 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Learn Constructional Semantics, Not To Mention Syntax: Investigating LM Understanding of Paired-Focus Constructions
May 29, 2026Grasping the semantics of rare constructions (form-meaning pairings) has been shown to be a challenging problem that has currently only been solved by the largest LLMs. It remains an open question if open-source models have robust constructional understanding, and if so, what learning dynamics underlie the acquisition of this knowledge. Focusing on a set of rare Paired-Focus constructions in English (e.g. "let alone", "much less"), we construct a novel dataset to test their meanings using both scalar adjectival semantics and general world knowledge. Testing a wide range of models differing in parameter count, architecture, and pretraining dataset size, we find that several modestly sized models are sensitive to both the forms and the meanings of Paired-Focus constructions, though models trained on human-scale data fail at all meaning evaluations. Turning to training dynamics for a set of open-checkpoint models, we find that Paired-Focus understanding emerges later in training than Paired-Focus syntactic knowledge, and that learning of Paired-Focus semantics is correlated with gains in some domains of world knowledge. Overall, our empirical results support the conclusion that modestly sized open-source models can grasp the rare Paired-Focus constructions, and demonstrate a connection between knowledge of Paired-Focus constructions and other meaning domains.
What Do Prosody and Text Convey? Characterizing How Meaningful Information is Distributed Across Multiple Channels
Dec 18, 2025
Prosody -- the melody of speech -- conveys critical information often not captured by the words or text of a message. In this paper, we propose an information-theoretic approach to quantify how much information is expressed by prosody alone and not by text, and crucially, what that information is about. Our approach applies large speech and language models to estimate the mutual information between a particular dimension of an utterance's meaning (e.g., its emotion) and any of its communication channels (e.g., audio or text). We then use this approach to quantify how much information is conveyed by audio and text about sarcasm, emotion, and questionhood, using speech from television and podcasts. We find that for sarcasm and emotion the audio channel -- and by implication the prosodic channel -- transmits over an order of magnitude more information about these features than the text channel alone, at least when long-term context beyond the current sentence is unavailable. For questionhood, prosody provides comparatively less additional information. We conclude by outlining a program applying our approach to more dimensions of meaning, communication channels, and languages.
The Harmonic Structure of Information Contours
Jun 04, 2025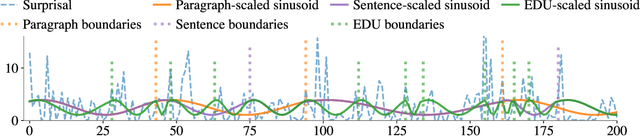
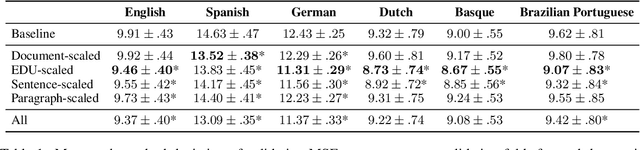
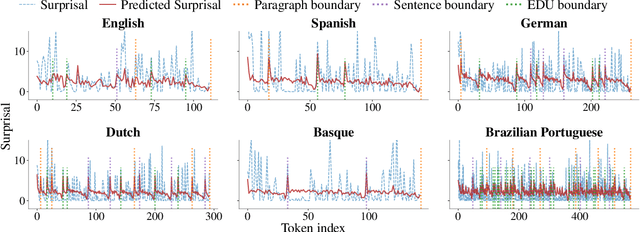
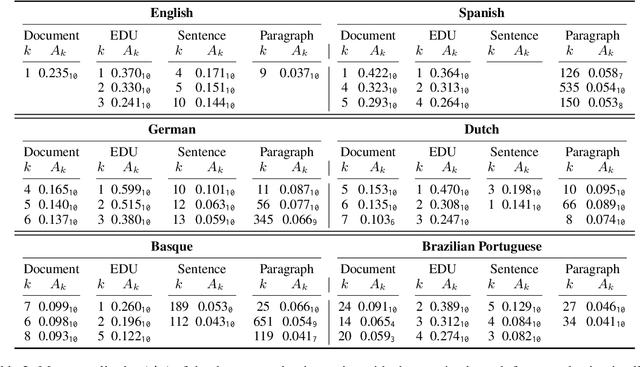
