 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimus: Enforcing Attention Usage for 3D Medical Image Segmentation
Mar 03, 2025
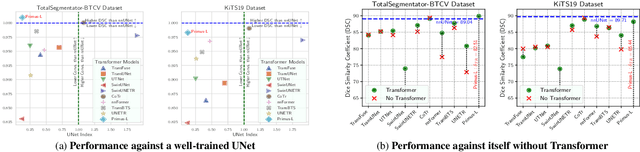
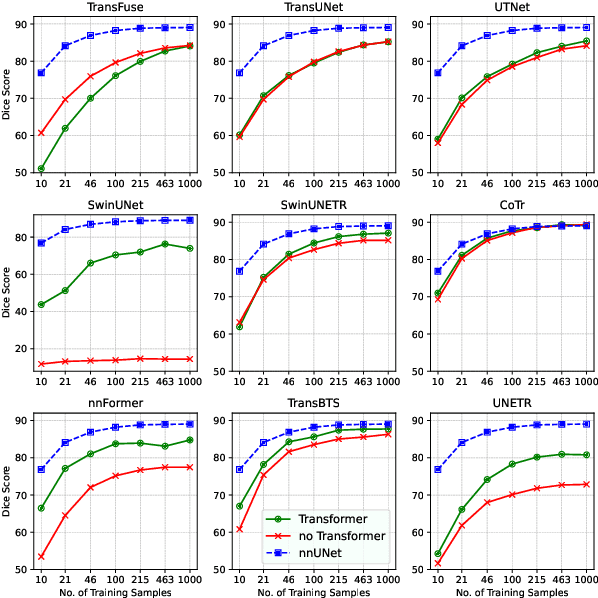
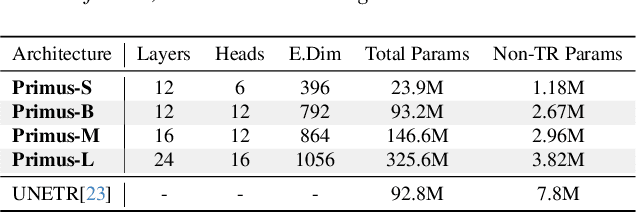
Transformers have achieved remarkable success across multiple fields, yet their impact on 3D medical image segmentation remains limited with convolutional networks still dominating major benchmarks. In this work, we a) analyze current Transformer-based segmentation models and identify critical shortcomings, particularly their over-reliance on convolutional blocks. Further, we demonstrate that in some architectures, performance is unaffected by the absence of the Transformer, thereby demonstrating their limited effectiveness. To address these challenges, we move away from hybrid architectures and b) introduce a fully Transformer-based segmentation architecture, termed Primus. Primus leverages high-resolution tokens, combined with advances in positional embeddings and block design, to maximally leverage its Transformer blocks. Through these adaptations Primus surpasses current Transformer-based methods and competes with state-of-the-art convolutional models on multiple public datasets. By doing so, we create the first pure Transformer architecture and take a significant step towards making Transformers state-of-the-art for 3D medical image segmentation.
