 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Medical Image Segmentation under Real-World Label Noise: A Benchmark Suite for Noisy Label Learning Method Selection
Jun 15, 2026While federated learning (FL) enables collaborative medical image segmentation without centralizing sensitive data, real-world deployment is frequently complicated by cross-site label imperfections such as contour disagreement, missing or additional structures, and confused labels. Federated noisy label learning (FNLL) aims to mitigate these effects, yet remains underused in practice as existing evidence is largely based on synthetic noise, simplified settings, and limited real-world noisy evaluation. We address this gap by introducing a benchmark suite that combines diverse real-world noisy datasets, deployment-relevant client-noise scenarios, and label-noise-targeted evaluation to support systematic FNLL assessment and informed method selection. The suite combines curated real-world noisy medical image segmentation datasets from diverse sources with a comprehensive federated segmentation framework including various client-noise scenarios and noise-targeted evaluation. The presented suite provides a realistic and discriminative basis for FNLL evaluation in medical image segmentation and establishes a reusable foundation for fair benchmarking, dataset-specific label-noise characterization, and future method development under realistic federated settings. Code is available at https://github.com/MIC-DKFZ/FedSegNoiseBench.
An Open-Source Monitoring Framework for Data Exploration and Progress Tracking in Multi-Center Radiology Studies
Jun 15, 2026Multi-center studies are crucial for advancing medical and radiological research. Data exploration, collaboration discovery, and study progress monitoring are essential for maximizing their potential. However, in practice these processes often rely on manual communication and shared tables, which quickly become outdated and hinder efficient coordination in large distributed studies. This highlights the need for dedicated monitoring solutions that provide transparent and up-to-date insights into study progress. We propose a lightweight, open-source monitoring architecture for multi-center studies based on the widely used Grafana-Prometheus stack. The framework collects aggregated monitoring metrics from distributed study sites and visualizes them through configurable dashboards. As a real-world deployment example, the framework is integrated into the medical imaging platform Kaapana and evaluated within a large multi-center research network. By deploying our solution within the Germany-wide RACOON consortium, we demonstrate its ability to enable privacy-preserving data exploration and study progress monitoring across all 38 German university clinics. The monitoring framework supports transparent coordination of distributed research activities and can facilitate more efficient management of large-scale multi-center studies. The source code and Kaapana integration are publicly available at https://github.com/MIC-DKFZ/study-monitoring-kaapana.
Kaapana: A Comprehensive Open-Source Platform for Integrating AI in Medical Imaging Research Environments
Dec 10, 2025
Developing generalizable AI for medical imaging requires both access to large, multi-center datasets and standardized, reproducible tooling within research environments. However, leveraging real-world imaging data in clinical research environments is still hampered by strict regulatory constraints, fragmented software infrastructure, and the challenges inherent in conducting large-cohort multicentre studies. This leads to projects that rely on ad-hoc toolchains that are hard to reproduce, difficult to scale beyond single institutions and poorly suited for collaboration between clinicians and data scientists. We present Kaapana, a comprehensive open-source platform for medical imaging research that is designed to bridge this gap. Rather than building single-use, site-specific tooling, Kaapana provides a modular, extensible framework that unifies data ingestion, cohort curation, processing workflows and result inspection under a common user interface. By bringing the algorithm to the data, it enables institutions to keep control over their sensitive data while still participating in distributed experimentation and model development. By integrating flexible workflow orchestration with user-facing applications for researchers, Kaapana reduces technical overhead, improves reproducibility and enables conducting large-scale, collaborative, multi-centre imaging studies. We describe the core concepts of the platform and illustrate how they can support diverse use cases, from local prototyping to nation-wide research networks. The open-source codebase is available at https://github.com/kaapana/kaapana
nnLandmark: A Self-Configuring Method for 3D Medical Landmark Detection
Apr 10, 2025Landmark detection plays a crucial role in medical imaging tasks that rely on precise spatial localization, including specific applications in diagnosis, treatment planning, image registration, and surgical navigation. However, manual annotation is labor-intensive and requires expert knowledge. While deep learning shows promise in automating this task, progress is hindered by limited public datasets, inconsistent benchmarks, and non-standardized baselines, restricting reproducibility, fair comparisons, and model generalizability. This work introduces nnLandmark, a self-configuring deep learning framework for 3D medical landmark detection, adapting nnU-Net to perform heatmap-based regression. By leveraging nnU-Net's automated configuration, nnLandmark eliminates the need for manual parameter tuning, offering out-of-the-box usability. It achieves state-of-the-art accuracy across two public datasets, with a mean radial error (MRE) of 1.5 mm on the Mandibular Molar Landmark (MML) dental CT dataset and 1.2 mm for anatomical fiducials on a brain MRI dataset (AFIDs), where nnLandmark aligns with the inter-rater variability of 1.5 mm. With its strong generalization, reproducibility, and ease of deployment, nnLandmark establishes a reliable baseline for 3D landmark detection, supporting research in anatomical localization and clinical workflows that depend on precise landmark identification. The code will be available soon.
