 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-based outlier detection of AI-generated anatomy segmentations
Jun 20, 2024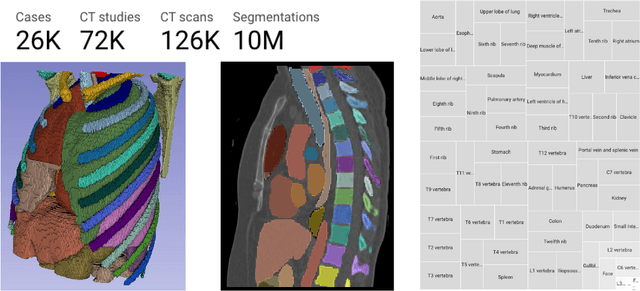
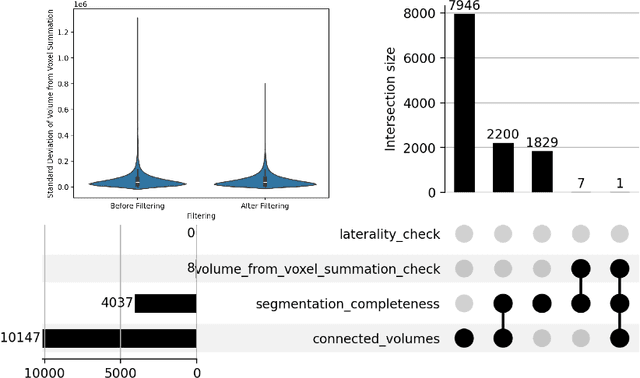
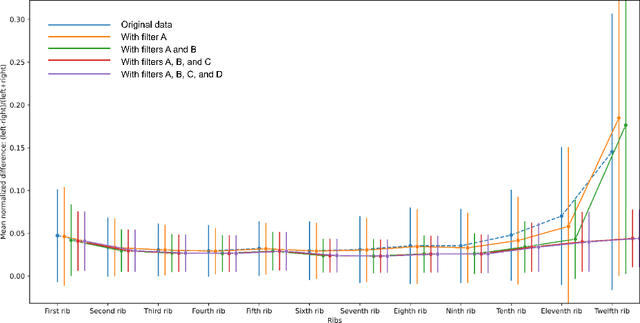
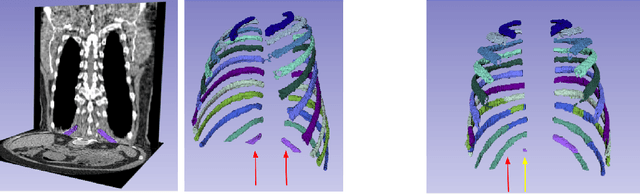
There is a dire need for medical imaging datasets with accompanying annotations to perform downstream patient analysis. However, it is difficult to manually generate these annotations, due to the time-consuming nature, and the variability in clinical conventions. Artificial intelligence has been adopted in the field as a potential method to annotate these large datasets, however, a lack of expert annotations or ground truth can inhibit the adoption of these annotations. We recently made a dataset publicly available including annotations and extracted features of up to 104 organs for the National Lung Screening Trial using the TotalSegmentator method. However, the released dataset does not include expert-derived annotations or an assessment of the accuracy of the segmentations, limiting its usefulness. We propose the development of heuristics to assess the quality of the segmentations, providing methods to measure the consistency of the annotations and a comparison of results to the literature. We make our code and related materials publicly available at https://github.com/ImagingDataCommons/CloudSegmentatorResults and interactive tools at https://huggingface.co/spaces/ImagingDataCommons/CloudSegmentatorResults.