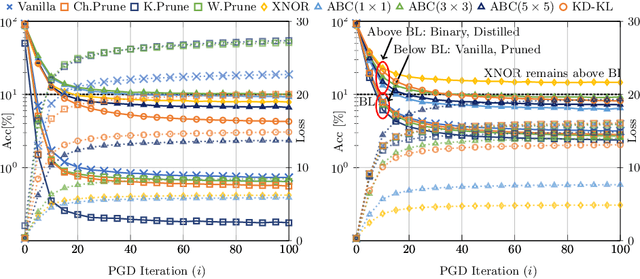
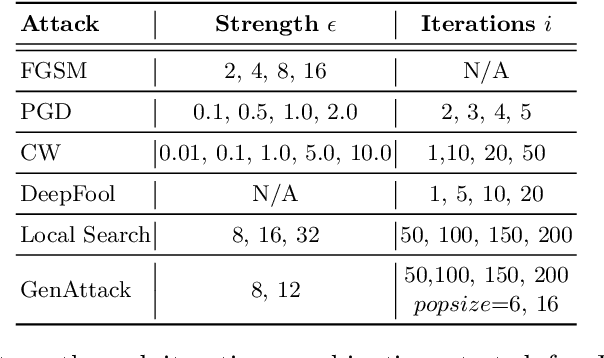
Deploying convolutional neural networks (CNNs) for embedded applications presents many challenges in balancing resource-efficiency and task-related accuracy. These two aspects have been well-researched in the field of CNN compression. In real-world applications, a third important aspect comes into play, namely the robustness of the CNN. In this paper, we thoroughly study the robustness of uncompressed, distilled, pruned and binarized neural networks against white-box and black-box adversarial attacks (FGSM, PGD, C&W, DeepFool, LocalSearch and GenAttack). These new insights facilitate defensive training schemes or reactive filtering methods, where the attack is detected and the input is discarded and/or cleaned. Experimental results are shown for distilled CNNs, agent-based state-of-the-art pruned models, and binarized neural networks (BNNs) such as XNOR-Net and ABC-Net, trained on CIFAR-10 and ImageNet datasets. We present evaluation methods to simplify the comparison between CNNs under different attack schemes using loss/accuracy levels, stress-strain graphs, box-plots and class activation mapping (CAM). Our analysis reveals susceptible behavior of uncompressed and pruned CNNs against all kinds of attacks. The distilled models exhibit their strength against all white box attacks with an exception of C&W. Furthermore, binary neural networks exhibit resilient behavior compared to their baselines and other compressed variants.
Binary DAD-Net: Binarized Driveable Area Detection Network for Autonomous Driving
Jun 15, 2020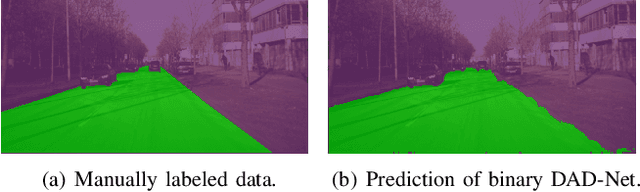
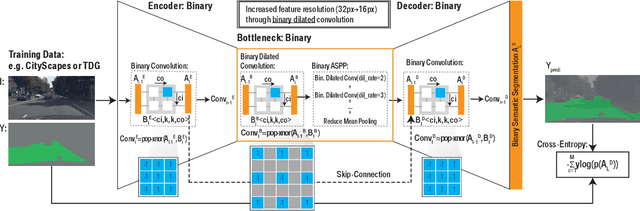
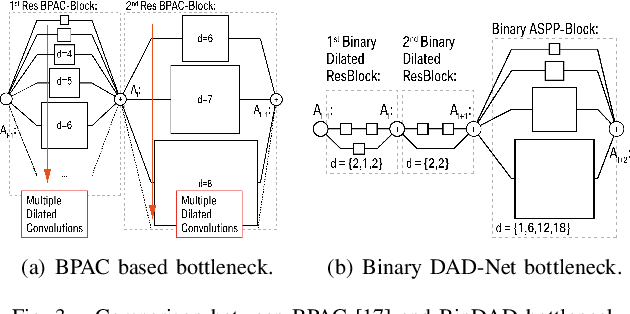

Driveable area detection is a key component for various applications in the field of autonomous driving (AD), such as ground-plane detection, obstacle detection and maneuver planning. Additionally, bulky and over-parameterized networks can be easily forgone and replaced with smaller networks for faster inference on embedded systems. The driveable area detection, posed as a two class segmentation task, can be efficiently modeled with slim binary networks. This paper proposes a novel binarized driveable area detection network (binary DAD-Net), which uses only binary weights and activations in the encoder, the bottleneck, and the decoder part. The latent space of the bottleneck is efficiently increased (x32 -> x16 downsampling) through binary dilated convolutions, learning more complex features. Along with automatically generated training data, the binary DAD-Net outperforms state-of-the-art semantic segmentation networks on public datasets. In comparison to a full-precision model, our approach has a x14.3 reduced compute complexity on an FPGA and it requires only 0.9MB memory resources. Therefore, commodity SIMD-based AD-hardware is capable of accelerating the binary DAD-Net.