Decoupling Semantic Similarity from Spatial Alignment for Neural Networks
Oct 30, 2024
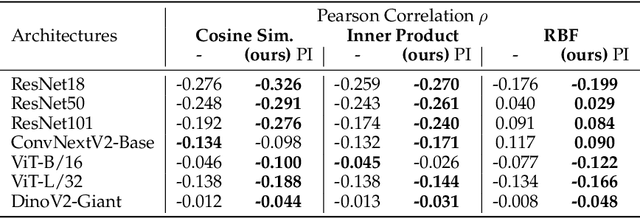
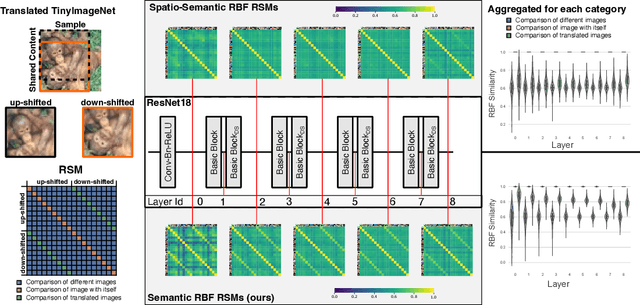

What representation do deep neural networks learn? How similar are images to each other for neural networks? Despite the overwhelming success of deep learning methods key questions about their internal workings still remain largely unanswered, due to their internal high dimensionality and complexity. To address this, one approach is to measure the similarity of activation responses to various inputs. Representational Similarity Matrices (RSMs) distill this similarity into scalar values for each input pair. These matrices encapsulate the entire similarity structure of a system, indicating which input leads to similar responses. While the similarity between images is ambiguous, we argue that the spatial location of semantic objects does neither influence human perception nor deep learning classifiers. Thus this should be reflected in the definition of similarity between image responses for computer vision systems. Revisiting the established similarity calculations for RSMs we expose their sensitivity to spatial alignment. In this paper, we propose to solve this through semantic RSMs, which are invariant to spatial permutation. We measure semantic similarity between input responses by formulating it as a set-matching problem. Further, we quantify the superiority of semantic RSMs over spatio-semantic RSMs through image retrieval and by comparing the similarity between representations to the similarity between predicted class probabilities.
Continuous-Time Deep Glioma Growth Models
Jul 02, 2021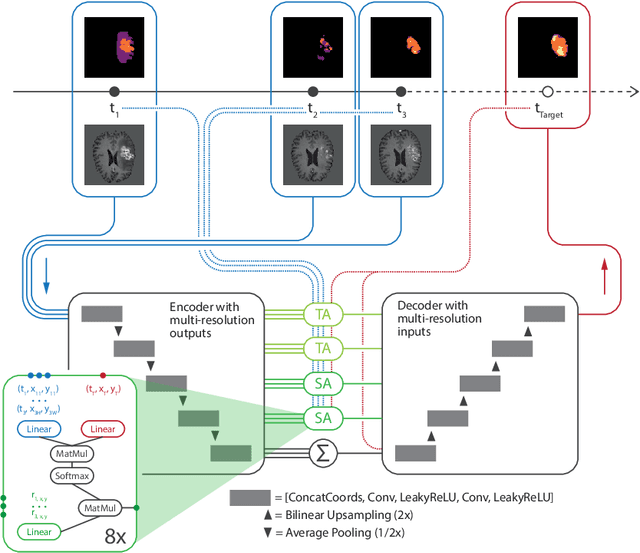


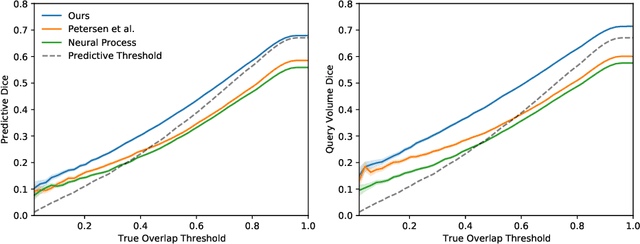
The ability to estimate how a tumor might evolve in the future could have tremendous clinical benefits, from improved treatment decisions to better dose distribution in radiation therapy. Recent work has approached the glioma growth modeling problem via deep learning and variational inference, thus learning growth dynamics entirely from a real patient data distribution. So far, this approach was constrained to predefined image acquisition intervals and sequences of fixed length, which limits its applicability in more realistic scenarios. We overcome these limitations by extending Neural Processes, a class of conditional generative models for stochastic time series, with a hierarchical multi-scale representation encoding including a spatio-temporal attention mechanism. The result is a learned growth model that can be conditioned on an arbitrary number of observations, and that can produce a distribution of temporally consistent growth trajectories on a continuous time axis. On a dataset of 379 patients, the approach successfully captures both global and finer-grained variations in the images, exhibiting superior performance compared to other learned growth models.
