 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling meaning from language in LLM-based machine translation
Feb 04, 2026Mechanistic Interpretability (MI) seeks to explain how neural networks implement their capabilities, but the scale of Large Language Models (LLMs) has limited prior MI work in Machine Translation (MT) to word-level analyses. We study sentence-level MT from a mechanistic perspective by analyzing attention heads to understand how LLMs internally encode and distribute translation functions. We decompose MT into two subtasks: producing text in the target language (i.e. target language identification) and preserving the input sentence's meaning (i.e. sentence equivalence). Across three families of open-source models and 20 translation directions, we find that distinct, sparse sets of attention heads specialize in each subtask. Based on this insight, we construct subtask-specific steering vectors and show that modifying just 1% of the relevant heads enables instruction-free MT performance comparable to instruction-based prompting, while ablating these heads selectively disrupts their corresponding translation functions.
When the Gold Standard isn't Necessarily Standard: Challenges of Evaluating the Translation of User-Generated Content
Dec 19, 2025



User-generated content (UGC) is characterised by frequent use of non-standard language, from spelling errors to expressive choices such as slang, character repetitions, and emojis. This makes evaluating UGC translation particularly challenging: what counts as a "good" translation depends on the level of standardness desired in the output. To explore this, we examine the human translation guidelines of four UGC datasets, and derive a taxonomy of twelve non-standard phenomena and five translation actions (NORMALISE, COPY, TRANSFER, OMIT, CENSOR). Our analysis reveals notable differences in how UGC is treated, resulting in a spectrum of standardness in reference translations. Through a case study on large language models (LLMs), we show that translation scores are highly sensitive to prompts with explicit translation instructions for UGC, and that they improve when these align with the dataset's guidelines. We argue that when preserving UGC style is important, fair evaluation requires both models and metrics to be aware of translation guidelines. Finally, we call for clear guidelines during dataset creation and for the development of controllable, guideline-aware evaluation frameworks for UGC translation.
Gaperon: A Peppered English-French Generative Language Model Suite
Oct 29, 2025We release Gaperon, a fully open suite of French-English-coding language models designed to advance transparency and reproducibility in large-scale model training. The Gaperon family includes 1.5B, 8B, and 24B parameter models trained on 2-4 trillion tokens, released with all elements of the training pipeline: French and English datasets filtered with a neural quality classifier, an efficient data curation and training framework, and hundreds of intermediate checkpoints. Through this work, we study how data filtering and contamination interact to shape both benchmark and generative performance. We find that filtering for linguistic quality enhances text fluency and coherence but yields subpar benchmark results, and