 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJParc: Joint cortical surface parcellation with registration
Dec 27, 2025Cortical surface parcellation is a fundamental task in both basic neuroscience research and clinical applications, enabling more accurate mapping of brain regions. Model-based and learning-based approaches for automated parcellation alleviate the need for manual labeling. Despite the advancement in parcellation performance, learning-based methods shift away from registration and atlas propagation without exploring the reason for the improvement compared to traditional methods. In this study, we present JParc, a joint cortical registration and parcellation framework, that outperforms existing state-of-the-art parcellation methods. In rigorous experiments, we demonstrate that the enhanced performance of JParc is primarily attributable to accurate cortical registration and a learned parcellation atlas. By leveraging a shallow subnetwork to fine-tune the propagated atlas labels, JParc achieves a Dice score greater than 90% on the Mindboggle dataset, using only basic geometric features (sulcal depth, curvature) that describe cortical folding patterns. The superior accuracy of JParc can significantly increase the statistical power in brain mapping studies as well as support applications in surgical planning and many other downstream neuroscientific and clinical tasks.
Unified Brain Surface and Volume Registration
Dec 22, 2025Accurate registration of brain MRI scans is fundamental for cross-subject analysis in neuroscientific studies. This involves aligning both the cortical surface of the brain and the interior volume. Traditional methods treat volumetric and surface-based registration separately, which often leads to inconsistencies that limit downstream analyses. We propose a deep learning framework, NeurAlign, that registers $3$D brain MRI images by jointly aligning both cortical and subcortical regions through a unified volume-and-surface-based representation. Our approach leverages an intermediate spherical coordinate space to bridge anatomical surface topology with volumetric anatomy, enabling consistent and anatomically accurate alignment. By integrating spherical registration into the learning, our method ensures geometric coherence between volume and surface domains. In a series of experiments on both in-domain and out-of-domain datasets, our method consistently outperforms both classical and machine learning-based registration methods -- improving the Dice score by up to 7 points while maintaining regular deformation fields. Additionally, it is orders of magnitude faster than the standard method for this task, and is simpler to use because it requires no additional inputs beyond an MRI scan. With its superior accuracy, fast inference, and ease of use, NeurAlign sets a new standard for joint cortical and subcortical registration.
MultiMorph: On-demand Atlas Construction
Mar 31, 2025We present MultiMorph, a fast and efficient method for constructing anatomical atlases on the fly. Atlases capture the canonical structure of a collection of images and are essential for quantifying anatomical variability across populations. However, current atlas construction methods often require days to weeks of computation, thereby discouraging rapid experimentation. As a result, many scientific studies rely on suboptimal, precomputed atlases from mismatched populations, negatively impacting downstream analyses. MultiMorph addresses these challenges with a feedforward model that rapidly produces high-quality, population-specific atlases in a single forward pass for any 3D brain dataset, without any fine-tuning or optimization. MultiMorph is based on a linear group-interaction layer that aggregates and shares features within the group of input images. Further, by leveraging auxiliary synthetic data, MultiMorph generalizes to new imaging modalities and population groups at test-time. Experimentally, MultiMorph outperforms state-of-the-art optimization-based and learning-based atlas construction methods in both small and large population settings, with a 100-fold reduction in time. This makes MultiMorph an accessible framework for biomedical researchers without machine learning expertise, enabling rapid, high-quality atlas generation for diverse studies.
Learn2Synth: Learning Optimal Data Synthesis Using Hypergradients
Nov 23, 2024



Domain randomization through synthesis is a powerful strategy to train networks that are unbiased with respect to the domain of the input images. Randomization allows networks to see a virtually infinite range of intensities and artifacts during training, thereby minimizing overfitting to appearance and maximizing generalization to unseen data. While powerful, this approach relies on the accurate tuning of a large set of hyper-parameters governing the probabilistic distribution of the synthesized images. Instead of manually tuning these parameters, we introduce Learn2Synth, a novel procedure in which synthesis parameters are learned using a small set of real labeled data. Unlike methods that impose constraints to align synthetic data with real data (e.g., contrastive or adversarial techniques), which risk misaligning the image and its label map, we tune an augmentation engine such that a segmentation network trained on synthetic data has optimal accuracy when applied to real data. This approach allows the training procedure to benefit from real labeled examples, without ever using these real examples to train the segmentation network, which avoids biasing the network towards the properties of the training set. Specifically, we develop both parametric and nonparametric strategies to augment the synthetic images, enhancing the segmentation network's performance. Experimental results on both synthetic and real-world datasets demonstrate the effectiveness of this learning strategy. Code is available at: https://github.com/HuXiaoling/Learn2Synth.
Neurovascular Segmentation in sOCT with Deep Learning and Synthetic Training Data
Jul 01, 2024



