 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Interpreting: Speech Translation from Source or Interpreter?
Jun 17, 2021


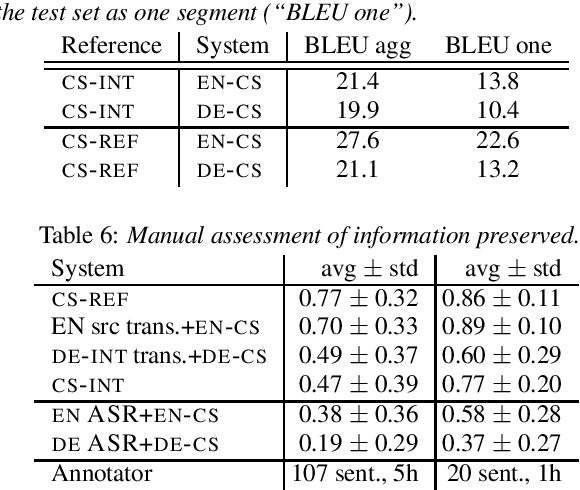
Interpreters facilitate multi-lingual meetings but the affordable set of languages is often smaller than what is needed. Automatic simultaneous speech translation can extend the set of provided languages. We investigate if such an automatic system should rather follow the original speaker, or an interpreter to achieve better translation quality at the cost of increased delay. To answer the question, we release Europarl Simultaneous Interpreting Corpus (ESIC), 10 hours of recordings and transcripts of European Parliament speeches in English, with simultaneous interpreting into Czech and German. We evaluate quality and latency of speaker-based and interpreter-based spoken translation systems from English to Czech. We study the differences in implicit simplification and summarization of the human interpreter compared to a machine translation system trained to shorten the output to some extent. Finally, we perform human evaluation to measure information loss of each of these approaches.
Backtranslation Feedback Improves User Confidence in MT, Not Quality
Apr 12, 2021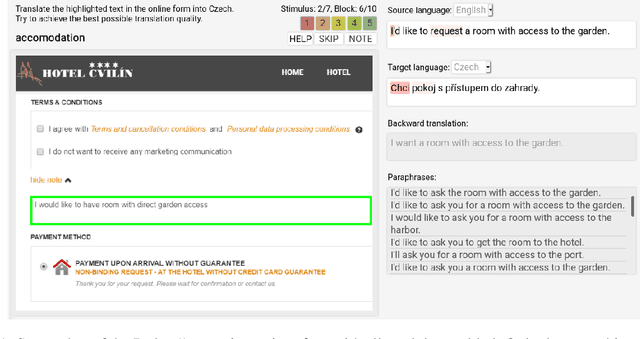
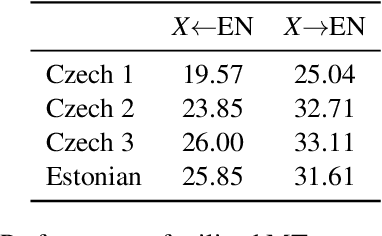
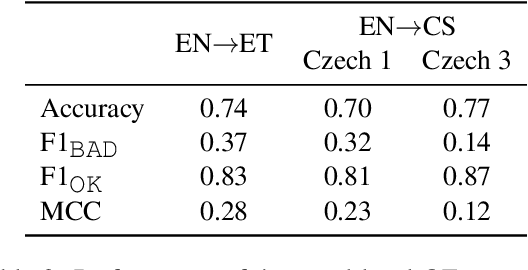
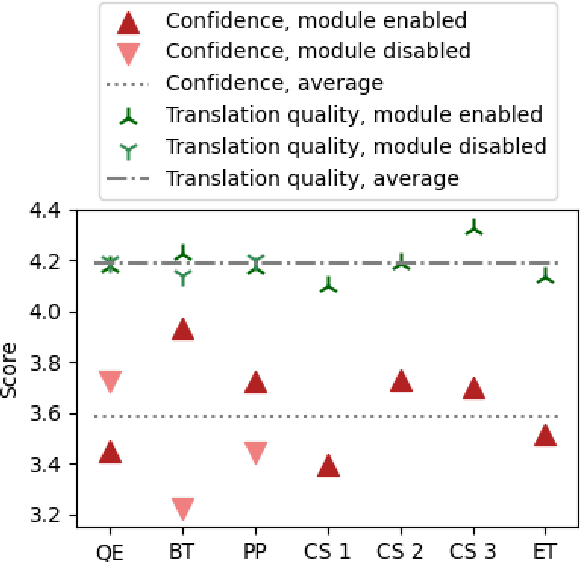
Translating text into a language unknown to the text's author, dubbed outbound translation, is a modern need for which the user experience has significant room for improvement, beyond the basic machine translation facility. We demonstrate this by showing three ways in which user confidence in the outbound translation, as well as its overall final quality, can be affected: backward translation, quality estimation (with alignment) and source paraphrasing. In this paper, we describe an experiment on outbound translation from English to Czech and Estonian. We examine the effects of each proposed feedback module and further focus on how the quality of machine translation systems influence these findings and the user perception of success. We show that backward translation feedback has a mixed effect on the whole process: it increases user confidence in the produced translation, but not the objective quality.
ELITR Non-Native Speech Translation at IWSLT 2020
Jun 05, 2020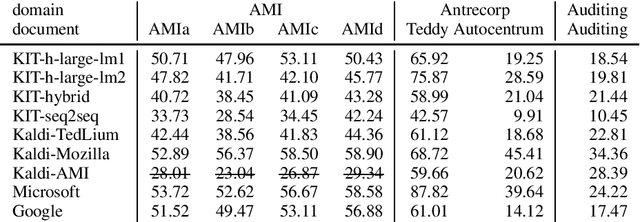
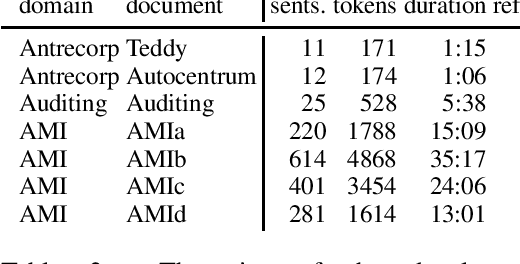
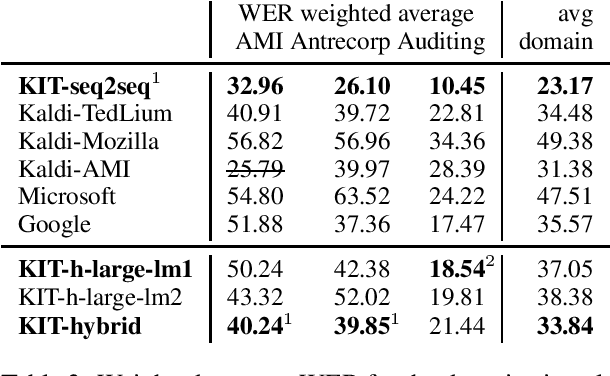

This paper is an ELITR system submission for the non-native speech translation task at IWSLT 2020. We describe systems for offline ASR, real-time ASR, and our cascaded approach to offline SLT and real-time SLT. We select our primary candidates from a pool of pre-existing systems, develop a new end-to-end general ASR system, and a hybrid ASR trained on non-native speech. The provided small validation set prevents us from carrying out a complex validation, but we submit all the unselected candidates for contrastive evaluation on the test set.