that late deliberate contamination -- continuing training on data mixes that include test sets -- recovers competitive scores while only reasonably harming generation quality. We discuss how usual neural filtering can unintentionally amplify benchmark leakage. To support further research, we also introduce harmless data poisoning during pretraining, providing a realistic testbed for safety studies. By openly releasing all models, datasets, code, and checkpoints, Gaperon establishes a reproducible foundation for exploring the trade-offs between data curation, evaluation, safety, and openness in multilingual language model development.
TopXGen: Topic-Diverse Parallel Data Generation for Low-Resource Machine Translation
Aug 12, 2025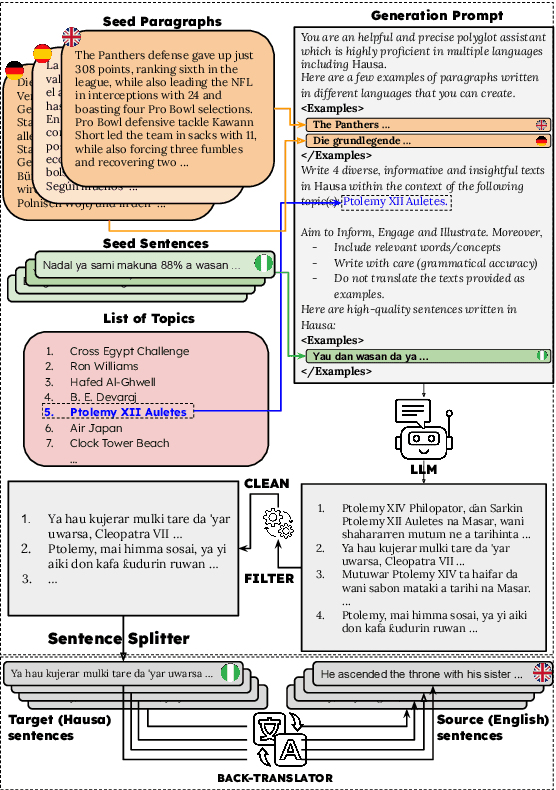

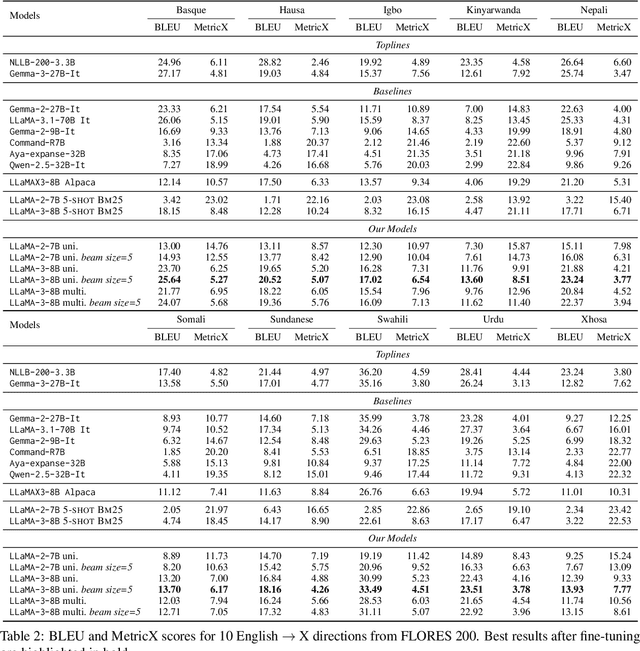
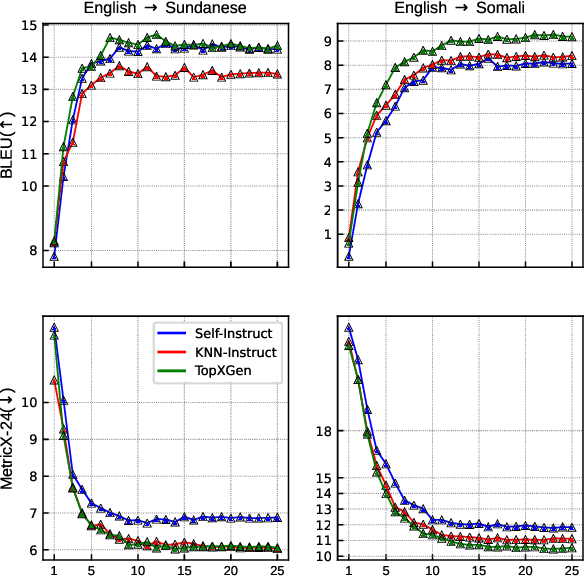
LLMs have been shown to perform well in machine translation (MT) with the use of in-context learning (ICL), rivaling supervised models when translating into high-resource languages (HRLs). However, they lag behind when translating into low-resource language (LRLs). Example selection via similarity search and supervised fine-tuning help. However the improvements they give are limited by the size, quality and diversity of existing parallel datasets. A common technique in low-resource MT is synthetic parallel data creation, the most frequent of which is backtranslation, whereby existing target-side texts are automatically translated into the source language. However, this assumes the existence of good quality and relevant target-side texts, which are not readily available for many LRLs. In this paper, we present \textsc{TopXGen}, an LLM-based approach for the generation of high quality and topic-diverse data in multiple LRLs, which can then be backtranslated to produce useful and diverse parallel texts for ICL and fine-tuning. Our intuition is that while LLMs struggle to translate into LRLs, their ability to translate well into HRLs and their multilinguality enable them to generate good quality, natural-sounding target-side texts, which can be translated well into a high-resource source language. We show that \textsc{TopXGen} boosts LLM translation performance during fine-tuning and in-context learning. Code and outputs are available at https://github.com/ArmelRandy/topxgen.
Explicit Learning and the LLM in Machine Translation
Mar 12, 2025



This study explores the capacity of large language models (LLMs) for explicit learning, a process involving the assimilation of metalinguistic explanations to carry out language tasks. Using constructed languages generated by cryptographic means as controlled test environments, we designed experiments to assess an LLM's ability to explicitly learn and apply grammar rules. Our results demonstrate that while LLMs possess a measurable capacity for explicit learning, this ability diminishes as the complexity of the linguistic phenomena at hand increases. Supervised fine-tuning on chains of thought significantly enhances LLM performance but struggles to generalize to typologically novel or more complex linguistic features. These findings point to the need for more diverse training sets and alternative fine-tuning strategies to further improve explicit learning by LLMs.