The uniform information density (UID) hypothesis proposes that speakers aim to distribute information evenly throughout a text, balancing production effort and listener comprehension difficulty. However, language typically does not maintain a strictly uniform information rate; instead, it fluctuates around a global average. These fluctuations are often explained by factors such as syntactic constraints, stylistic choices, or audience design. In this work, we explore an alternative perspective: that these fluctuations may be influenced by an implicit linguistic pressure towards periodicity, where the information rate oscillates at regular intervals, potentially across multiple frequencies simultaneously. We apply harmonic regression and introduce a novel extension called time scaling to detect and test for such periodicity in information contours. Analyzing texts in English, Spanish, German, Dutch, Basque, and Brazilian Portuguese, we find consistent evidence of periodic patterns in information rate. Many dominant frequencies align with discourse structure, suggesting these oscillations reflect meaningful linguistic organization. Beyond highlighting the connection between information rate and discourse structure, our approach offers a general framework for uncovering structural pressures at various levels of linguistic granularity.
Unpacking Let Alone: Human-Scale Models Generalize to a Rare Construction in Form but not Meaning
Jun 04, 2025


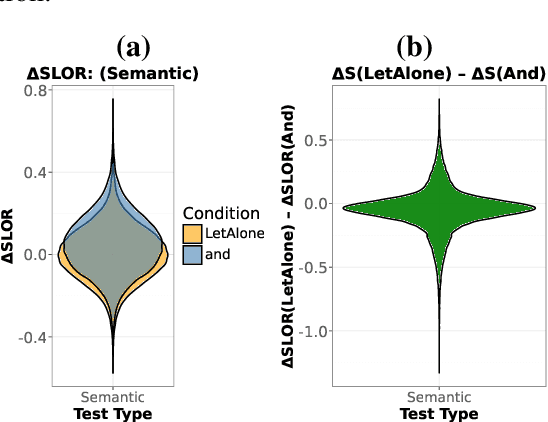
Humans have a remarkable ability to acquire and understand grammatical phenomena that are seen rarely, if ever, during childhood. Recent evidence suggests that language models with human-scale pretraining data may possess a similar ability by generalizing from frequent to rare constructions. However, it remains an open question how widespread this generalization ability is, and to what extent this knowledge extends to meanings of rare constructions, as opposed to just their forms. We fill this gap by testing human-scale transformer language models on their knowledge of both the form and meaning of the (rare and quirky) English LET-ALONE construction. To evaluate our LMs we construct a bespoke synthetic benchmark that targets syntactic and semantic properties of the construction. We find that human-scale LMs are sensitive to form, even when related constructions are filtered from the dataset. However, human-scale LMs do not make correct generalizations about LET-ALONE's meaning. These results point to an asymmetry in the current architectures' sample efficiency between language form and meaning, something which is not present in human language learners.
Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Apr 10, 2025



Children can acquire language from less than 100 million words of input. Large language models are far less data-efficient: they typically require 3 or 4 orders of magnitude more data and still do not perform as well as humans on many evaluations. These intensive resource demands limit the ability of researchers to train new models and use existing models as developmentally plausible cognitive models. The BabyLM Challenge is a communal effort in which participants compete to optimize language model training on a fixed data budget. Submissions are compared on various evaluation tasks targeting grammatical ability, downstream task performance, and generalization. Participants can submit to up to three tracks with progressively looser data restrictions. From over 30 submissions, we extract concrete recommendations on how best to train data-efficient language models, and on where future efforts should (and perhaps should not) focus. The winning submissions using the LTG-BERT architecture (Samuel et al., 2023) outperformed models trained on trillions of words. Other submissions achieved strong results through training on shorter input sequences or training a student model on a pretrained teacher. Curriculum learning attempts, which accounted for a large number of submissions, were largely unsuccessful, though some showed modest improvements.
