 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers
Apr 09, 2026We study implicit reasoning, i.e. the ability to combine knowledge or rules within a single forward pass. While transformer-based large language models store substantial factual knowledge and rules, they often fail to compose this knowledge for implicit multi-hop reasoning, suggesting a lack of compositional generalization over their parametric knowledge. To address this limitation, we study recurrent-depth transformers, which enables iterative computation over the same transformer layers. We investigate two compositional generalization challenges under the implicit reasoning scenario: systematic generalization, i.e. combining knowledge that is never used for compositions during training, and depth extrapolation, i.e. generalizing from limited reasoning depth (e.g. training on up to 5-hop) to deeper compositions (e.g. 10-hop). Through controlled studies with models trained from scratch, we show that while vanilla transformers struggle with both generalization challenges, recurrent-depth transformers can effectively make such generalization. For systematic generalization, we find that this ability emerges through a three-stage grokking process, transitioning from memorization to in-distribution generalization and finally to systematic generalization, supported by mechanistic analysis. For depth extrapolation, we show that generalization beyond training depth can be unlocked by scaling inference-time recurrence, with more iterations enabling deeper reasoning. We further study how training strategies affect extrapolation, providing guidance on training recurrent-depth transformers, and identify a key limitation, overthinking, where excessive recurrence degrades predictions and limits generalization to very deep compositions.
Language models can learn implicit multi-hop reasoning, but only if they have lots of training data
May 23, 2025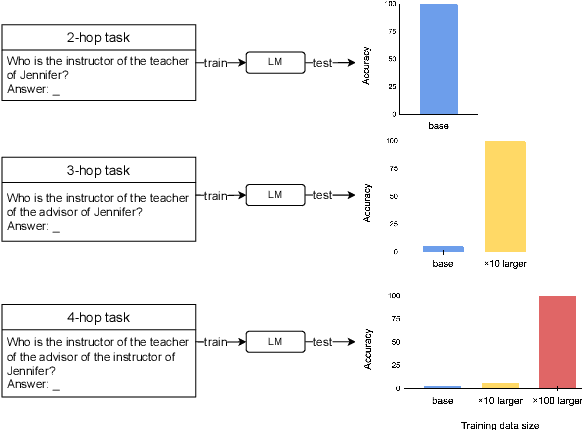
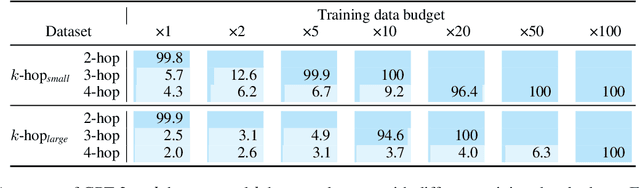
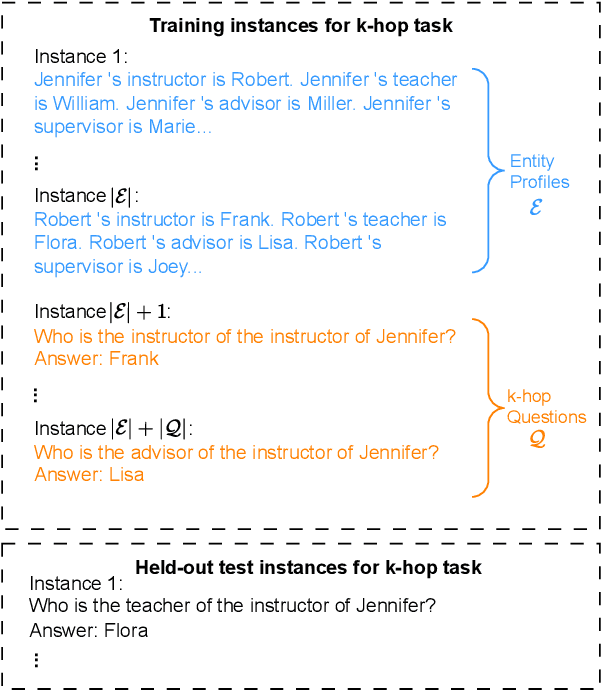
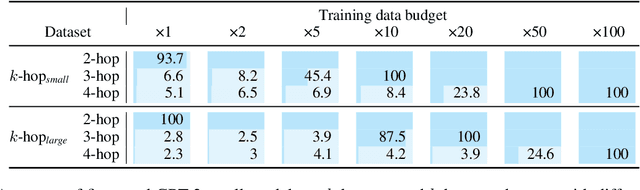
Implicit reasoning is the ability of a language model to solve multi-hop reasoning tasks in a single forward pass, without chain of thought. We investigate this capability using GPT2-style language models trained from scratch on controlled $k$-hop reasoning datasets ($k = 2, 3, 4$). We show that while such models can indeed learn implicit $k$-hop reasoning, the required training data grows exponentially in $k$, and the required number of transformer layers grows linearly in $k$. We offer a theoretical explanation for why this depth growth is necessary. We further find that the data requirement can be mitigated, but not eliminated, through curriculum learning.