Decoupling Semantic Similarity from Spatial Alignment for Neural Networks
Oct 30, 2024
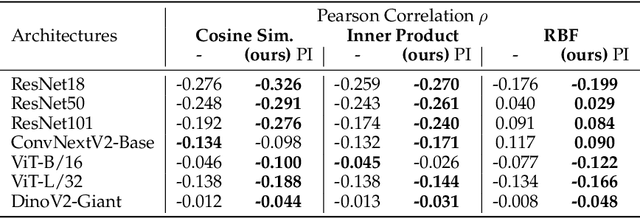
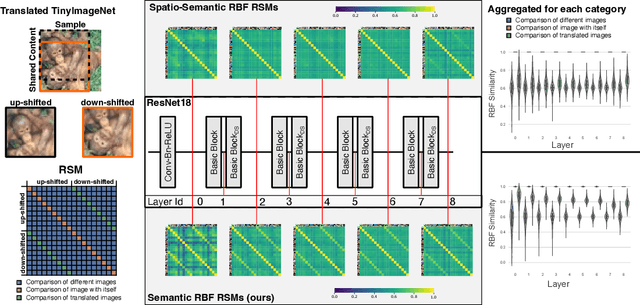

What representation do deep neural networks learn? How similar are images to each other for neural networks? Despite the overwhelming success of deep learning methods key questions about their internal workings still remain largely unanswered, due to their internal high dimensionality and complexity. To address this, one approach is to measure the similarity of activation responses to various inputs. Representational Similarity Matrices (RSMs) distill this similarity into scalar values for each input pair. These matrices encapsulate the entire similarity structure of a system, indicating which input leads to similar responses. While the similarity between images is ambiguous, we argue that the spatial location of semantic objects does neither influence human perception nor deep learning classifiers. Thus this should be reflected in the definition of similarity between image responses for computer vision systems. Revisiting the established similarity calculations for RSMs we expose their sensitivity to spatial alignment. In this paper, we propose to solve this through semantic RSMs, which are invariant to spatial permutation. We measure semantic similarity between input responses by formulating it as a set-matching problem. Further, we quantify the superiority of semantic RSMs over spatio-semantic RSMs through image retrieval and by comparing the similarity between representations to the similarity between predicted class probabilities.
Visual Prompt Engineering for Medical Vision Language Models in Radiology
Aug 28, 2024



Medical image classification in radiology faces significant challenges, particularly in generalizing to unseen pathologies. In contrast, CLIP offers a promising solution by leveraging multimodal learning to improve zero-shot classification performance. However, in the medical domain, lesions can be small and might not be well represented in the embedding space. Therefore, in this paper, we explore the potential of visual prompt engineering to enhance the capabilities of Vision Language Models (VLMs) in radiology. Leveraging BiomedCLIP, trained on extensive biomedical image-text pairs, we investigate the impact of embedding visual markers directly within radiological images to guide the model's attention to critical regions. Our evaluation on the JSRT dataset, focusing on lung nodule malignancy classification, demonstrates that incorporating visual prompts $\unicode{x2013}$ such as arrows, circles, and contours $\unicode{x2013}$ significantly improves classification metrics including AUROC, AUPRC, F1 score, and accuracy. Moreover, the study provides attention maps, showcasing enhanced model interpretability and focus on clinically relevant areas. These findings underscore the efficacy of visual prompt engineering as a straightforward yet powerful approach to advance VLM performance in medical image analysis.