Compositional Translation: A Novel LLM-based Approach for Low-resource Machine Translation
Mar 06, 2025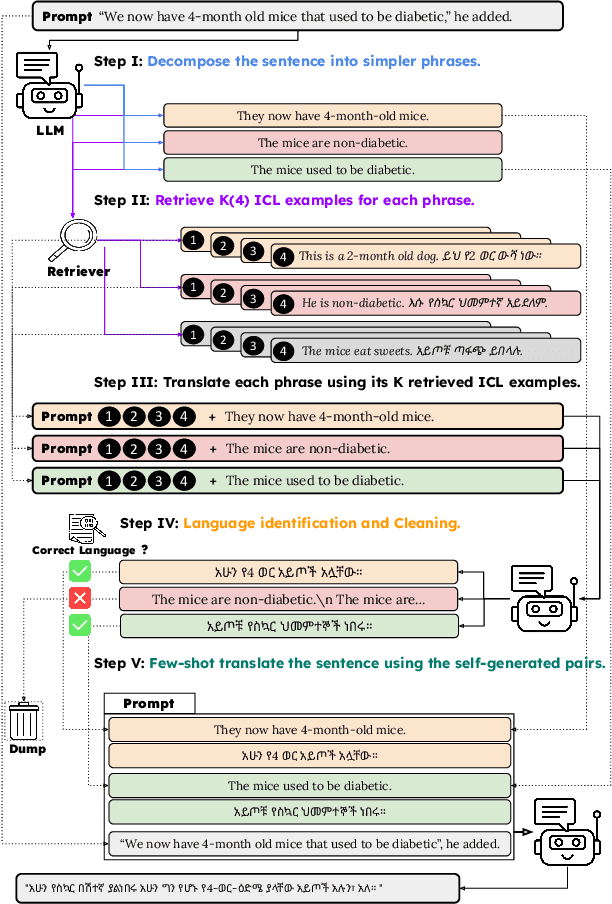
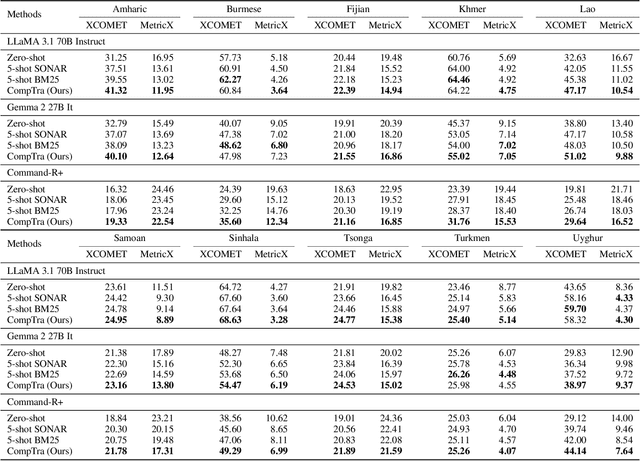
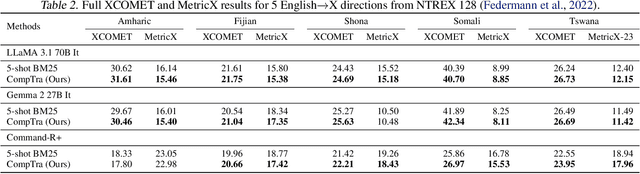
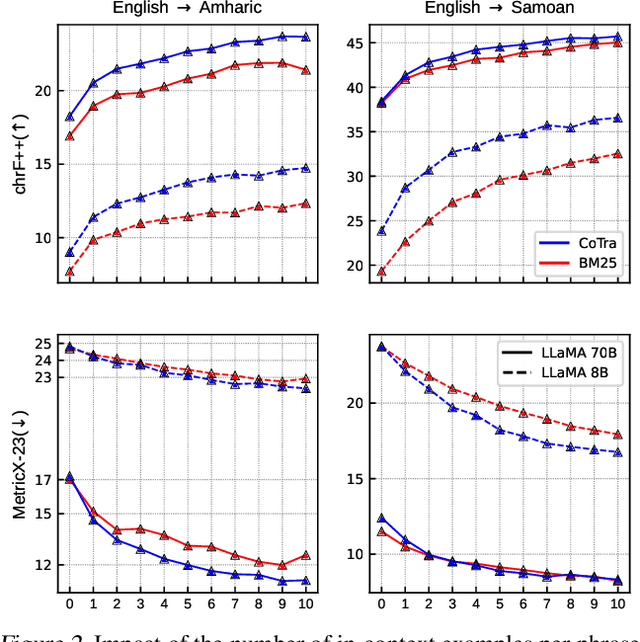
The ability of generative large language models (LLMs) to perform in-context learning has given rise to a large body of research into how best to prompt models for various natural language processing tasks. Machine Translation (MT) has been shown to benefit from in-context examples, in particular when they are semantically similar to the sentence to translate. In this paper, we propose a new LLM-based translation paradigm, compositional translation, to replace naive few-shot MT with similarity-based demonstrations. An LLM is used to decompose a sentence into simpler phrases, and then to translate each phrase with the help of retrieved demonstrations. Finally, the LLM is prompted to translate the initial sentence with the help of the self-generated phrase-translation pairs. Our intuition is that this approach should improve translation because these shorter phrases should be intrinsically easier to translate and easier to match with relevant examples. This is especially beneficial in low-resource scenarios, and more generally whenever the selection pool is small or out of domain. We show that compositional translation boosts LLM translation performance on a wide range of popular MT benchmarks, including FLORES 200, NTREX 128 and TICO-19. Code and outputs are available at https://github.com/ArmelRandy/compositional-translation
AFRIDOC-MT: Document-level MT Corpus for African Languages
Jan 10, 2025



This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yor\`ub\'a, and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating neural machine translation (NMT) models and large language models (LLMs) for translations between English and these languages, at both the sentence and pseudo-document levels. These outputs are realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieved the best average performance among the standard NMT models, while GPT-4o outperformed general-purpose LLMs. Fine-tuning selected models led to substantial performance gains, but models trained on sentences struggled to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, repetition of words or phrases, and off-target translations, especially for African languages.
