 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiCo3D: Multi-Label Voxel Contrast for One-Shot Incremental Segmentation of 3D Neuroimages
Mar 09, 20253D neuroimages provide a comprehensive view of brain structure and function, aiding in precise localization and functional connectivity analysis. Segmentation of white matter (WM) tracts using 3D neuroimages is vital for understanding the brain's structural connectivity in both healthy and diseased states. One-shot Class Incremental Semantic Segmentation (OCIS) refers to effectively segmenting new (novel) classes using only a single sample while retaining knowledge of old (base) classes without forgetting. Voxel-contrastive OCIS methods adjust the feature space to alleviate the feature overlap problem between the base and novel classes. However, since WM tract segmentation is a multi-label segmentation task, existing single-label voxel contrastive-based methods may cause inherent contradictions. To address this, we propose a new multi-label voxel contrast framework called MultiCo3D for one-shot class incremental tract segmentation. Our method utilizes uncertainty distillation to preserve base tract segmentation knowledge while adjusting the feature space with multi-label voxel contrast to alleviate feature overlap when learning novel tracts and dynamically weighting multi losses to balance overall loss. We compare our method against several state-of-the-art (SOTA) approaches. The experimental results show that our method significantly enhances one-shot class incremental tract segmentation accuracy across five different experimental setups on HCP and Preto datasets.
TractCloud-FOV: Deep Learning-based Robust Tractography Parcellation in Diffusion MRI with Incomplete Field of View
Feb 28, 2025Tractography parcellation classifies streamlines reconstructed from diffusion MRI into anatomically defined fiber tracts for clinical and research applications. However, clinical scans often have incomplete fields of view (FOV) where brain regions are partially imaged, leading to partial or truncated fiber tracts. To address this challenge, we introduce TractCloud-FOV, a deep learning framework that robustly parcellates tractography under conditions of incomplete FOV. We propose a novel training strategy, FOV-Cut Augmentation (FOV-CA), in which we synthetically cut tractograms to simulate a spectrum of real-world inferior FOV cutoff scenarios. This data augmentation approach enriches the training set with realistic truncated streamlines, enabling the model to achieve superior generalization. We evaluate the proposed TractCloud-FOV on both synthetically cut tractography and two real-life datasets with incomplete FOV. TractCloud-FOV significantly outperforms several state-of-the-art methods on all testing datasets in terms of streamline classification accuracy, generalization ability, tract anatomical depiction, and computational efficiency. Overall, TractCloud-FOV achieves efficient and consistent tractography parcellation in diffusion MRI with incomplete FOV.
Medical Image Registration Meets Vision Foundation Model: Prototype Learning and Contour Awareness
Feb 17, 2025Medical image registration is a fundamental task in medical image analysis, aiming to establish spatial correspondences between paired images. However, existing unsupervised deformable registration methods rely solely on intensity-based similarity metrics, lacking explicit anatomical knowledge, which limits their accuracy and robustness. Vision foundation models, such as the Segment Anything Model (SAM), can generate high-quality segmentation masks that provide explicit anatomical structure knowledge, addressing the limitations of traditional methods that depend only on intensity similarity. Based on this, we propose a novel SAM-assisted registration framework incorporating prototype learning and contour awareness. The framework includes: (1) Explicit anatomical information injection, where SAM-generated segmentation masks are used as auxiliary inputs throughout training and testing to ensure the consistency of anatomical information; (2) Prototype learning, which leverages segmentation masks to extract prototype features and aligns prototypes to optimize semantic correspondences between images; and (3) Contour-aware loss, a contour-aware loss is designed that leverages the edges of segmentation masks to improve the model's performance in fine-grained deformation fields. Extensive experiments demonstrate that the proposed framework significantly outperforms existing methods across multiple datasets, particularly in challenging scenarios with complex anatomical structures and ambiguous boundaries. Our code is available at https://github.com/HaoXu0507/IPMI25-SAM-Assisted-Registration.
Enhancing Advanced Visual Reasoning Ability of Large Language Models
Sep 21, 2024



Recent advancements in Vision-Language (VL) research have sparked new benchmarks for complex visual reasoning, challenging models' advanced reasoning ability. Traditional Vision-Language Models (VLMs) perform well in visual perception tasks while struggling with complex reasoning scenarios. Conversely, Large Language Models (LLMs) demonstrate robust text reasoning capabilities; however, they lack visual acuity. To bridge this gap, we propose Complex Visual Reasoning Large Language Models (CVR-LLM), capitalizing on VLMs' visual perception proficiency and LLMs' extensive reasoning capability. Unlike recent multimodal large language models (MLLMs) that require a projection layer, our approach transforms images into detailed, context-aware descriptions using an iterative self-refinement loop and leverages LLMs' text knowledge for accurate predictions without extra training. We also introduce a novel multi-modal in-context learning (ICL) methodology to enhance LLMs' contextual understanding and reasoning. Additionally, we introduce Chain-of-Comparison (CoC), a step-by-step comparison technique enabling contrasting various aspects of predictions. Our CVR-LLM presents the first comprehensive study across a wide array of complex visual reasoning tasks and achieves SOTA performance among all.
