 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Uncertainty Estimation Scales with Sampling in Reasoning Models
Mar 19, 2026Uncertainty estimation is critical for deploying reasoning language models, yet remains poorly understood under extended chain-of-thought reasoning. We study parallel sampling as a fully black-box approach using verbalized confidence and self-consistency. Across three reasoning models and 17 tasks spanning mathematics, STEM, and humanities, we characterize how these signals scale. Both self-consistency and verbalized confidence scale in reasoning models, but self-consistency exhibits lower initial discrimination and lags behind verbalized confidence under moderate sampling. Most uncertainty gains, however, arise from signal combination: with just two samples, a hybrid estimator improves AUROC by up to $+12$ on average and already outperforms either signal alone even when scaled to much larger budgets, after which returns diminish. These effects are domain-dependent: in mathematics, the native domain of RLVR-style post-training, reasoning models achieve higher uncertainty quality and exhibit both stronger complementarity and faster scaling than in STEM or humanities.
Backtranslation Feedback Improves User Confidence in MT, Not Quality
Apr 12, 2021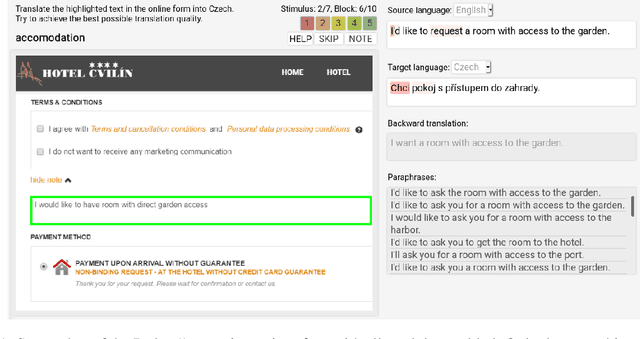
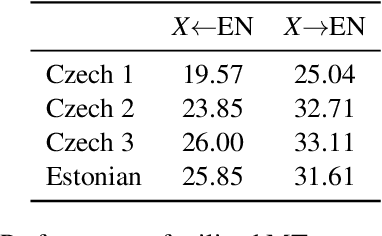
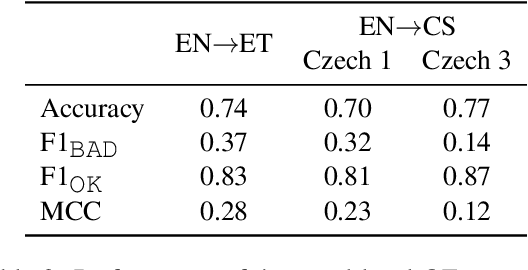
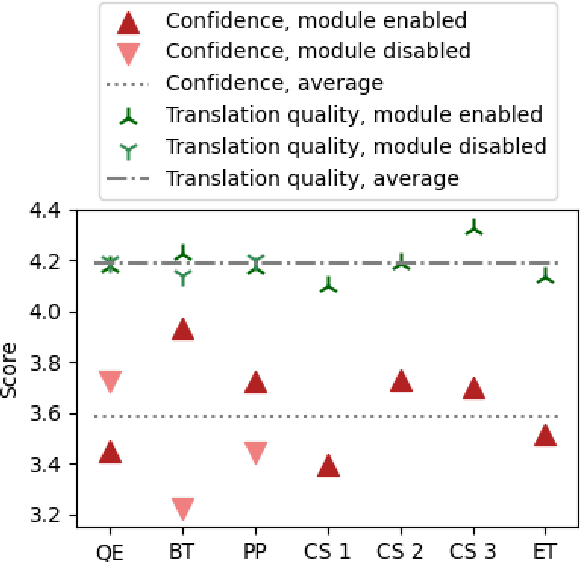
Translating text into a language unknown to the text's author, dubbed outbound translation, is a modern need for which the user experience has significant room for improvement, beyond the basic machine translation facility. We demonstrate this by showing three ways in which user confidence in the outbound translation, as well as its overall final quality, can be affected: backward translation, quality estimation (with alignment) and source paraphrasing. In this paper, we describe an experiment on outbound translation from English to Czech and Estonian. We examine the effects of each proposed feedback module and further focus on how the quality of machine translation systems influence these findings and the user perception of success. We show that backward translation feedback has a mixed effect on the whole process: it increases user confidence in the produced translation, but not the objective quality.