Anything Goes? A Crosslinguistic Study of (Im)possible Language Learning in LMs
Feb 26, 2025



Do LLMs offer insights into human language learning? A common argument against this idea is that because their architecture and training paradigm are so vastly different from humans, LLMs can learn arbitrary inputs as easily as natural languages. In this paper, we test this claim by training LMs to model impossible and typologically unattested languages. Unlike previous work, which has focused exclusively on English, we conduct experiments on 12 natural languages from 4 language families. Our results show that while GPT-2 small can primarily distinguish attested languages from their impossible counterparts, it does not achieve perfect separation between all the attested languages and all the impossible ones. We further test whether GPT-2 small distinguishes typologically attested from unattested languages with different NP orders by manipulating word order based on Greenberg's Universal 20. We find that the model's perplexity scores do not distinguish attested vs. unattested word orders, as long as the unattested variants maintain constituency structure. These findings suggest that language models exhibit some human-like inductive biases, though these biases are weaker than those found in human learners.
Simple and effective data augmentation for compositional generalization
Jan 18, 2024Compositional generalization, the ability to predict complex meanings from training on simpler sentences, poses challenges for powerful pretrained seq2seq models. In this paper, we show that data augmentation methods that sample MRs and backtranslate them can be effective for compositional generalization, but only if we sample from the right distribution. Remarkably, sampling from a uniform distribution performs almost as well as sampling from the test distribution, and greatly outperforms earlier methods that sampled from the training distribution. We further conduct experiments to investigate the reason why this happens and where the benefit of such data augmentation methods come from.
Predicting generalization performance with correctness discriminators
Nov 15, 2023The ability to predict an NLP model's accuracy on unseen, potentially out-of-distribution data is a prerequisite for trustworthiness. We present a novel model that establishes upper and lower bounds on the accuracy, without requiring gold labels for the unseen data. We achieve this by training a discriminator which predicts whether the output of a given sequence-to-sequence model is correct or not. We show across a variety of tagging, parsing, and semantic parsing tasks that the gold accuracy is reliably between the predicted upper and lower bounds, and that these bounds are remarkably close together.
SLOG: A Structural Generalization Benchmark for Semantic Parsing
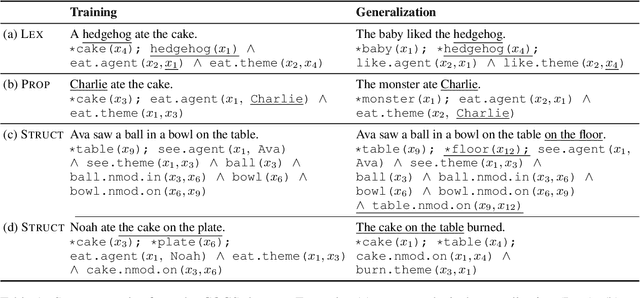
Oct 23, 2023The goal of compositional generalization benchmarks is to evaluate how well models generalize to new complex linguistic expressions. Existing benchmarks often focus on lexical generalization, the interpretation of novel lexical items in syntactic structures familiar from training; structural generalization tasks, where a model needs to interpret syntactic structures that are themselves unfamiliar from training, are often underrepresented, resulting in overly optimistic perceptions of how well models can generalize. We introduce SLOG, a semantic parsing dataset that extends COGS (Kim and Linzen, 2020) with 17 structural generalization cases. In our experiments, the generalization accuracy of Transformer models, including pretrained ones, only reaches 40.6%, while a structure-aware parser only achieves 70.8%. These results are far from the near-perfect accuracy existing models achieve on COGS, demonstrating the role of SLOG in foregrounding the large discrepancy between models' lexical and structural generalization capacities.