Multi-Programming Language Ensemble for Code Generation in Large Language Model
Sep 06, 2024Large language models (LLMs) have significantly improved code generation, particularly in one-pass code generation. However, most existing approaches focus solely on generating code in a single programming language, overlooking the potential of leveraging the multi-language capabilities of LLMs. LLMs have varying patterns of errors across different languages, suggesting that a more robust approach could be developed by leveraging these multi-language outputs. In this study, we propose Multi-Programming Language Ensemble (MPLE), a novel ensemble-based method that utilizes code generation across multiple programming languages to enhance overall performance. By treating each language-specific code generation process as an individual "weak expert" and effectively integrating their outputs, our method mitigates language-specific errors and biases. This multi-language ensemble strategy leverages the complementary strengths of different programming languages, enabling the model to produce more accurate and robust code. Our approach can be seamlessly integrated with commonly used techniques such as the reflection algorithm and Monte Carlo tree search to improve code generation quality further. Experimental results show that our framework consistently enhances baseline performance by up to 17.92% on existing benchmarks (HumanEval and HumanEval-plus), with a standout result of 96.25% accuracy on the HumanEval benchmark, achieving new state-of-the-art results across various LLM models. The code will be released at https://github.com/NinjaTech-AI/MPLE
Enhancing Robustness to Noise Corruption for Point Cloud Model via Spatial Sorting and Set-Mixing Aggregation Module
Jul 15, 2024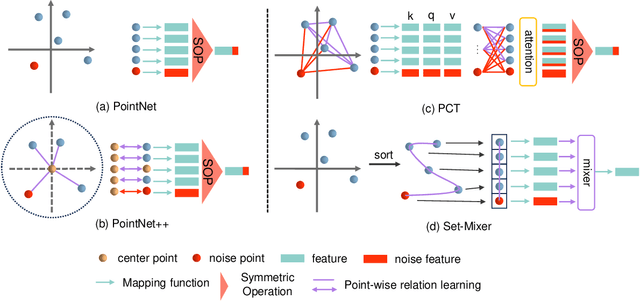
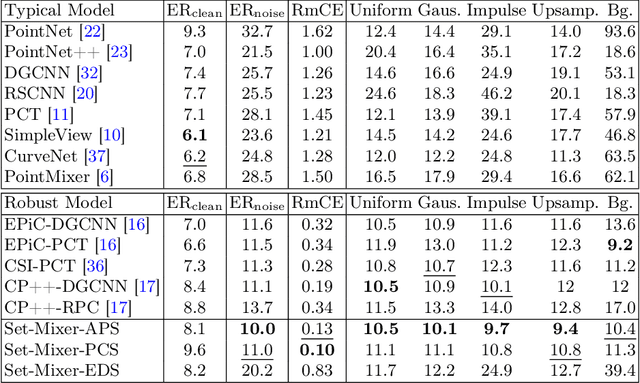
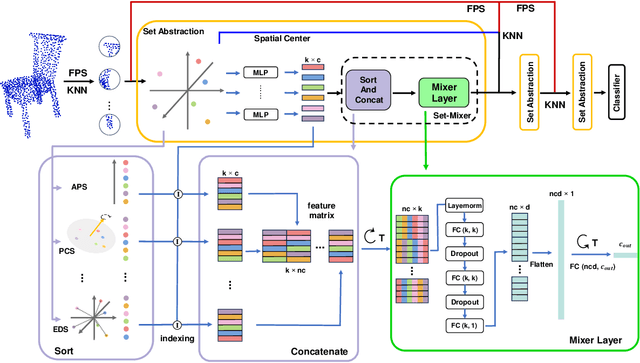
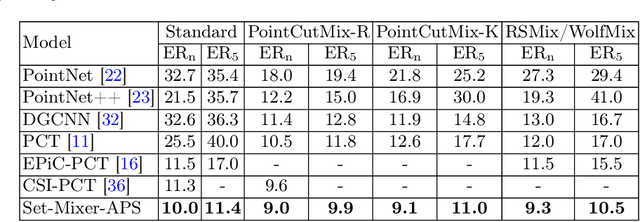
Current models for point cloud recognition demonstrate promising performance on synthetic datasets. However, real-world point cloud data inevitably contains noise, impacting model robustness. While recent efforts focus on enhancing robustness through various strategies, there still remains a gap in comprehensive analyzes from the standpoint of network architecture design. Unlike traditional methods that rely on generic techniques, our approach optimizes model robustness to noise corruption through network architecture design. Inspired by the token-mixing technique applied in 2D images, we propose Set-Mixer, a noise-robust aggregation module which facilitates communication among all points to extract geometric shape information and mitigating the influence of individual noise points. A sorting strategy is designed to enable our module to be invariant to point permutation, which also tackles the unordered structure of point cloud and introduces consistent relative spatial information. Experiments conducted on ModelNet40-C indicate that Set-Mixer significantly enhances the model performance on noisy point clouds, underscoring its potential to advance real-world applicability in 3D recognition and perception tasks.