Unsupervised Quality Estimation for Neural Machine Translation
May 21, 2020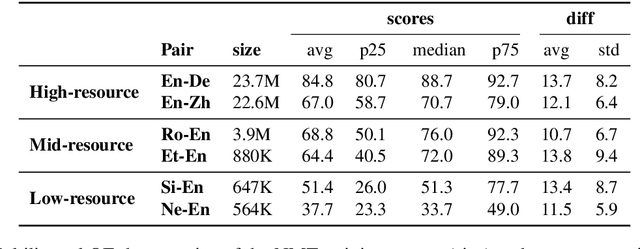
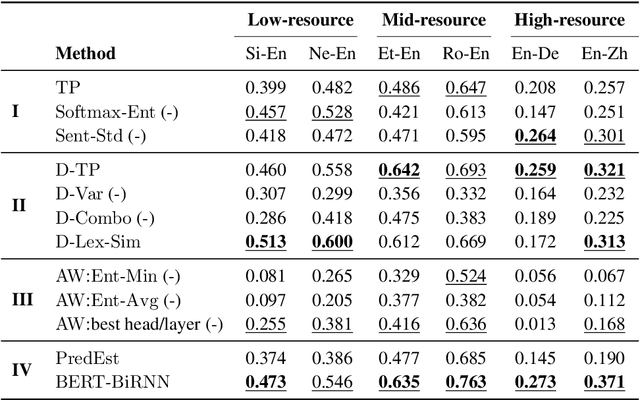
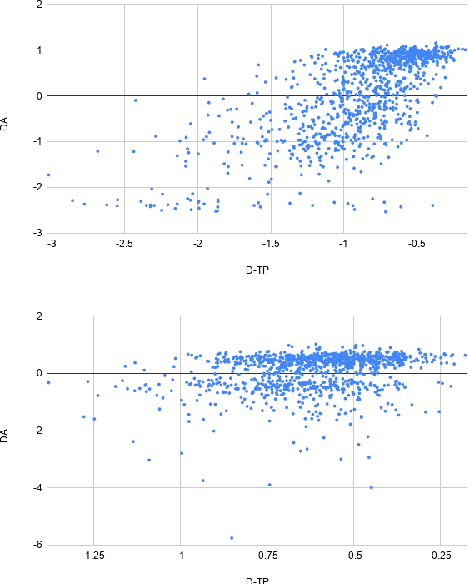
Quality Estimation (QE) is an important component in making Machine Translation (MT) useful in real-world applications, as it is aimed to inform the user on the quality of the MT output at test time. Existing approaches require large amounts of expert annotated data, computation and time for training. As an alternative, we devise an unsupervised approach to QE where no training or access to additional resources besides the MT system itself is required. Different from most of the current work that treats the MT system as a black box, we explore useful information that can be extracted from the MT system as a by-product of translation. By employing methods for uncertainty quantification, we achieve very good correlation with human judgments of quality, rivalling state-of-the-art supervised QE models. To evaluate our approach we collect the first dataset that enables work on both black-box and glass-box approaches to QE.
Explicit Representation of the Translation Space: Automatic Paraphrasing for Machine Translation Evaluation
Apr 30, 2020


Following previous work on automatic paraphrasing, we assess the feasibility of improving BLEU (Papineni et al., 2002) using state-of-the-art neural paraphrasing techniques to generate additional references. We explore the extent to which diverse paraphrases can adequately cover the space of valid translations and compare to an alternative approach of generating paraphrases constrained by MT outputs. We compare both approaches to human-produced references in terms of diversity and the improvement in BLEU's correlation with human judgements of MT quality. Our experiments on the WMT19 metrics tasks for all into-English language directions show that somewhat surprisingly, the addition of diverse paraphrases, even those produced by humans, leads to only small, inconsistent changes in BLEU's correlation with human judgments, suggesting that BLEU's ability to correctly exploit multiple references is limited