Structural generalization is hard for sequence-to-sequence models
Oct 24, 2022Sequence-to-sequence (seq2seq) models have been successful across many NLP tasks, including ones that require predicting linguistic structure. However, recent work on compositional generalization has shown that seq2seq models achieve very low accuracy in generalizing to linguistic structures that were not seen in training. We present new evidence that this is a general limitation of seq2seq models that is present not just in semantic parsing, but also in syntactic parsing and in text-to-text tasks, and that this limitation can often be overcome by neurosymbolic models that have linguistic knowledge built in. We further report on some experiments that give initial answers on the reasons for these limitations.
Compositional Generalization Requires Compositional Parsers
Feb 24, 2022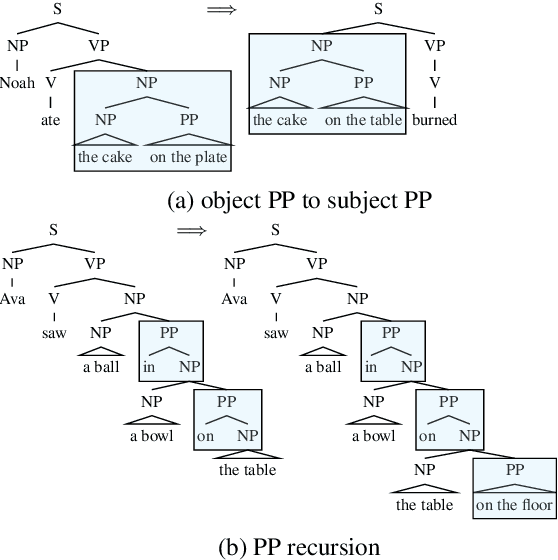
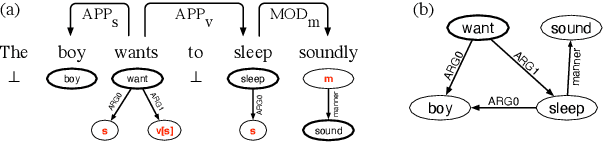
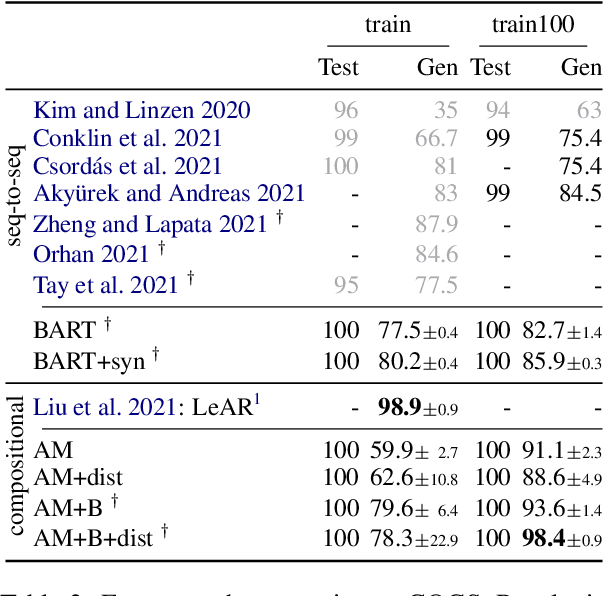
A rapidly growing body of research on compositional generalization investigates the ability of a semantic parser to dynamically recombine linguistic elements seen in training into unseen sequences. We present a systematic comparison of sequence-to-sequence models and models guided by compositional principles on the recent COGS corpus (Kim and Linzen, 2020). Though seq2seq models can perform well on lexical tasks, they perform with near-zero accuracy on structural generalization tasks that require novel syntactic structures; this holds true even when they are trained to predict syntax instead of semantics. In contrast, compositional models achieve near-perfect accuracy on structural generalization; we present new results confirming this from the AM parser (Groschwitz et al., 2021). Our findings show structural generalization is a key measure of compositional generalization and requires models that are aware of complex structure.