Investigating Length Issues in Document-level Machine Translation
Dec 23, 2024Transformer architectures are increasingly effective at processing and generating very long chunks of texts, opening new perspectives for document-level machine translation (MT). In this work, we challenge the ability of MT systems to handle texts comprising up to several thousands of tokens. We design and implement a new approach designed to precisely measure the effect of length increments on MT outputs. Our experiments with two representative architectures unambiguously show that (a)~translation performance decreases with the length of the input text; (b)~the position of sentences within the document matters and translation quality is higher for sentences occurring earlier in a document. We further show that manipulating the distribution of document lengths and of positional embeddings only marginally mitigates such problems. Our results suggest that even though document-level MT is computationally feasible, it does not yet match the performance of sentence-based MT.
Tree of Problems: Improving structured problem solving with compositionality
Oct 09, 2024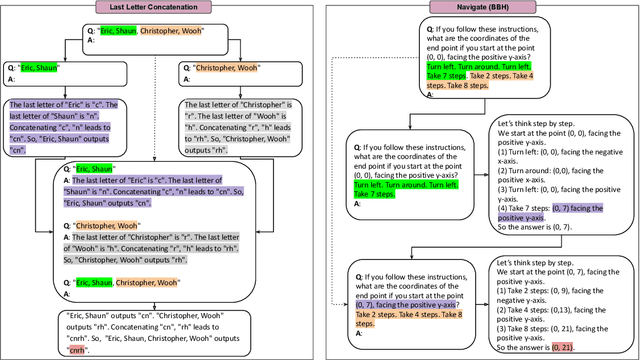
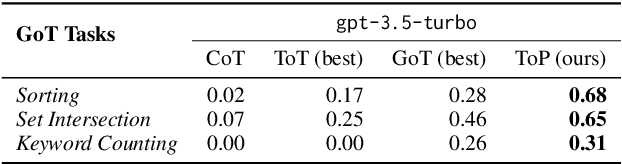

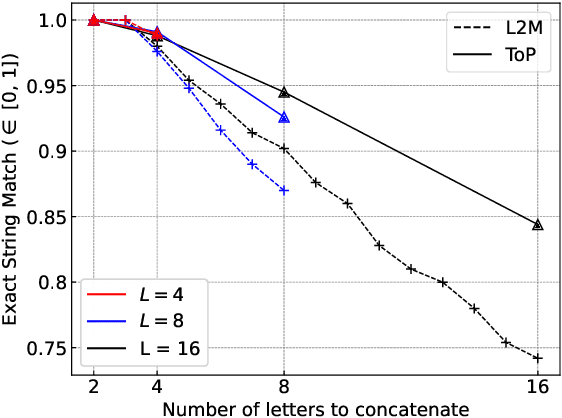
Large Language Models (LLMs) have demonstrated remarkable performance across multiple tasks through in-context learning. For complex reasoning tasks that require step-by-step thinking, Chain-of-Thought (CoT) prompting has given impressive results, especially when combined with self-consistency. Nonetheless, some tasks remain particularly difficult for LLMs to solve. Tree of Thoughts (ToT) and Graph of Thoughts (GoT) emerged as alternatives, dividing the complex problem into paths of subproblems. In this paper, we propose Tree of Problems (ToP), a simpler version of ToT, which we hypothesise can work better for complex tasks that can be divided into identical subtasks. Our empirical results show that our approach outperforms ToT and GoT, and in addition performs better than CoT on complex reasoning tasks. All code for this paper is publicly available here: https://github.com/ArmelRandy/tree-of-problems.
