 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHub.ai: A Simple, Standardized, and Reproducible Platform for AI Models in Medical Imaging
Jan 15, 2026Artificial intelligence (AI) has the potential to transform medical imaging by automating image analysis and accelerating clinical research. However, research and clinical use are limited by the wide variety of AI implementations and architectures, inconsistent documentation, and reproducibility issues. Here, we introduce MHub.ai, an open-source, container-based platform that standardizes access to AI models with minimal configuration, promoting accessibility and reproducibility in medical imaging. MHub.ai packages models from peer-reviewed publications into standardized containers that support direct processing of DICOM and other formats, provide a unified application interface, and embed structured metadata. Each model is accompanied by publicly available reference data that can be used to confirm model operation. MHub.ai includes an initial set of state-of-the-art segmentation, prediction, and feature extraction models for different modalities. The modular framework enables adaptation of any model and supports community contributions. We demonstrate the utility of the platform in a clinical use case through comparative evaluation of lung segmentation models. To further strengthen transparency and reproducibility, we publicly release the generated segmentations and evaluation metrics and provide interactive dashboards that allow readers to inspect individual cases and reproduce or extend our analysis. By simplifying model use, MHub.ai enables side-by-side benchmarking with identical execution commands and standardized outputs, and lowers the barrier to clinical translation.
Benchmarking of Deep Learning Methods for Generic MRI Multi-OrganAbdominal Segmentation
Jul 23, 2025Recent advances in deep learning have led to robust automated tools for segmentation of abdominal computed tomography (CT). Meanwhile, segmentation of magnetic resonance imaging (MRI) is substantially more challenging due to the inherent signal variability and the increased effort required for annotating training datasets. Hence, existing approaches are trained on limited sets of MRI sequences, which might limit their generalizability. To characterize the landscape of MRI abdominal segmentation tools, we present here a comprehensive benchmarking of the three state-of-the-art and open-source models: MRSegmentator, MRISegmentator-Abdomen, and TotalSegmentator MRI. Since these models are trained using labor-intensive manual annotation cycles, we also introduce and evaluate ABDSynth, a SynthSeg-based model purely trained on widely available CT segmentations (no real images). More generally, we assess accuracy and generalizability by leveraging three public datasets (not seen by any of the evaluated methods during their training), which span all major manufacturers, five MRI sequences, as well as a variety of subject conditions, voxel resolutions, and fields-of-view. Our results reveal that MRSegmentator achieves the best performance and is most generalizable. In contrast, ABDSynth yields slightly less accurate results, but its relaxed requirements in training data make it an alternative when the annotation budget is limited. The evaluation code and datasets are given for future benchmarking at https://github.com/deepakri201/AbdoBench, along with inference code and weights for ABDSynth.