* Published in Proceedings of BabyLM. Please cite the published version on ACL anthology: http://aclanthology.org/2023.conll-babylm.1/
The time scale of redundancy between prosody and linguistic context
Mar 14, 2025In spoken language, speakers transmit information not only using words, but also via a rich array of non-verbal signals, which include prosody -- the auditory features of speech. However, previous studies have shown that prosodic features exhibit significant redundancy with both past and future words. Here, we examine the time scale of this relationship: How many words in the past (or future) contribute to predicting prosody? We find that this scale differs for past and future words. Prosody's redundancy with past words extends across approximately 3-8 words, whereas redundancy with future words is limited to just 1-2 words. These findings indicate that the prosody-future relationship reflects local word dependencies or short-scale processes such as next word prediction, while the prosody-past relationship unfolds over a longer time scale. The latter suggests that prosody serves to emphasize earlier information that may be challenging for listeners to process given limited cognitive resources in real-time communication. Our results highlight the role of prosody in shaping efficient communication.
Anything Goes? A Crosslinguistic Study of (Im)possible Language Learning in LMs
Feb 26, 2025



Do LLMs offer insights into human language learning? A common argument against this idea is that because their architecture and training paradigm are so vastly different from humans, LLMs can learn arbitrary inputs as easily as natural languages. In this paper, we test this claim by training LMs to model impossible and typologically unattested languages. Unlike previous work, which has focused exclusively on English, we