NinjaLLM: Fast, Scalable and Cost-effective RAG using Amazon SageMaker and AWS Trainium and Inferentia2
Jul 11, 2024
Retrieval-augmented generation (RAG) techniques are widely used today to retrieve and present information in a conversational format. This paper presents a set of enhancements to traditional RAG techniques, focusing on large language models (LLMs) fine-tuned and hosted on AWS Trainium and Inferentia2 AI chips via SageMaker. These chips are characterized by their elasticity, affordability, and efficient performance for AI compute tasks. Besides enabling deployment on these chips, this work aims to improve tool usage, add citation capabilities, and mitigate the risks of hallucinations and unsafe responses due to context bias. We benchmark our RAG system's performance on the Natural Questions and HotPotQA datasets, achieving an accuracy of 62% and 59% respectively, exceeding other models such as DBRX and Mixtral Instruct.
TractGraphFormer: Anatomically Informed Hybrid Graph CNN-Transformer Network for Classification from Diffusion MRI Tractography
Jul 11, 2024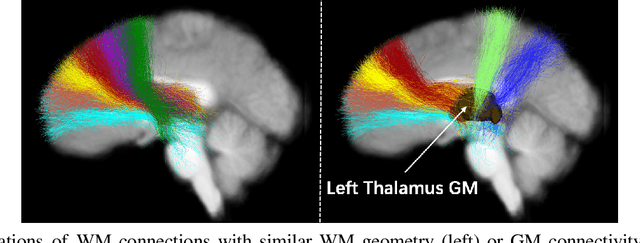

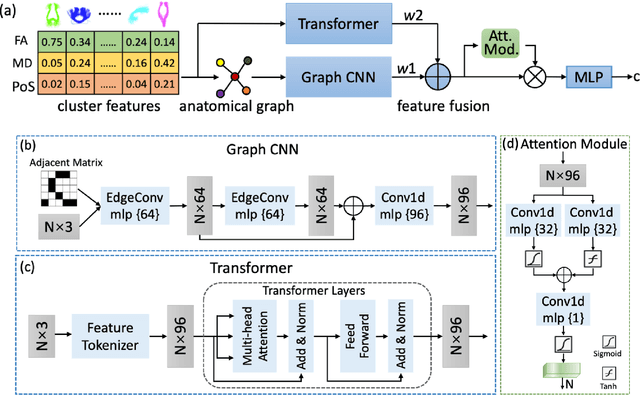

The relationship between brain connections and non-imaging phenotypes is increasingly studied using deep neural networks. However, the local and global properties of the brain's white matter networks are often overlooked in convolutional network design. We introduce TractGraphFormer, a hybrid Graph CNN-Transformer deep learning framework tailored for diffusion MRI tractography. This model leverages local anatomical characteristics and global feature dependencies of white matter structures. The Graph CNN module captures white matter geometry and grey matter connectivity to aggregate local features from anatomically similar white matter connections, while the Transformer module uses self-attention to enhance global information learning. Additionally, TractGraphFormer includes an attention module for interpreting predictive white matter connections. In sex prediction tests, TractGraphFormer shows strong performance in large datasets of children (n=9345) and young adults (n=1065). Overall, our approach suggests that widespread connections in the WM are predictive of the sex of an individual, and consistent predictive anatomical tracts are identified across the two datasets. The proposed approach highlights the potential of integrating local anatomical information and global feature dependencies to improve prediction performance in machine learning with diffusion MRI tractography.