GP-ConvCNP: Better Generalization for Convolutional Conditional Neural Processes on Time Series Data
Jun 11, 2021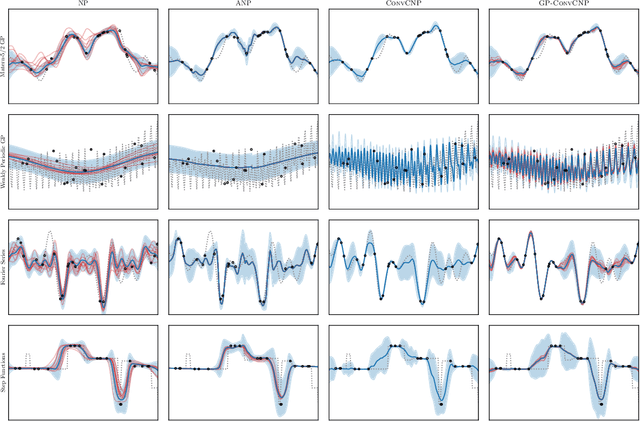
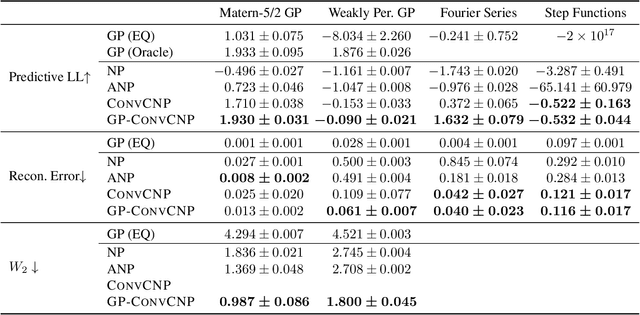
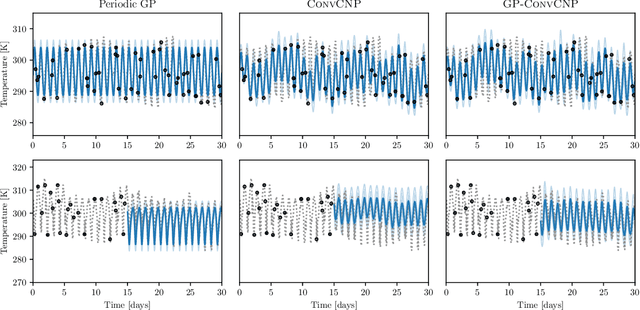
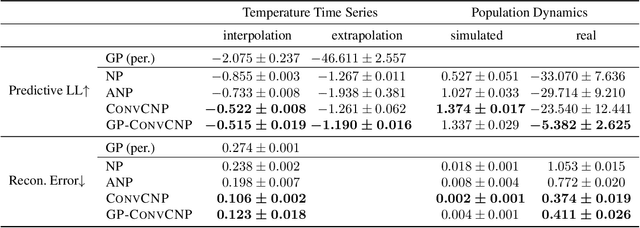
Neural Processes (NPs) are a family of conditional generative models that are able to model a distribution over functions, in a way that allows them to perform predictions at test time conditioned on a number of context points. A recent addition to this family, Convolutional Conditional Neural Processes (ConvCNP), have shown remarkable improvement in performance over prior art, but we find that they sometimes struggle to generalize when applied to time series data. In particular, they are not robust to distribution shifts and fail to extrapolate observed patterns into the future. By incorporating a Gaussian Process into the model, we are able to remedy this and at the same time improve performance within distribution. As an added benefit, the Gaussian Process reintroduces the possibility to sample from the model, a key feature of other members in the NP family.