Microvascular anatomy is known to be involved in various neurological disorders. However, understanding these disorders is hindered by the lack of imaging modalities capable of capturing the comprehensive three-dimensional vascular network structure at microscopic resolution. With a lateral resolution of $<=$20 {\textmu}m and ability to reconstruct large tissue blocks up to tens of cubic centimeters, serial-section optical coherence tomography (sOCT) is well suited for this task. This method uses intrinsic optical properties to visualize the vessels and therefore does not possess a specific contrast, which complicates the extraction of accurate vascular models. The performance of traditional vessel segmentation methods is heavily degraded in the presence of substantial noise and imaging artifacts and is sensitive to domain shifts, while convolutional neural networks (CNNs) require extensive labeled data and are also sensitive the precise intensity characteristics of the data that they are trained on. Building on the emerging field of synthesis-based training, this study demonstrates a synthesis engine for neurovascular segmentation in sOCT images. Characterized by minimal priors and high variance sampling, our highly generalizable method tested on five distinct sOCT acquisitions eliminates the need for manual annotations while attaining human-level precision. Our approach comprises two phases: label synthesis and label-to-image transformation. We demonstrate the efficacy of the former by comparing it to several more realistic sets of training labels, and the latter by an ablation study of synthetic noise and artifact models.
A label-free and data-free training strategy for vasculature segmentation in serial sectioning OCT data
May 22, 2024

Serial sectioning Optical Coherence Tomography (sOCT) is a high-throughput, label free microscopic imaging technique that is becoming increasingly popular to study post-mortem neurovasculature. Quantitative analysis of the vasculature requires highly accurate segmentation; however, sOCT has low signal-to-noise-ratio and displays a wide range of contrasts and artifacts that depend on acquisition parameters. Furthermore, labeled data is scarce and extremely time consuming to generate. Here, we leverage synthetic datasets of vessels to train a deep learning segmentation model. We construct the vessels with semi-realistic splines that simulate the vascular geometry and compare our model with realistic vascular labels generated by constrained constructive optimization. Both approaches yield similar Dice scores, although with very different false positive and false negative rates. This method addresses the complexity inherent in OCT images and paves the way for more accurate and efficient analysis of neurovascular structures.
Boosting Skull-Stripping Performance for Pediatric Brain Images
Feb 26, 2024



Skull-stripping is the removal of background and non-brain anatomical features from brain images. While many skull-stripping tools exist, few target pediatric populations. With the emergence of multi-institutional pediatric data acquisition efforts to broaden the understanding of perinatal brain development, it is essential to develop robust and well-tested tools ready for the relevant data processing. However, the broad range of neuroanatomical variation in the developing brain, combined with additional challenges such as high motion levels, as well as shoulder and chest signal in the images, leaves many adult-specific tools ill-suited for pediatric skull-stripping. Building on an existing framework for robust and accurate skull-stripping, we propose developmental SynthStrip (d-SynthStrip), a skull-stripping model tailored to pediatric images. This framework exposes networks to highly variable images synthesized from label maps. Our model substantially outperforms pediatric baselines across scan types and age cohorts. In addition, the <1-minute runtime of our tool compares favorably to the fastest baselines. We distribute our model at https://w3id.org/synthstrip.
Fully Convolutional Slice-to-Volume Reconstruction for Single-Stack MRI
Dec 05, 2023



