 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe TUB Sign Language Corpus Collection
Aug 07, 2025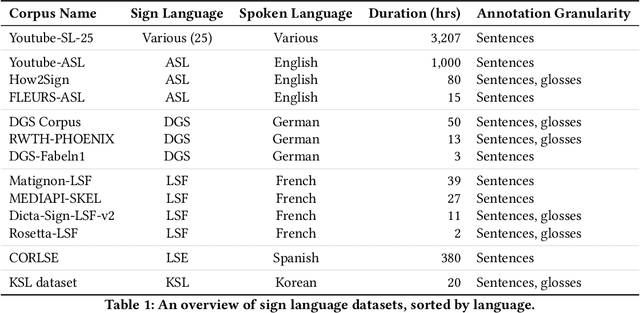
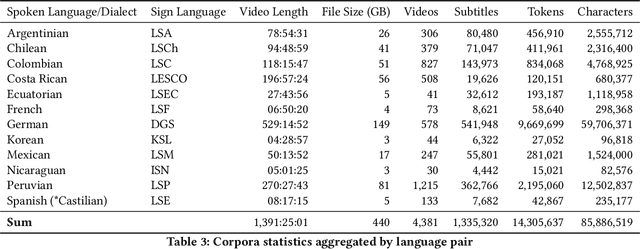
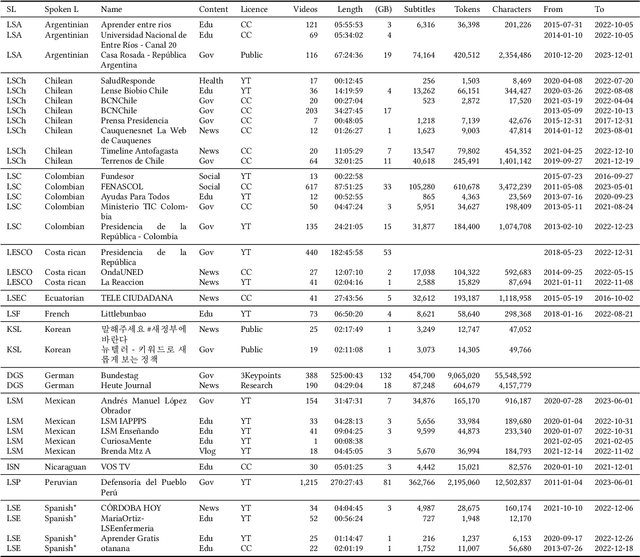
We present a collection of parallel corpora of 12 sign languages in video format, together with subtitles in the dominant spoken languages of the corresponding countries. The entire collection includes more than 1,300 hours in 4,381 video files, accompanied by 1,3~M subtitles containing 14~M tokens. Most notably, it includes the first consistent parallel corpora for 8 Latin American sign languages, whereas the size of the German Sign Language corpora is ten times the size of the previously available corpora. The collection was created by collecting and processing videos of multiple sign languages from various online sources, mainly broadcast material of news shows, governmental bodies and educational channels. The preparation involved several stages, including data collection, informing the content creators and seeking usage approvals, scraping, and cropping. The paper provides statistics on the collection and an overview of the methods used to collect the data.
Evaluation of a Sign Language Avatar on Comprehensibility, User Experience \& Acceptability
Aug 07, 2025This paper presents an investigation into the impact of adding adjustment features to an existing sign language (SL) avatar on a Microsoft Hololens 2 device. Through a detailed analysis of interactions of expert German Sign Language (DGS) users with both adjustable and non-adjustable avatars in a specific use case, this study identifies the key factors influencing the comprehensibility, the user experience (UX), and the acceptability of such a system. Despite user preference for adjustable settings, no significant improvements in UX or comprehensibility were observed, which remained at low levels, amid missing SL elements (mouthings and facial expressions) and implementation issues (indistinct hand shapes, lack of feedback and menu positioning). Hedonic quality was rated higher than pragmatic quality, indicating that users found the system more emotionally or aesthetically pleasing than functionally useful. Stress levels were higher for the adjustable avatar, reflecting lower performance, greater effort and more frustration. Additionally, concerns were raised about whether the Hololens adjustment gestures are intuitive and easy to familiarise oneself with. While acceptability of the concept of adjustability was generally positive, it was strongly dependent on usability and animation quality. This study highlights that personalisation alone is insufficient, and that SL avatars must be comprehensible by default. Key recommendations include enhancing mouthing and facial animation, improving interaction interfaces, and applying participatory design.
The Importance of Facial Features in Vision-based Sign Language Recognition: Eyes, Mouth or Full Face?
Jul 28, 2025Non-manual facial features play a crucial role in sign language communication, yet their importance in automatic sign language recognition (ASLR) remains underexplored. While prior studies have shown that incorporating facial features can improve recognition, related work often relies on hand-crafted feature extraction and fails to go beyond the comparison of manual features versus the combination of manual and facial features. In this work, we systematically investigate the contribution of distinct facial regionseyes, mouth, and full faceusing two different deep learning models (a CNN-based model and a transformer-based model) trained on an SLR dataset of isolated signs with randomly selected classes. Through quantitative performance and qualitative saliency map evaluation, we reveal that the mouth is the most important non-manual facial feature, significantly improving accuracy. Our findings highlight the necessity of incorporating facial features in ASLR.