A Deep Network for Explainable Prediction of Non-Imaging Phenotypes using Anatomical Multi-View Data
Jan 13, 2024Large datasets often contain multiple distinct feature sets, or views, that offer complementary information that can be exploited by multi-view learning methods to improve results. We investigate anatomical multi-view data, where each brain anatomical structure is described with multiple feature sets. In particular, we focus on sets of white matter microstructure and connectivity features from diffusion MRI, as well as sets of gray matter area and thickness features from structural MRI. We investigate machine learning methodology that applies multi-view approaches to improve the prediction of non-imaging phenotypes, including demographics (age), motor (strength), and cognition (picture vocabulary). We present an explainable multi-view network (EMV-Net) that can use different anatomical views to improve prediction performance. In this network, each individual anatomical view is processed by a view-specific feature extractor and the extracted information from each view is fused using a learnable weight. This is followed by a wavelet transform-based module to obtain complementary information across views which is then applied to calibrate the view-specific information. Additionally, the calibrator produces an attention-based calibration score to indicate anatomical structures' importance for interpretation.
TractCloud: Registration-free tractography parcellation with a novel local-global streamline point cloud representation
Jul 18, 2023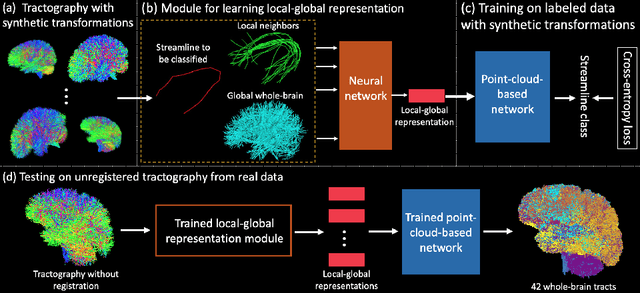
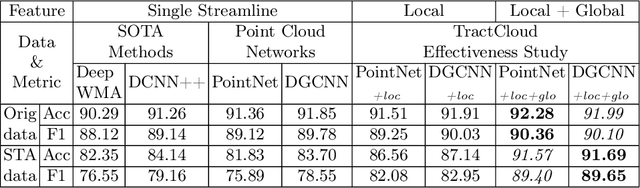
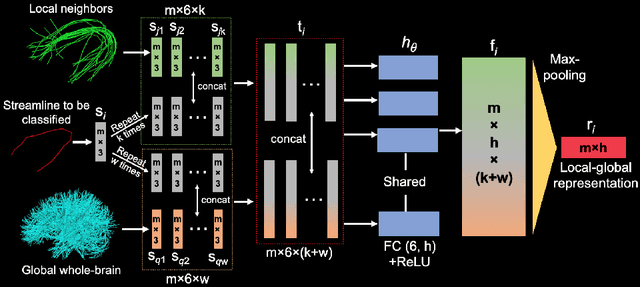
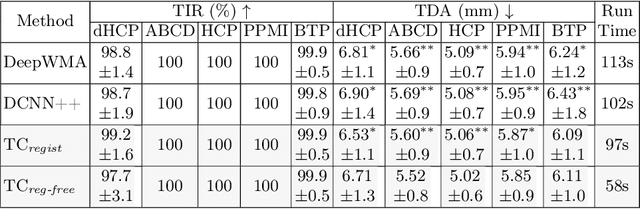
Diffusion MRI tractography parcellation classifies streamlines into anatomical fiber tracts to enable quantification and visualization for clinical and scientific applications. Current tractography parcellation methods rely heavily on registration, but registration inaccuracies can affect parcellation and the computational cost of registration is high for large-scale datasets. Recently, deep-learning-based methods have been proposed for tractography parcellation using various types of representations for streamlines. However, these methods only focus on the information from a single streamline, ignoring geometric relationships between the streamlines in the brain. We propose TractCloud, a registration-free framework that performs whole-brain tractography parcellation directly in individual subject space. We propose a novel, learnable, local-global streamline representation that leverages information from neighboring and whole-brain streamlines to describe the local anatomy and global pose of the brain. We train our framework on a large-scale labeled tractography dataset, which we augment by applying synthetic transforms including rotation, scaling, and translations. We test our framework on five independently acquired datasets across populations and health conditions. TractCloud significantly outperforms several state-of-the-art methods on all testing datasets. TractCloud achieves efficient and consistent whole-brain white matter parcellation across the lifespan (from neonates to elderly subjects, including brain tumor patients) without the need for registration. The robustness and high inference speed of TractCloud make it suitable for large-scale tractography data analysis. Our project page is available at https://tractcloud.github.io/.