In magnetic resonance imaging (MRI), slice-to-volume reconstruction (SVR) refers to computational reconstruction of an unknown 3D magnetic resonance volume from stacks of 2D slices corrupted by motion. While promising, current SVR methods require multiple slice stacks for accurate 3D reconstruction, leading to long scans and limiting their use in time-sensitive applications such as fetal fMRI. Here, we propose a SVR method that overcomes the shortcomings of previous work and produces state-of-the-art reconstructions in the presence of extreme inter-slice motion. Inspired by the recent success of single-view depth estimation methods, we formulate SVR as a single-stack motion estimation task and train a fully convolutional network to predict a motion stack for a given slice stack, producing a 3D reconstruction as a byproduct of the predicted motion. Extensive experiments on the SVR of adult and fetal brains demonstrate that our fully convolutional method is twice as accurate as previous SVR methods. Our code is available at github.com/seannz/svr.
Multi-Head Graph Convolutional Network for Structural Connectome Classification
May 02, 2023



We tackle classification based on brain connectivity derived from diffusion magnetic resonance images. We propose a machine-learning model inspired by graph convolutional networks (GCNs), which takes a brain connectivity input graph and processes the data separately through a parallel GCN mechanism with multiple heads. The proposed network is a simple design that employs different heads involving graph convolutions focused on edges and nodes, capturing representations from the input data thoroughly. To test the ability of our model to extract complementary and representative features from brain connectivity data, we chose the task of sex classification. This quantifies the degree to which the connectome varies depending on the sex, which is important for improving our understanding of health and disease in both sexes. We show experiments on two publicly available datasets: PREVENT-AD (347 subjects) and OASIS3 (771 subjects). The proposed model demonstrates the highest performance compared to the existing machine-learning algorithms we tested, including classical methods and (graph and non-graph) deep learning. We provide a detailed analysis of each component of our model.
Joint cortical registration of geometry and function using semi-supervised learning
Mar 06, 2023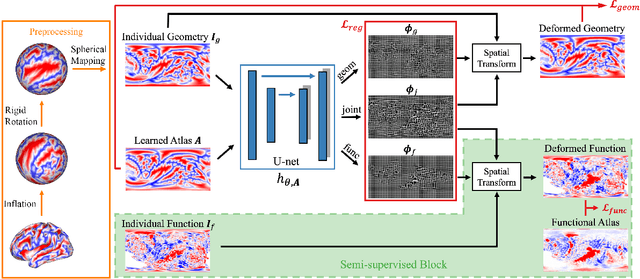


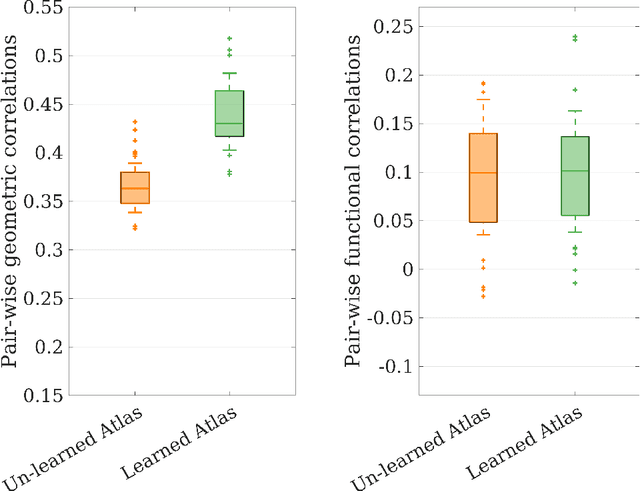
Brain surface-based image registration, an important component of brain image analysis, establishes spatial correspondence between cortical surfaces. Existing iterative and learning-based approaches focus on accurate registration of folding patterns of the cerebral cortex, and assume that geometry predicts function and thus functional areas will also be well aligned. However, structure/functional variability of anatomically corresponding areas across subjects has been widely reported. In this work, we introduce a learning-based cortical registration framework, JOSA, which jointly aligns folding patterns and functional maps while simultaneously learning an optimal atlas. We demonstrate that JOSA can substantially improve registration performance in both anatomical and functional domains over existing methods. By employing a semi-supervised training strategy, the proposed framework obviates the need for functional data during inference, enabling its use in broad neuroscientific domains where functional data may not be observed.