conduct experiments on 12 natural languages from 4 language families. Our results show that while GPT-2 small can primarily distinguish attested languages from their impossible counterparts, it does not achieve perfect separation between all the attested languages and all the impossible ones. We further test whether GPT-2 small distinguishes typologically attested from unattested languages with different NP orders by manipulating word order based on Greenberg's Universal 20. We find that the model's perplexity scores do not distinguish attested vs. unattested word orders, as long as the unattested variants maintain constituency structure. These findings suggest that language models exhibit some human-like inductive biases, though these biases are weaker than those found in human learners.
Language Models Grow Less Humanlike beyond Phase Transition
Feb 26, 2025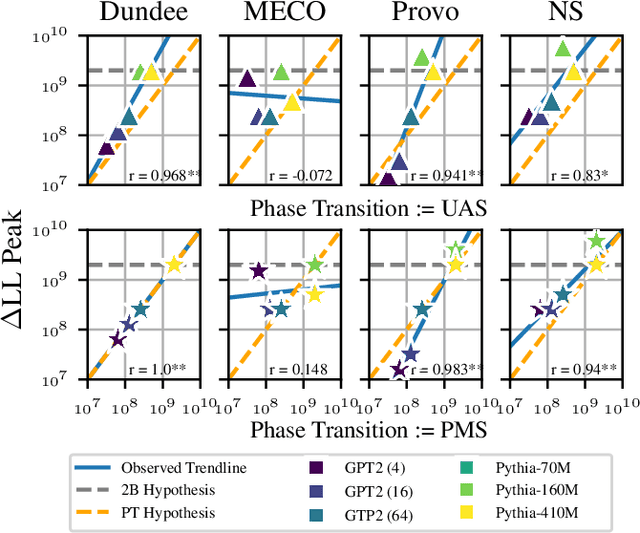
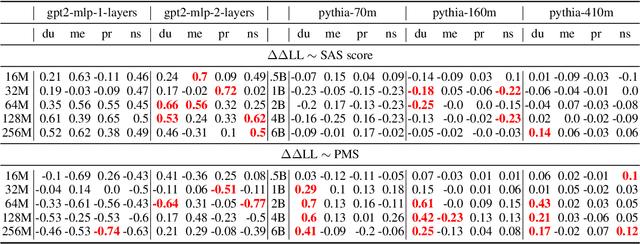
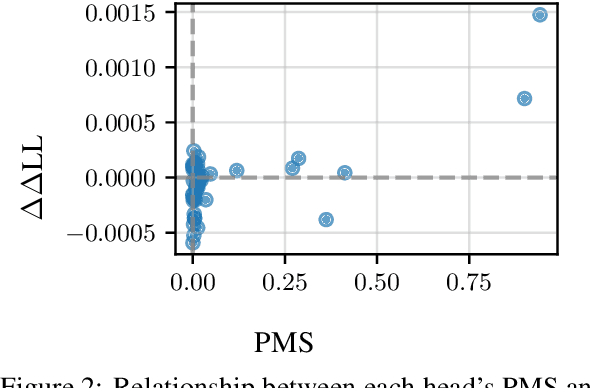
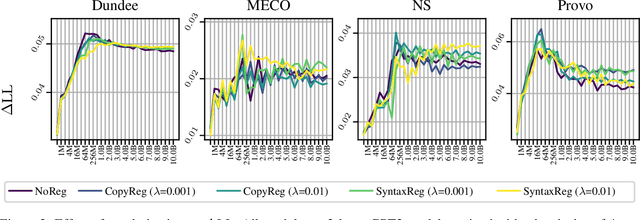
LMs' alignment with human reading behavior (i.e. psychometric predictive power; PPP) is known to improve during pretraining up to a tipping point, beyond which it either plateaus or degrades. Various factors, such as word frequency, recency bias in attention, and context size, have been theorized to affect PPP, yet there is no current account that explains why such a tipping point exists, and how it interacts with LMs' pretraining dynamics more generally. We hypothesize that the underlying factor is a pretraining phase transition, characterized by the rapid emergence of specialized attention heads. We conduct a series of correlational and causal experiments to show that such a phase transition is responsible for the tipping point in PPP. We then show that, rather than producing attention patterns that contribute to the degradation in PPP, phase transitions alter the subsequent learning dynamics of the model, such that further training keeps damaging PPP.
