 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Semantic Similarity from Spatial Alignment for Neural Networks
Paper and Code

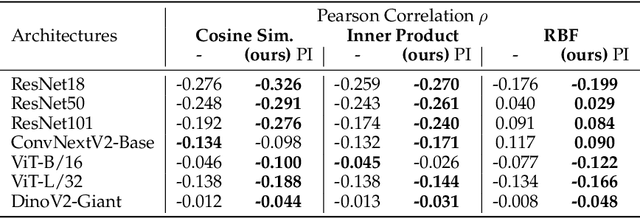
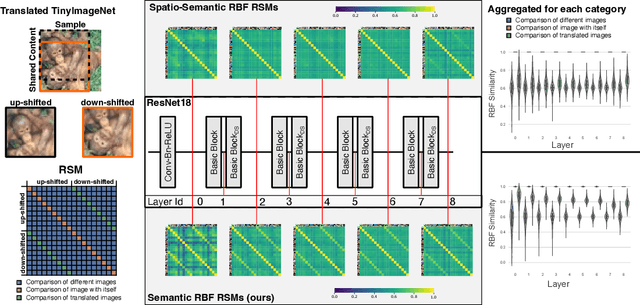

What representation do deep neural networks learn? How similar are images to each other for neural networks? Despite the overwhelming success of deep learning methods key questions about their internal workings still remain largely unanswered, due to their internal high dimensionality and complexity. To address this, one approach is to measure the similarity of activation responses to various inputs. Representational Similarity Matrices (RSMs) distill this similarity into scalar values for each input pair. These matrices encapsulate the entire similarity structure of a system, indicating which input leads to similar responses. While the similarity between images is ambiguous, we argue that the spatial location of semantic objects does neither influence human perception nor deep learning classifiers. Thus this should be reflected in the definition of similarity between image responses for computer vision systems. Revisiting the established similarity calculations for RSMs we expose their sensitivity to spatial alignment. In this paper, we propose to solve this through semantic RSMs, which are invariant to spatial permutation. We measure semantic similarity between input responses by formulating it as a set-matching problem. Further, we quantify the superiority of semantic RSMs over spatio-semantic RSMs through image retrieval and by comparing the similarity between representations to the similarity between predicted class probabilities.