ELITR Non-Native Speech Translation at IWSLT 2020
Jun 05, 2020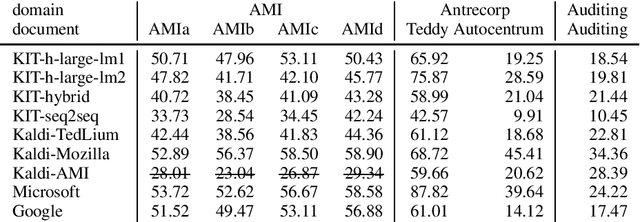
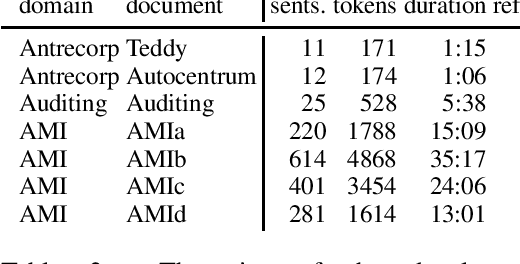
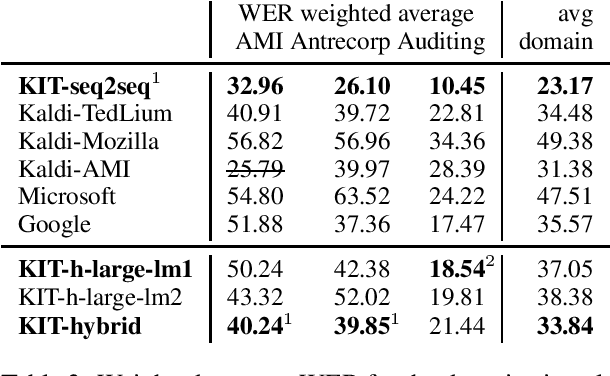

This paper is an ELITR system submission for the non-native speech translation task at IWSLT 2020. We describe systems for offline ASR, real-time ASR, and our cascaded approach to offline SLT and real-time SLT. We select our primary candidates from a pool of pre-existing systems, develop a new end-to-end general ASR system, and a hybrid ASR trained on non-native speech. The provided small validation set prevents us from carrying out a complex validation, but we submit all the unselected candidates for contrastive evaluation on the test set.
Dynamic Masking for Improved Stability in Spoken Language Translation
May 30, 2020
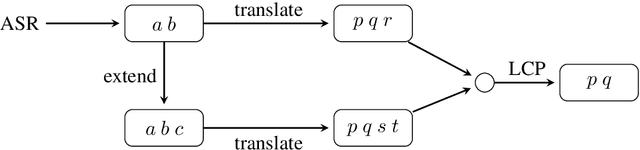
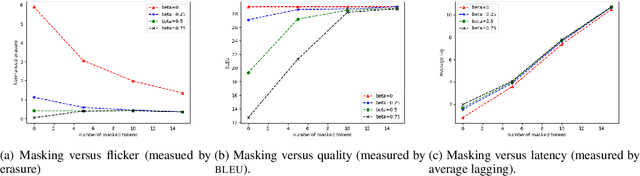
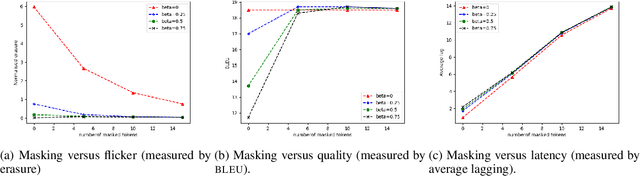
For spoken language translation (SLT) in live scenarios such as conferences, lectures and meetings, it is desirable to show the translation to the user as quickly as possible, avoiding an annoying lag between speaker and translated captions. In other words, we would like low-latency, online SLT. If we assume a pipeline of automatic speech recognition (ASR) and machine translation (MT) then a viable approach to online SLT is to pair an online ASR system, with a a retranslation strategy, where the MT system re-translates every update received from ASR. However this can result in annoying "flicker" as the MT system updates its translation. A possible solution is to add a fixed delay, or "mask" to the the output of the MT system, but a fixed global mask introduces undesirable latency to the output. We show how this mask can be set dynamically, improving the latency-flicker trade-off without sacrificing translation quality.