Automated Ensemble Multimodal Machine Learning for Healthcare
Jul 25, 2024



The application of machine learning in medicine and healthcare has led to the creation of numerous diagnostic and prognostic models. However, despite their success, current approaches generally issue predictions using data from a single modality. This stands in stark contrast with clinician decision-making which employs diverse information from multiple sources. While several multimodal machine learning approaches exist, significant challenges in developing multimodal systems remain that are hindering clinical adoption. In this paper, we introduce a multimodal framework, AutoPrognosis-M, that enables the integration of structured clinical (tabular) data and medical imaging using automated machine learning. AutoPrognosis-M incorporates 17 imaging models, including convolutional neural networks and vision transformers, and three distinct multimodal fusion strategies. In an illustrative application using a multimodal skin lesion dataset, we highlight the importance of multimodal machine learning and the power of combining multiple fusion strategies using ensemble learning. We have open-sourced our framework as a tool for the community and hope it will accelerate the uptake of multimodal machine learning in healthcare and spur further innovation.
Real-World Federated Learning in Radiology: Hurdles to overcome and Benefits to gain
May 15, 2024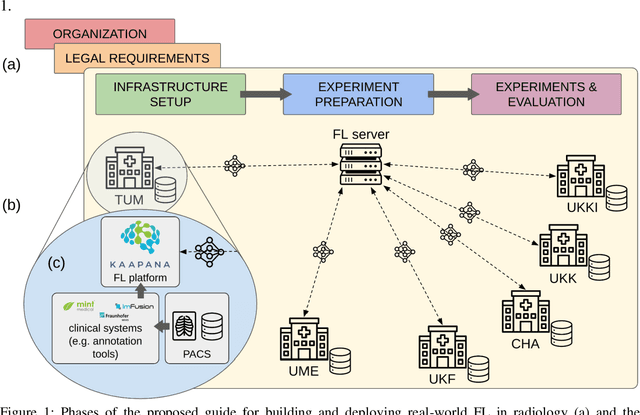



Objective: Federated Learning (FL) enables collaborative model training while keeping data locally. Currently, most FL studies in radiology are conducted in simulated environments due to numerous hurdles impeding its translation into practice. The few existing real-world FL initiatives rarely communicate specific measures taken to overcome these hurdles, leaving behind a significant knowledge gap. Minding efforts to implement real-world FL, there is a notable lack of comprehensive assessment comparing FL to less complex alternatives. Materials & Methods: We extensively reviewed FL literature, categorizing insights along with our findings according to their nature and phase while establishing a FL initiative, summarized to a comprehensive guide. We developed our own FL infrastructure within the German Radiological Cooperative Network (RACOON) and demonstrated its functionality by training FL models on lung pathology segmentation tasks across six university hospitals. We extensively evaluated FL against less complex alternatives in three distinct evaluation scenarios. Results: The proposed guide outlines essential steps, identified hurdles, and proposed solutions for establishing successful FL initiatives conducting real-world experiments. Our experimental results show that FL outperforms less complex alternatives in all evaluation scenarios, justifying the effort required to translate FL into real-world applications. Discussion & Conclusion: Our proposed guide aims to aid future FL researchers in circumventing pitfalls and accelerating translation of FL into radiological applications. Our results underscore the value of efforts needed to translate FL into real-world applications by demonstrating advantageous performance over alternatives, and emphasize the importance of strategic organization, robust management of distributed data and infrastructure in real-world settings.