Surprise! Uniform Information Density Isn't the Whole Story: Predicting Surprisal Contours in Long-form Discourse
Oct 21, 2024



The Uniform Information Density (UID) hypothesis posits that speakers tend to distribute information evenly across linguistic units to achieve efficient communication. Of course, information rate in texts and discourses is not perfectly uniform. While these fluctuations can be viewed as theoretically uninteresting noise on top of a uniform target, another explanation is that UID is not the only functional pressure regulating information content in a language. Speakers may also seek to maintain interest, adhere to writing conventions, and build compelling arguments. In this paper, we propose one such functional pressure; namely that speakers modulate information rate based on location within a hierarchically-structured model of discourse. We term this the Structured Context Hypothesis and test it by predicting the surprisal contours of naturally occurring discourses extracted from large language models using predictors derived from discourse structure. We find that hierarchical predictors are significant predictors of a discourse's information contour and that deeply nested hierarchical predictors are more predictive than shallow ones. This work takes an initial step beyond UID to propose testable hypotheses for why the information rate fluctuates in predictable ways
Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024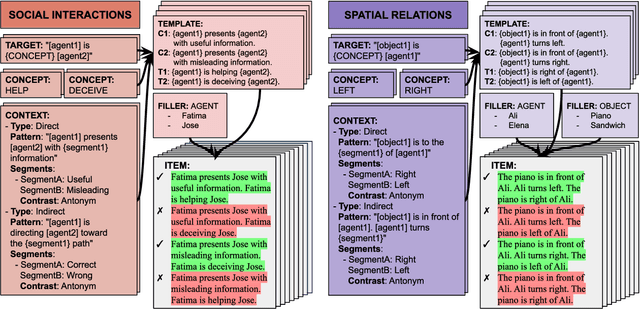
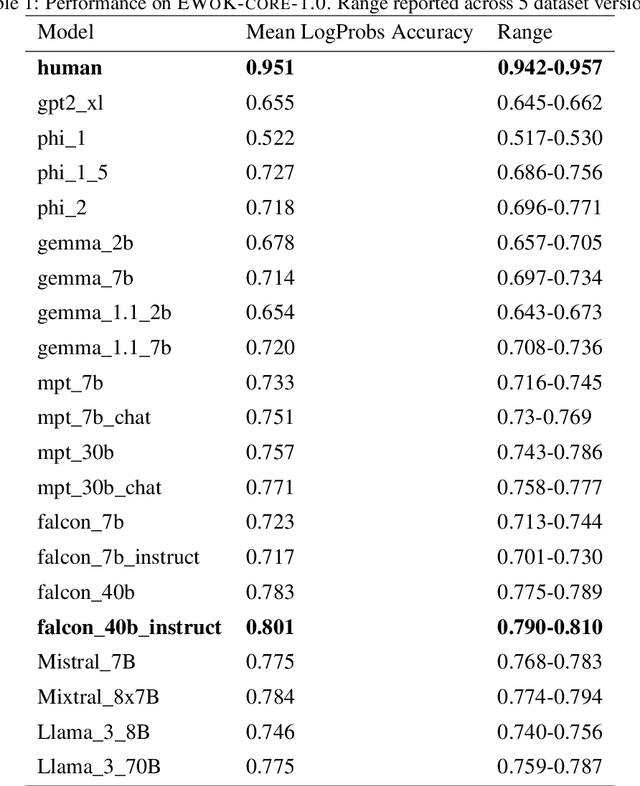
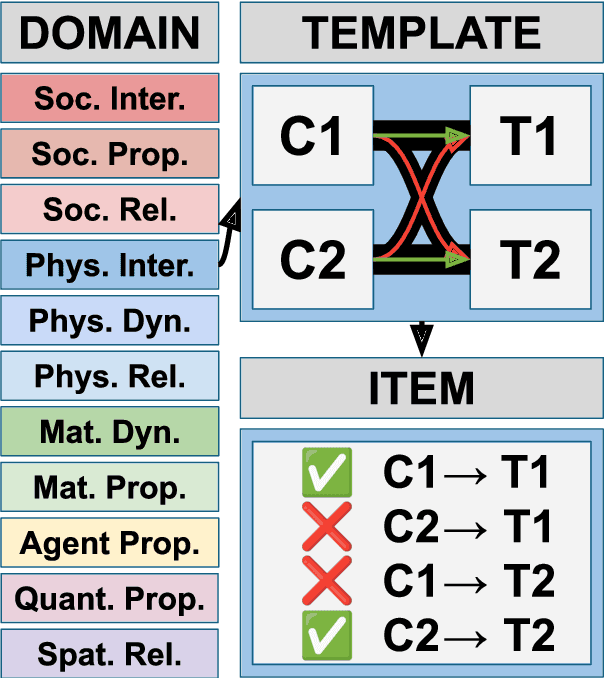
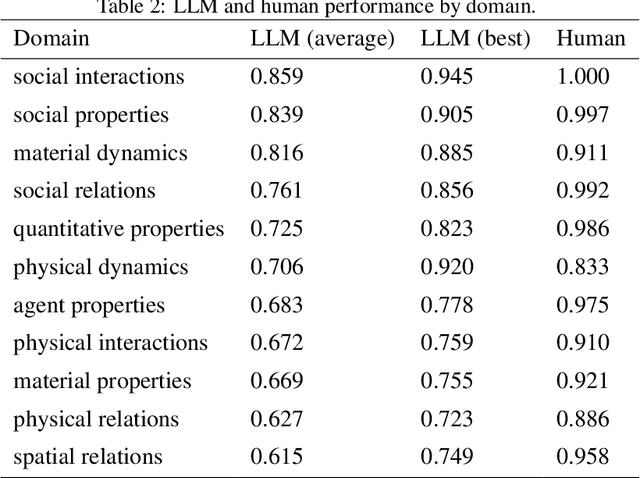
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.