 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHub.ai: A Simple, Standardized, and Reproducible Platform for AI Models in Medical Imaging
Jan 15, 2026Artificial intelligence (AI) has the potential to transform medical imaging by automating image analysis and accelerating clinical research. However, research and clinical use are limited by the wide variety of AI implementations and architectures, inconsistent documentation, and reproducibility issues. Here, we introduce MHub.ai, an open-source, container-based platform that standardizes access to AI models with minimal configuration, promoting accessibility and reproducibility in medical imaging. MHub.ai packages models from peer-reviewed publications into standardized containers that support direct processing of DICOM and other formats, provide a unified application interface, and embed structured metadata. Each model is accompanied by publicly available reference data that can be used to confirm model operation. MHub.ai includes an initial set of state-of-the-art segmentation, prediction, and feature extraction models for different modalities. The modular framework enables adaptation of any model and supports community contributions. We demonstrate the utility of the platform in a clinical use case through comparative evaluation of lung segmentation models. To further strengthen transparency and reproducibility, we publicly release the generated segmentations and evaluation metrics and provide interactive dashboards that allow readers to inspect individual cases and reproduce or extend our analysis. By simplifying model use, MHub.ai enables side-by-side benchmarking with identical execution commands and standardized outputs, and lowers the barrier to clinical translation.
In search of truth: Evaluating concordance of AI-based anatomy segmentation models
Dec 17, 2025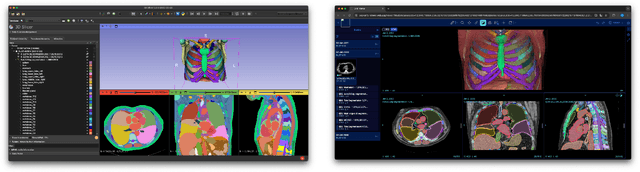


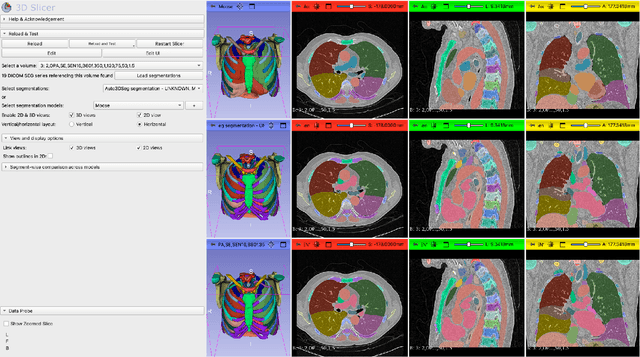
Purpose AI-based methods for anatomy segmentation can help automate characterization of large imaging datasets. The growing number of similar in functionality models raises the challenge of evaluating them on datasets that do not contain ground truth annotations. We introduce a practical framework to assist in this task. Approach We harmonize the segmentation results into a standard, interoperable representation, which enables consistent, terminology-based labeling of the structures. We extend 3D Slicer to streamline loading and comparison of these harmonized segmentations, and demonstrate how standard representation simplifies review of the results using interactive summary plots and browser-based visualization using OHIF Viewer. To demonstrate the utility of the approach we apply it to evaluating segmentation of 31 anatomical structures (lungs, vertebrae, ribs, and heart) by six open-source models - TotalSegmentator 1.5 and 2.6, Auto3DSeg, MOOSE, MultiTalent, and CADS - for a sample of Computed Tomography (CT) scans from the publicly available National Lung Screening Trial (NLST) dataset. Results We demonstrate the utility of the framework in enabling automating loading, structure-wise inspection and comparison across models. Preliminary results ascertain practical utility of the approach in allowing quick detection and review of problematic results. The comparison shows excellent agreement segmenting some (e.g., lung) but not all structures (e.g., some models produce invalid vertebrae or rib segmentations). Conclusions The resources developed are linked from https://imagingdatacommons.github.io/segmentation-comparison/ including segmentation harmonization scripts, summary plots, and visualization tools. This work assists in model evaluation in absence of ground truth, ultimately enabling informed model selection.