Automatic classification of prostate MR series type using image content and metadata
Apr 16, 2024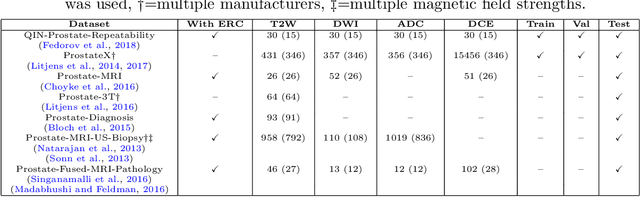

With the wealth of medical image data, efficient curation is essential. Assigning the sequence type to magnetic resonance images is necessary for scientific studies and artificial intelligence-based analysis. However, incomplete or missing metadata prevents effective automation. We therefore propose a deep-learning method for classification of prostate cancer scanning sequences based on a combination of image data and DICOM metadata. We demonstrate superior results compared to metadata or image data alone, and make our code publicly available at https://github.com/deepakri201/DICOMScanClassification.
Embarrassingly Simple Scribble Supervision for 3D Medical Segmentation
Mar 19, 2024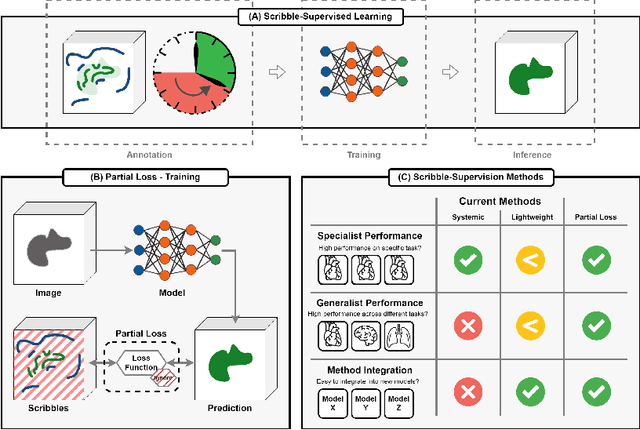
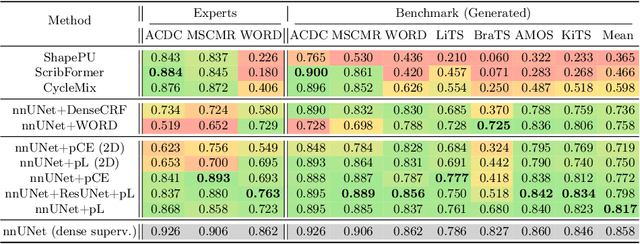
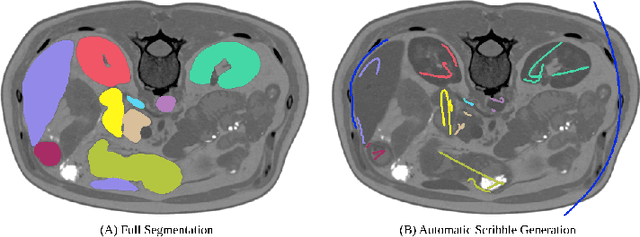

Traditionally, segmentation algorithms require dense annotations for training, demanding significant annotation efforts, particularly within the 3D medical imaging field. Scribble-supervised learning emerges as a possible solution to this challenge, promising a reduction in annotation efforts when creating large-scale datasets. Recently, a plethora of methods for optimized learning from scribbles have been proposed, but have so far failed to position scribble annotation as a beneficial alternative. We relate this shortcoming to two major issues: 1) the complex nature of many methods which deeply ties them to the underlying segmentation model, thus preventing a migration to more powerful state-of-the-art models as the field progresses and 2) the lack of a systematic evaluation to validate consistent performance across the broader medical domain, resulting in a lack of trust when applying these methods to new segmentation problems. To address these issues, we propose a comprehensive scribble supervision benchmark consisting of seven datasets covering a diverse set of anatomies and pathologies imaged with varying modalities. We furthermore propose the systematic use of partial losses, i.e. losses that are only computed on annotated voxels. Contrary to most existing methods, these losses can be seamlessly integrated into state-of-the-art segmentation methods, enabling them to learn from scribble annotations while preserving their original loss formulations. Our evaluation using nnU-Net reveals that while most existing methods suffer from a lack of generalization, the proposed approach consistently delivers state-of-the-art performance. Thanks to its simplicity, our approach presents an embarrassingly simple yet effective solution to the challenges of scribble supervision. Source code as well as our extensive scribble benchmarking suite will be made publicly available upon publication.