 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Disentanglement of Arteriovenous Malformations in Digital Subtraction Angiography
Feb 15, 2024Although Digital Subtraction Angiography (DSA) is the most important imaging for visualizing cerebrovascular anatomy, its interpretation by clinicians remains difficult. This is particularly true when treating arteriovenous malformations (AVMs), where entangled vasculature connecting arteries and veins needs to be carefully identified.The presented method aims to enhance DSA image series by highlighting critical information via automatic classification of vessels using a combination of two learning models: An unsupervised machine learning method based on Independent Component Analysis that decomposes the phases of flow and a convolutional neural network that automatically delineates the vessels in image space. The proposed method was tested on clinical DSA images series and demonstrated efficient differentiation between arteries and veins that provides a viable solution to enhance visualizations for clinical use.
Learning Expected Appearances for Intraoperative Registration during Neurosurgery
Oct 03, 2023We present a novel method for intraoperative patient-to-image registration by learning Expected Appearances. Our method uses preoperative imaging to synthesize patient-specific expected views through a surgical microscope for a predicted range of transformations. Our method estimates the camera pose by minimizing the dissimilarity between the intraoperative 2D view through the optical microscope and the synthesized expected texture. In contrast to conventional methods, our approach transfers the processing tasks to the preoperative stage, reducing thereby the impact of low-resolution, distorted, and noisy intraoperative images, that often degrade the registration accuracy. We applied our method in the context of neuronavigation during brain surgery. We evaluated our approach on synthetic data and on retrospective data from 6 clinical cases. Our method outperformed state-of-the-art methods and achieved accuracies that met current clinical standards.
Unified Brain MR-Ultrasound Synthesis using Multi-Modal Hierarchical Representations
Sep 19, 2023We introduce MHVAE, a deep hierarchical variational auto-encoder (VAE) that synthesizes missing images from various modalities. Extending multi-modal VAEs with a hierarchical latent structure, we introduce a probabilistic formulation for fusing multi-modal images in a common latent representation while having the flexibility to handle incomplete image sets as input. Moreover, adversarial learning is employed to generate sharper images. Extensive experiments are performed on the challenging problem of joint intra-operative ultrasound (iUS) and Magnetic Resonance (MR) synthesis. Our model outperformed multi-modal VAEs, conditional GANs, and the current state-of-the-art unified method (ResViT) for synthesizing missing images, demonstrating the advantage of using a hierarchical latent representation and a principled probabilistic fusion operation. Our code is publicly available \url{https://github.com/ReubenDo/MHVAE}.
Do Public Datasets Assure Unbiased Comparisons for Registration Evaluation?
Mar 20, 2020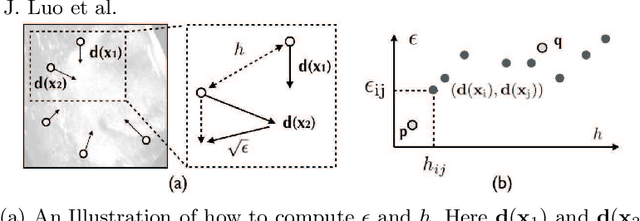

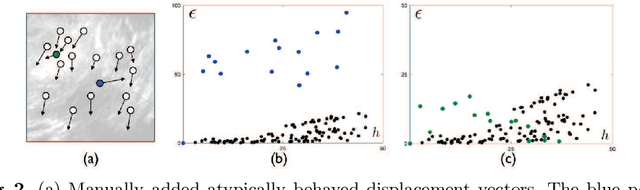
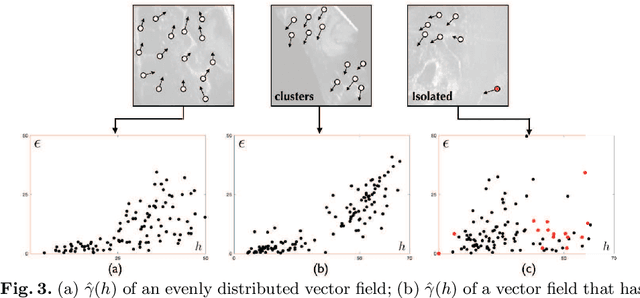
With the increasing availability of new image registration approaches, an unbiased evaluation is becoming more needed so that clinicians can choose the most suitable approaches for their applications. Current evaluations typically use landmarks in manually annotated datasets. As a result, the quality of annotations is crucial for unbiased comparisons. Even though most data providers claim to have quality control over their datasets, an objective third-party screening can be reassuring for intended users. In this study, we use the variogram to screen the manually annotated landmarks in two datasets used to benchmark registration in image-guided neurosurgeries. The variogram provides an intuitive 2D representation of the spatial characteristics of annotated landmarks. Using variograms, we identified potentially problematic cases and had them examined by experienced radiologists. We found that (1) a small number of annotations may have fiducial localization errors; (2) the landmark distribution for some cases is not ideal to offer fair comparisons. If unresolved, both findings could incur bias in registration evaluation.