Rule-based outlier detection of AI-generated anatomy segmentations
Jun 20, 2024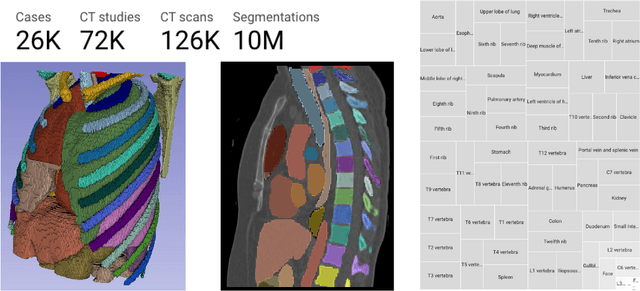
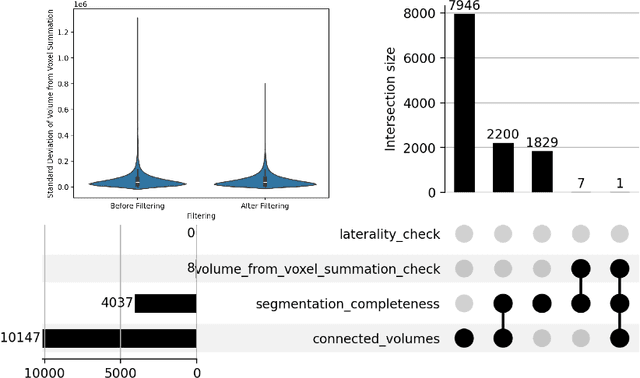
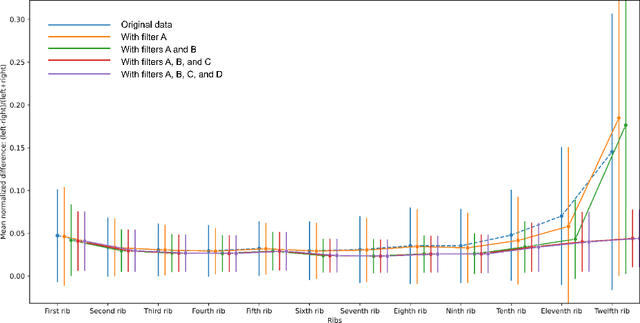
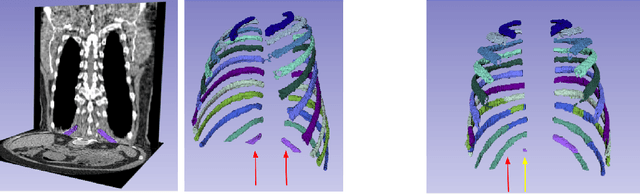
There is a dire need for medical imaging datasets with accompanying annotations to perform downstream patient analysis. However, it is difficult to manually generate these annotations, due to the time-consuming nature, and the variability in clinical conventions. Artificial intelligence has been adopted in the field as a potential method to annotate these large datasets, however, a lack of expert annotations or ground truth can inhibit the adoption of these annotations. We recently made a dataset publicly available including annotations and extracted features of up to 104 organs for the National Lung Screening Trial using the TotalSegmentator method. However, the released dataset does not include expert-derived annotations or an assessment of the accuracy of the segmentations, limiting its usefulness. We propose the development of heuristics to assess the quality of the segmentations, providing methods to measure the consistency of the annotations and a comparison of results to the literature. We make our code and related materials publicly available at https://github.com/ImagingDataCommons/CloudSegmentatorResults and interactive tools at https://huggingface.co/spaces/ImagingDataCommons/CloudSegmentatorResults.
Towards Automatic Abdominal MRI Organ Segmentation: Leveraging Synthesized Data Generated From CT Labels
Mar 22, 2024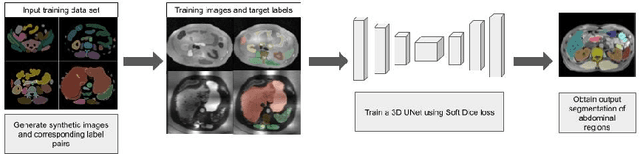

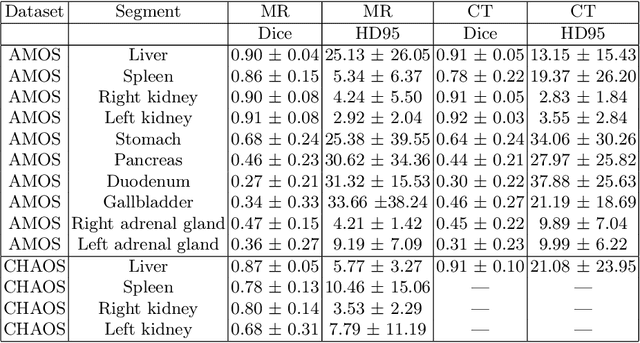
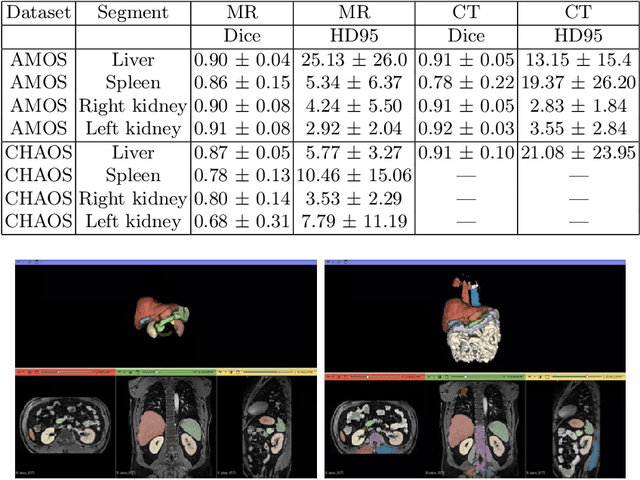
Deep learning has shown great promise in the ability to automatically annotate organs in magnetic resonance imaging (MRI) scans, for example, of the brain. However, despite advancements in the field, the ability to accurately segment abdominal organs remains difficult across MR. In part, this may be explained by the much greater variability in image appearance and severely limited availability of training labels. The inherent nature of computed tomography (CT) scans makes it easier to annotate, resulting in a larger availability of expert annotations for the latter. We leverage a modality-agnostic domain randomization approach, utilizing CT label maps to generate synthetic images on-the-fly during training, further used to train a U-Net segmentation network for abdominal organs segmentation. Our approach shows comparable results compared to fully-supervised segmentation methods trained on MR data. Our method results in Dice scores of 0.90 (0.08) and 0.91 (0.08) for the right and left kidney respectively, compared to a pretrained nnU-Net model yielding 0.87 (0.20) and 0.91 (0.03). We will make our code publicly available.