Sample-Efficient Automated Deep Reinforcement Learning
Oct 05, 2020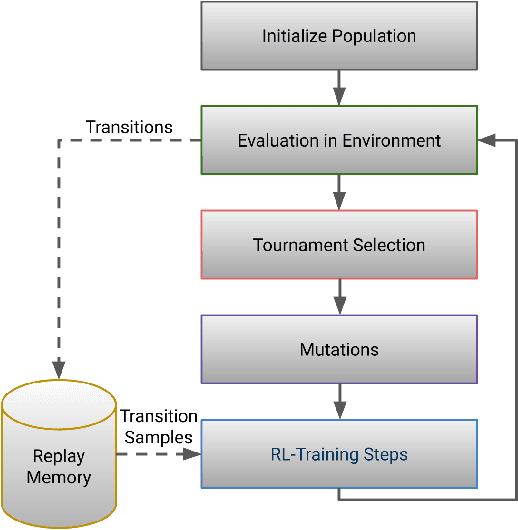


Despite significant progress in challenging problems across various domains, applying state-of-the-art deep reinforcement learning (RL) algorithms remains challenging due to their sensitivity to the choice of hyperparameters. This sensitivity can partly be attributed to the non-stationarity of the RL problem, potentially requiring different hyperparameter settings at various stages of the learning process. Additionally, in the RL setting, hyperparameter optimization (HPO) requires a large number of environment interactions, hindering the transfer of the successes in RL to real-world applications. In this work, we tackle the issues of sample-efficient and dynamic HPO in RL. We propose a population-based automated RL (AutoRL) framework to meta-optimize arbitrary off-policy RL algorithms. In this framework, we optimize the hyperparameters and also the neural architecture while simultaneously training the agent. By sharing the collected experience across the population, we substantially increase the sample efficiency of the meta-optimization. We demonstrate the capabilities of our sample-efficient AutoRL approach in a case study with the popular TD3 algorithm in the MuJoCo benchmark suite, where we reduce the number of environment interactions needed for meta-optimization by up to an order of magnitude compared to population-based training.
Neural Architecture Evolution in Deep Reinforcement Learning for Continuous Control
Dec 04, 2019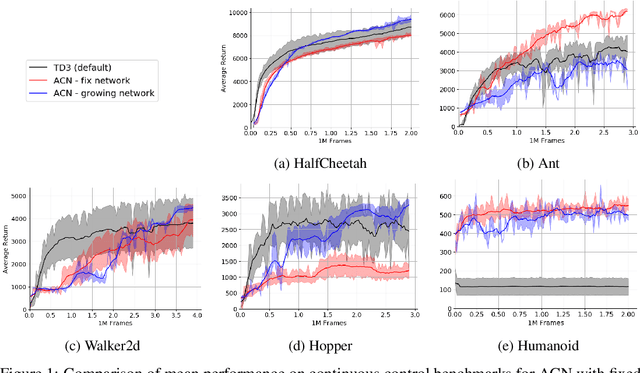
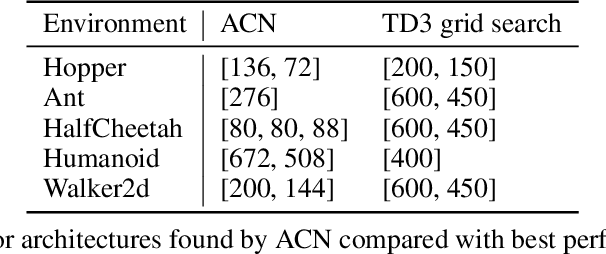
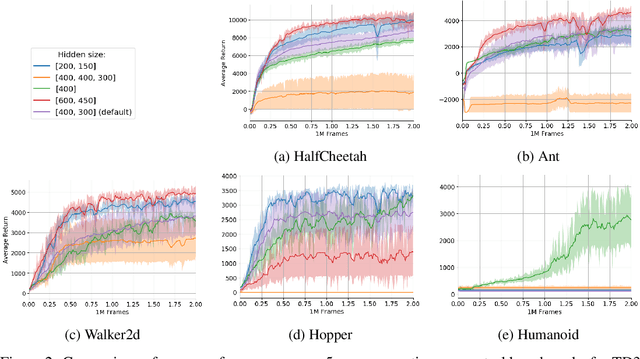

Current Deep Reinforcement Learning algorithms still heavily rely on handcrafted neural network architectures. We propose a novel approach to automatically find strong topologies for continuous control tasks while only adding a minor overhead in terms of interactions in the environment. To achieve this, we combine Neuroevolution techniques with off-policy training and propose a novel architecture mutation operator. Experiments on five continuous control benchmarks show that the proposed Actor-Critic Neuroevolution algorithm often outperforms the strong Actor-Critic baseline and is capable of automatically finding topologies in a sample-efficient manner which would otherwise have to be found by expensive architecture search.