In-Context Example Selection via Similarity Search Improves Low-Resource Machine Translation
Aug 01, 2024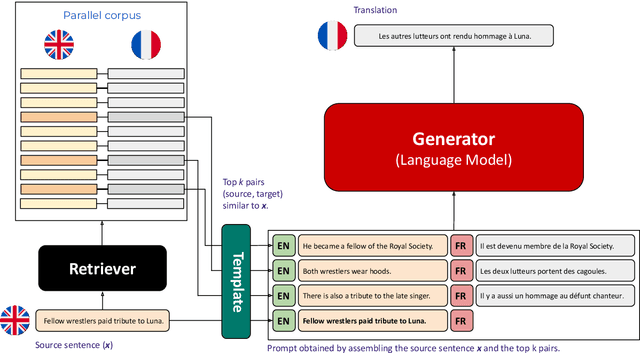

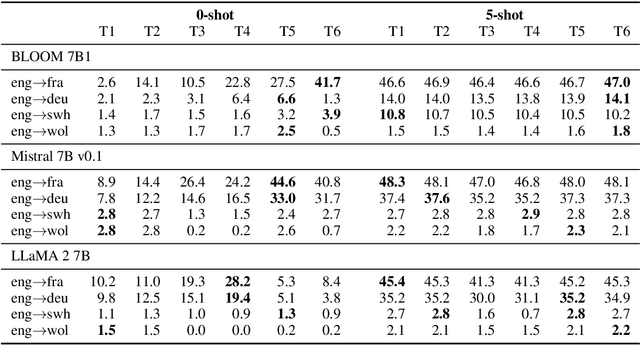
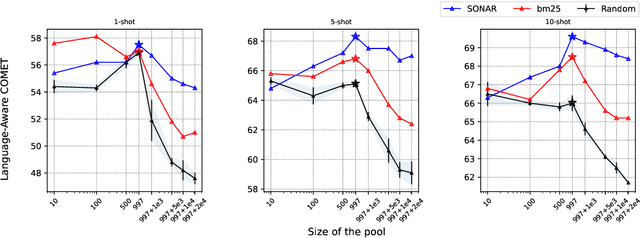
The ability of generative large language models (LLMs) to perform in-context learning has given rise to a large body of research into how best to prompt models for various natural language processing tasks. In this paper, we focus on machine translation (MT), a task that has been shown to benefit from in-context translation examples. However no systematic studies have been published on how best to select examples, and mixed results have been reported on the usefulness of similarity-based selection over random selection. We provide a study covering multiple LLMs and multiple in-context example retrieval strategies, comparing multilingual sentence embeddings. We cover several language directions, representing different levels of language resourcedness (English into French, German, Swahili and Wolof). Contrarily to previously published results, we find that sentence embedding similarity can improve MT, especially for low-resource language directions, and discuss the balance between selection pool diversity and quality. We also highlight potential problems with the evaluation of LLM-based MT and suggest a more appropriate evaluation protocol, adapting the COMET metric to the evaluation of LLMs. Code and outputs are freely available at https://github.com/ArmelRandy/ICL-MT.