Benchmarking of Deep Learning Methods for Generic MRI Multi-OrganAbdominal Segmentation
Jul 23, 2025Recent advances in deep learning have led to robust automated tools for segmentation of abdominal computed tomography (CT). Meanwhile, segmentation of magnetic resonance imaging (MRI) is substantially more challenging due to the inherent signal variability and the increased effort required for annotating training datasets. Hence, existing approaches are trained on limited sets of MRI sequences, which might limit their generalizability. To characterize the landscape of MRI abdominal segmentation tools, we present here a comprehensive benchmarking of the three state-of-the-art and open-source models: MRSegmentator, MRISegmentator-Abdomen, and TotalSegmentator MRI. Since these models are trained using labor-intensive manual annotation cycles, we also introduce and evaluate ABDSynth, a SynthSeg-based model purely trained on widely available CT segmentations (no real images). More generally, we assess accuracy and generalizability by leveraging three public datasets (not seen by any of the evaluated methods during their training), which span all major manufacturers, five MRI sequences, as well as a variety of subject conditions, voxel resolutions, and fields-of-view. Our results reveal that MRSegmentator achieves the best performance and is most generalizable. In contrast, ABDSynth yields slightly less accurate results, but its relaxed requirements in training data make it an alternative when the annotation budget is limited. The evaluation code and datasets are given for future benchmarking at https://github.com/deepakri201/AbdoBench, along with inference code and weights for ABDSynth.
LNQ 2023 challenge: Benchmark of weakly-supervised techniques for mediastinal lymph node quantification
Aug 19, 2024



Accurate assessment of lymph node size in 3D CT scans is crucial for cancer staging, therapeutic management, and monitoring treatment response. Existing state-of-the-art segmentation frameworks in medical imaging often rely on fully annotated datasets. However, for lymph node segmentation, these datasets are typically small due to the extensive time and expertise required to annotate the numerous lymph nodes in 3D CT scans. Weakly-supervised learning, which leverages incomplete or noisy annotations, has recently gained interest in the medical imaging community as a potential solution. Despite the variety of weakly-supervised techniques proposed, most have been validated only on private datasets or small publicly available datasets. To address this limitation, the Mediastinal Lymph Node Quantification (LNQ) challenge was organized in conjunction with the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023). This challenge aimed to advance weakly-supervised segmentation methods by providing a new, partially annotated dataset and a robust evaluation framework. A total of 16 teams from 5 countries submitted predictions to the validation leaderboard, and 6 teams from 3 countries participated in the evaluation phase. The results highlighted both the potential and the current limitations of weakly-supervised approaches. On one hand, weakly-supervised approaches obtained relatively good performance with a median Dice score of $61.0\%$. On the other hand, top-ranked teams, with a median Dice score exceeding $70\%$, boosted their performance by leveraging smaller but fully annotated datasets to combine weak supervision and full supervision. This highlights both the promise of weakly-supervised methods and the ongoing need for high-quality, fully annotated data to achieve higher segmentation performance.
Rule-based outlier detection of AI-generated anatomy segmentations
Jun 20, 2024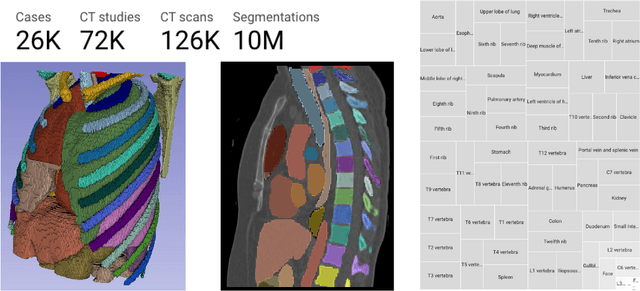
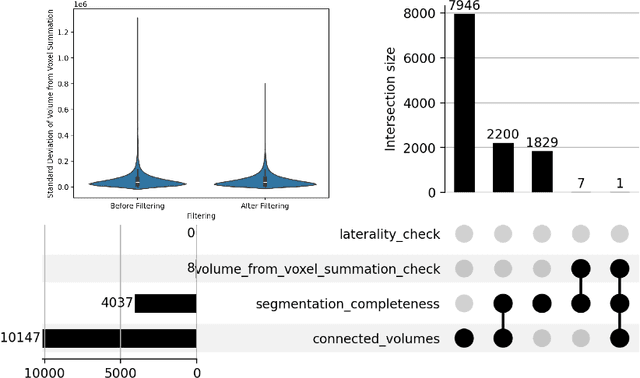
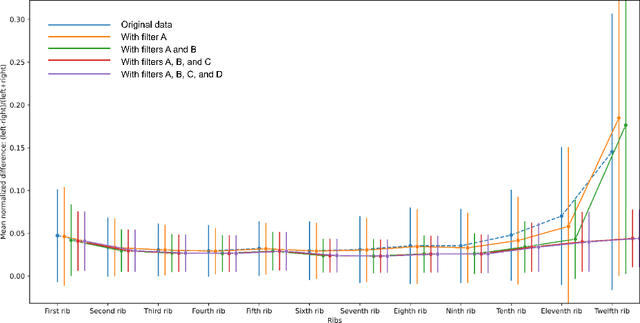
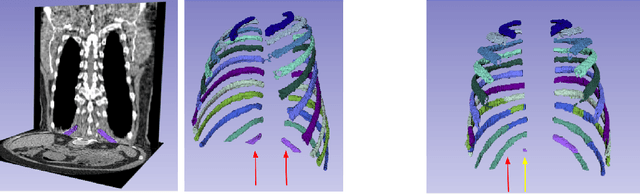
There is a dire need for medical imaging datasets with accompanying annotations to perform downstream patient analysis. However, it is difficult to manually generate these annotations, due to the time-consuming nature, and the variability in clinical conventions. Artificial intelligence has been adopted in the field as a potential method to annotate these large datasets, however, a lack of expert annotations or ground truth can inhibit the adoption of these annotations. We recently made a dataset publicly available including annotations and extracted features of up to 104 organs for the National Lung Screening Trial using the TotalSegmentator method. However, the released dataset does not include expert-derived annotations or an assessment of the accuracy of the segmentations, limiting its usefulness. We propose the development of heuristics to assess the quality of the segmentations, providing methods to measure the consistency of the annotations and a comparison of results to the literature. We make our code and related materials publicly available at https://github.com/ImagingDataCommons/CloudSegmentatorResults and interactive tools at https://huggingface.co/spaces/ImagingDataCommons/CloudSegmentatorResults.
