 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Masking for Improved Stability in Spoken Language Translation
Paper and Code

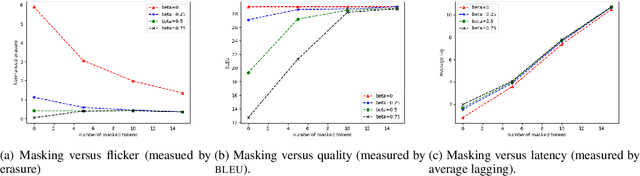
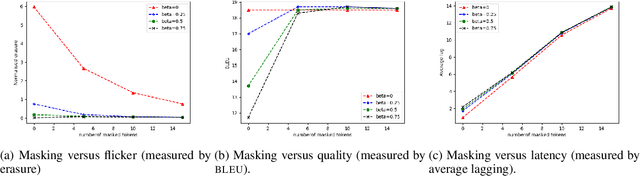
For spoken language translation (SLT) in live scenarios such as conferences, lectures and meetings, it is desirable to show the translation to the user as quickly as possible, avoiding an annoying lag between speaker and translated captions. In other words, we would like low-latency, online SLT. If we assume a pipeline of automatic speech recognition (ASR) and machine translation (MT) then a viable approach to online SLT is to pair an online ASR system, with a a retranslation strategy, where the MT system re-translates every update received from ASR. However this can result in annoying "flicker" as the MT system updates its translation. A possible solution is to add a fixed delay, or "mask" to the the output of the MT system, but a fixed global mask introduces undesirable latency to the output. We show how this mask can be set dynamically, improving the latency-flicker trade-off without sacrificing translation quality.