 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Connectomes: A Generational Approach to Data-Efficient Language Models
Apr 29, 2025Biological neural networks are shaped both by evolution across generations and by individual learning within an organism's lifetime, whereas standard artificial neural networks undergo a single, large training procedure without inherited constraints. In this preliminary work, we propose a framework that incorporates this crucial generational dimension - an "outer loop" of evolution that shapes the "inner loop" of learning - so that artificial networks better mirror the effects of evolution and individual learning in biological organisms. Focusing on language, we train a model that inherits a "model connectome" from the outer evolution loop before exposing it to a developmental-scale corpus of 100M tokens. Compared with two closely matched control models, we show that the connectome model performs better or on par on natural language processing tasks as well as alignment to human behavior and brain data. These findings suggest that a model connectome serves as an efficient prior for learning in low-data regimes - narrowing the gap between single-generation artificial models and biologically evolved neural networks.
From Language to Cognition: How LLMs Outgrow the Human Language Network
Mar 03, 2025Large language models (LLMs) exhibit remarkable similarity to neural activity in the human language network. However, the key properties of language shaping brain-like representations, and their evolution during training as a function of different tasks remain unclear. We here benchmark 34 training checkpoints spanning 300B tokens across 8 different model sizes to analyze how brain alignment relates to linguistic competence. Specifically, we find that brain alignment tracks the development of formal linguistic competence -- i.e., knowledge of linguistic rules -- more closely than functional linguistic competence. While functional competence, which involves world knowledge and reasoning, continues to develop throughout training, its relationship with brain alignment is weaker, suggesting that the human language network primarily encodes formal linguistic structure rather than broader cognitive functions. We further show that model size is not a reliable predictor of brain alignment when controlling for feature size and find that the correlation between next-word prediction, behavioral alignment and brain alignment fades once models surpass human language proficiency. Finally, using the largest set of rigorous neural language benchmarks to date, we show that language brain alignment benchmarks remain unsaturated, highlighting opportunities for improving future models. Taken together, our findings suggest that the human language network is best modeled by formal, rather than functional, aspects of language.
The LLM Language Network: A Neuroscientific Approach for Identifying Causally Task-Relevant Units
Nov 04, 2024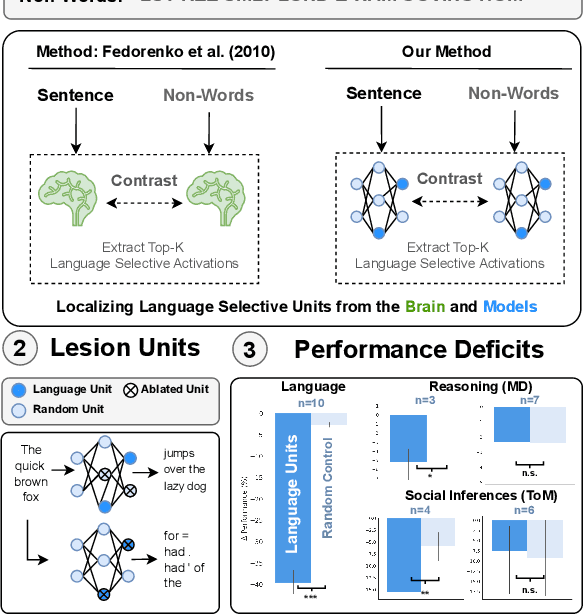

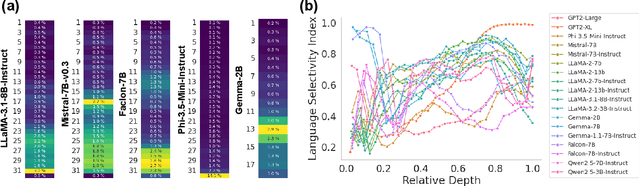

Large language models (LLMs) exhibit remarkable capabilities on not just language tasks, but also various tasks that are not linguistic in nature, such as logical reasoning and social inference. In the human brain, neuroscience has identified a core language system that selectively and causally supports language processing. We here ask whether similar specialization for language emerges in LLMs. We identify language-selective units within 18 popular LLMs, using the same localization approach that is used in neuroscience. We then establish the causal role of these units by demonstrating that ablating LLM language-selective units -- but not random units -- leads to drastic deficits in language tasks. Correspondingly, language-selective LLM units are more aligned to brain recordings from the human language system than random units. Finally, we investigate whether our localization method extends to other cognitive domains: while we find specialized networks in some LLMs for reasoning and social capabilities, there are substantial differences among models. These findings provide functional and causal evidence for specialization in large language models, and highlight parallels with the functional organization in the brain.
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Jun 21, 2024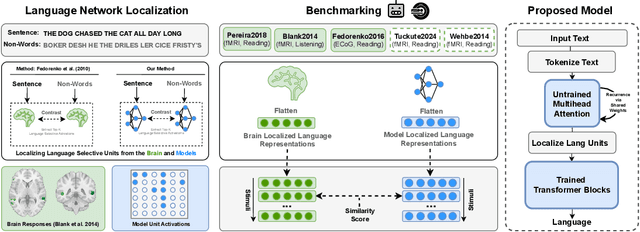

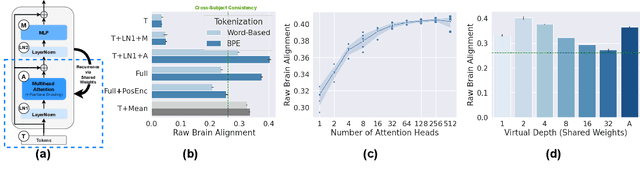
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
WhisBERT: Multimodal Text-Audio Language Modeling on 100M Words
Dec 07, 2023

Training on multiple modalities of input can augment the capabilities of a language model. Here, we ask whether such a training regime can improve the quality and efficiency of these systems as well. We focus on text--audio and introduce Whisbert, which is inspired by the text--image approach of FLAVA (Singh et al., 2022). In accordance with Babylm guidelines (Warstadt et al., 2023), we pretrain Whisbert on a dataset comprising only 100 million words plus their corresponding speech from the word-aligned version of the People's Speech dataset (Galvez et al., 2021). To assess the impact of multimodality, we compare versions of the model that are trained on text only and on both audio and text simultaneously. We find that while Whisbert is able to perform well on multimodal masked modeling and surpasses the Babylm baselines in most benchmark tasks, it struggles to optimize its complex objective and outperform its text-only Whisbert baseline.
Joint cortical registration of geometry and function using semi-supervised learning
Mar 06, 2023Brain surface-based image registration, an important component of brain image analysis, establishes spatial correspondence between cortical surfaces. Existing iterative and learning-based approaches focus on accurate registration of folding patterns of the cerebral cortex, and assume that geometry predicts function and thus functional areas will also be well aligned. However, structure/functional variability of anatomically corresponding areas across subjects has been widely reported. In this work, we introduce a learning-based cortical registration framework, JOSA, which jointly aligns folding patterns and functional maps while simultaneously learning an optimal atlas. We demonstrate that JOSA can substantially improve registration performance in both anatomical and functional domains over existing methods. By employing a semi-supervised training strategy, the proposed framework obviates the need for functional data during inference, enabling its use in broad neuroscientific domains where functional data may not be observed.