Automatic classification of prostate MR series type using image content and metadata
Apr 16, 2024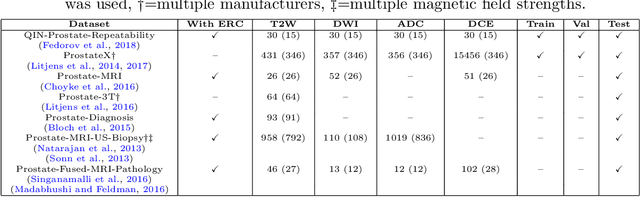

With the wealth of medical image data, efficient curation is essential. Assigning the sequence type to magnetic resonance images is necessary for scientific studies and artificial intelligence-based analysis. However, incomplete or missing metadata prevents effective automation. We therefore propose a deep-learning method for classification of prostate cancer scanning sequences based on a combination of image data and DICOM metadata. We demonstrate superior results compared to metadata or image data alone, and make our code publicly available at https://github.com/deepakri201/DICOMScanClassification.
Towards Automatic Abdominal MRI Organ Segmentation: Leveraging Synthesized Data Generated From CT Labels
Mar 22, 2024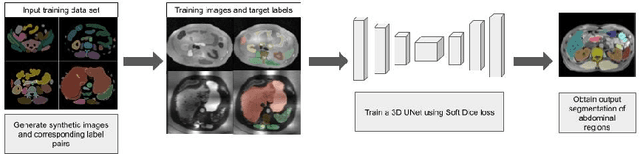

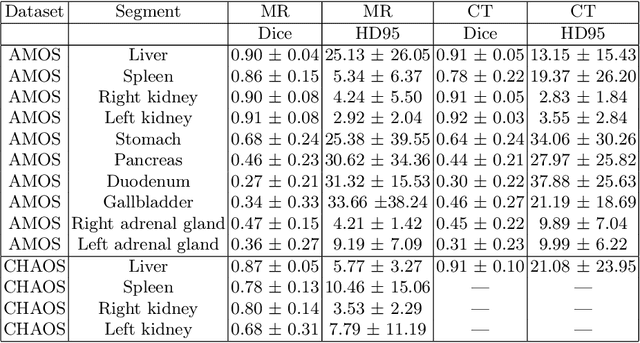
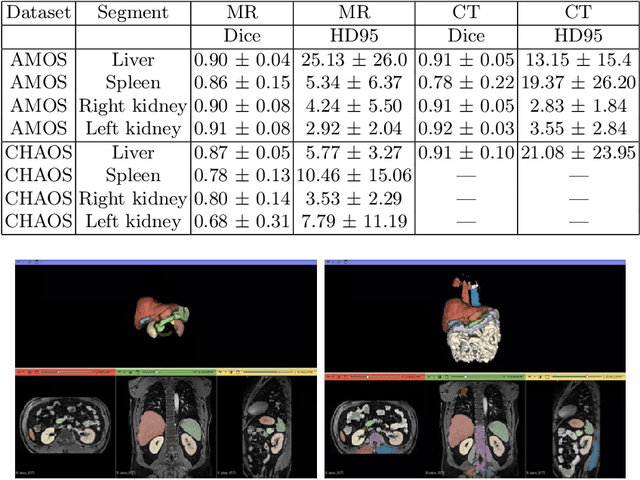
Deep learning has shown great promise in the ability to automatically annotate organs in magnetic resonance imaging (MRI) scans, for example, of the brain. However, despite advancements in the field, the ability to accurately segment abdominal organs remains difficult across MR. In part, this may be explained by the much greater variability in image appearance and severely limited availability of training labels. The inherent nature of computed tomography (CT) scans makes it easier to annotate, resulting in a larger availability of expert annotations for the latter. We leverage a modality-agnostic domain randomization approach, utilizing CT label maps to generate synthetic images on-the-fly during training, further used to train a U-Net segmentation network for abdominal organs segmentation. Our approach shows comparable results compared to fully-supervised segmentation methods trained on MR data. Our method results in Dice scores of 0.90 (0.08) and 0.91 (0.08) for the right and left kidney respectively, compared to a pretrained nnU-Net model yielding 0.87 (0.20) and 0.91 (0.03). We will make our code publicly available.
SlicerTMS: Interactive Real-time Visualization of Transcranial Magnetic Stimulation using Augmented Reality and Deep Learning
May 23, 2023



Transcranial magnetic stimulation (TMS) is a non-invasive neuromodulation approach that effectively treats various brain disorders. One of the critical factors in the success of TMS treatment is accurate coil placement, which can be challenging, especially when targeting specific brain areas for individual patients. Calculating the optimal coil placement and the resulting electric field on the brain surface can be expensive and time-consuming. We introduce SlicerTMS, a simulation method that allows the real-time visualization of the TMS electromagnetic field within the medical imaging platform 3D Slicer. Our software leverages a 3D deep neural network, supports cloud-based inference, and includes augmented reality visualization using WebXR. We evaluate the performance of SlicerTMS with multiple hardware configurations and compare it against the existing TMS visualization application SimNIBS. All our code, data, and experiments are openly available: \url{https://github.com/lorifranke/SlicerTMS}
DeepEdit: Deep Editable Learning for Interactive Segmentation of 3D Medical Images
May 18, 2023Automatic segmentation of medical images is a key step for diagnostic and interventional tasks. However, achieving this requires large amounts of annotated volumes, which can be tedious and time-consuming task for expert annotators. In this paper, we introduce DeepEdit, a deep learning-based method for volumetric medical image annotation, that allows automatic and semi-automatic segmentation, and click-based refinement. DeepEdit combines the power of two methods: a non-interactive (i.e. automatic segmentation using nnU-Net, UNET or UNETR) and an interactive segmentation method (i.e. DeepGrow), into a single deep learning model. It allows easy integration of uncertainty-based ranking strategies (i.e. aleatoric and epistemic uncertainty computation) and active learning. We propose and implement a method for training DeepEdit by using standard training combined with user interaction simulation. Once trained, DeepEdit allows clinicians to quickly segment their datasets by using the algorithm in auto segmentation mode or by providing clicks via a user interface (i.e. 3D Slicer, OHIF). We show the value of DeepEdit through evaluation on the PROSTATEx dataset for prostate/prostatic lesions and the Multi-Atlas Labeling Beyond the Cranial Vault (BTCV) dataset for abdominal CT segmentation, using state-of-the-art network architectures as baseline for comparison. DeepEdit could reduce the time and effort annotating 3D medical images compared to DeepGrow alone. Source code is available at https://github.com/Project-MONAI/MONAILabel
The NCI Imaging Data Commons as a platform for reproducible research in computational pathology
Mar 16, 2023



Objective: Reproducibility is critical for translating machine learning-based (ML) solutions in computational pathology (CompPath) into practice. However, an increasing number of studies report difficulties in reproducing ML results. The NCI Imaging Data Commons (IDC) is a public repository of >120 cancer image collections, including >38,000 whole-slide images (WSIs), that is designed to be used with cloud-based ML services. Here, we explore the potential of the IDC to facilitate reproducibility of CompPath research. Materials and Methods: The IDC realizes the FAIR principles: All images are encoded according to the DICOM standard, persistently identified, discoverable via rich metadata, and accessible via open tools. Taking advantage of this, we implemented two experiments in which a representative ML-based method for classifying lung tumor tissue was trained and/or evaluated on different datasets from the IDC. To assess reproducibility, the experiments were run multiple times with independent but identically configured sessions of common ML services. Results: The AUC values of different runs of the same experiment were generally consistent and in the same order of magnitude as a similar, previously published study. However, there were occasional small variations in AUC values of up to 0.044, indicating a practical limit to reproducibility. Discussion and conclusion: By realizing the FAIR principles, the IDC enables other researchers to reuse exactly the same datasets. Cloud-based ML services enable others to run CompPath experiments in an identically configured computing environment without having to own high-performance hardware. The combination of both makes it possible to approach the reproducibility limit.