Transfer Learning from Visual Speech Recognition to Mouthing Recognition in German Sign Language
May 20, 2025Sign Language Recognition (SLR) systems primarily focus on manual gestures, but non-manual features such as mouth movements, specifically mouthing, provide valuable linguistic information. This work directly classifies mouthing instances to their corresponding words in the spoken language while exploring the potential of transfer learning from Visual Speech Recognition (VSR) to mouthing recognition in German Sign Language. We leverage three VSR datasets: one in English, one in German with unrelated words and one in German containing the same target words as the mouthing dataset, to investigate the impact of task similarity in this setting. Our results demonstrate that multi-task learning improves both mouthing recognition and VSR accuracy as well as model robustness, suggesting that mouthing recognition should be treated as a distinct but related task to VSR. This research contributes to the field of SLR by proposing knowledge transfer from VSR to SLR datasets with limited mouthing annotations.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation
Jun 17, 2024



High-quality Machine Translation (MT) evaluation relies heavily on human judgments. Comprehensive error classification methods, such as Multidimensional Quality Metrics (MQM), are expensive as they are time-consuming and can only be done by experts, whose availability may be limited especially for low-resource languages. On the other hand, just assigning overall scores, like Direct Assessment (DA), is simpler and faster and can be done by translators of any level, but are less reliable. In this paper, we introduce Error Span Annotation (ESA), a human evaluation protocol which combines the continuous rating of DA with the high-level error severity span marking of MQM. We validate ESA by comparing it to MQM and DA for 12 MT systems and one human reference translation (English to German) from WMT23. The results show that ESA offers faster and cheaper annotations than MQM at the same quality level, without the requirement of expensive MQM experts.
Fine-grained linguistic evaluation for state-of-the-art Machine Translation
Oct 14, 2020
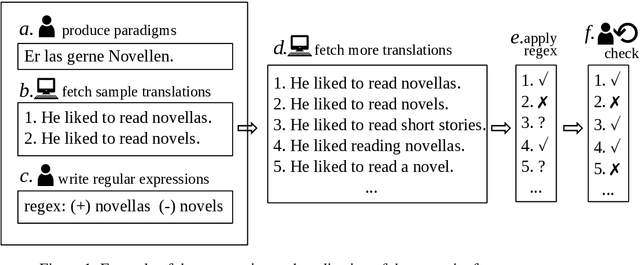

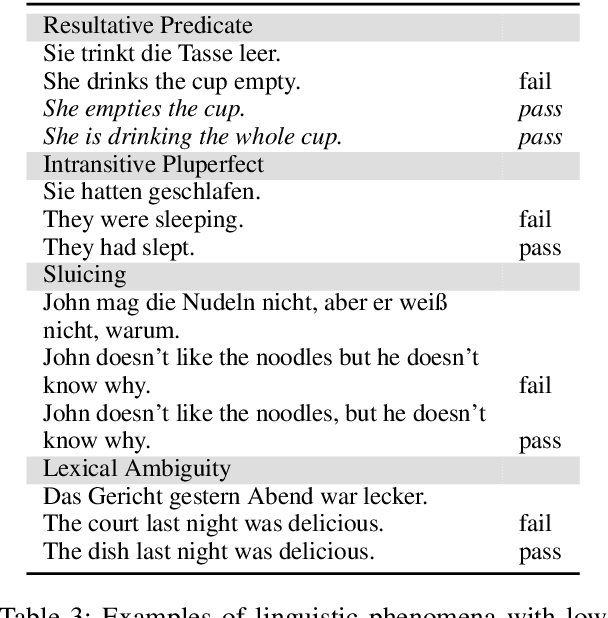
This paper describes a test suite submission providing detailed statistics of linguistic performance for the state-of-the-art German-English systems of the Fifth Conference of Machine Translation (WMT20). The analysis covers 107 phenomena organized in 14 categories based on about 5,500 test items, including a manual annotation effort of 45 person hours. Two systems (Tohoku and Huoshan) appear to have significantly better test suite accuracy than the others, although the best system of WMT20 is not significantly better than the one from WMT19 in a macro-average. Additionally, we identify some linguistic phenomena where all systems suffer (such as idioms, resultative predicates and pluperfect), but we are also able to identify particular weaknesses for individual systems (such as quotation marks, lexical ambiguity and sluicing). Most of the systems of WMT19 which submitted new versions this year show improvements.
Fine-grained evaluation of German-English Machine Translation based on a Test Suite
Oct 16, 2019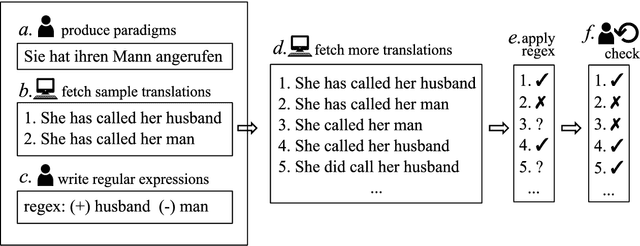
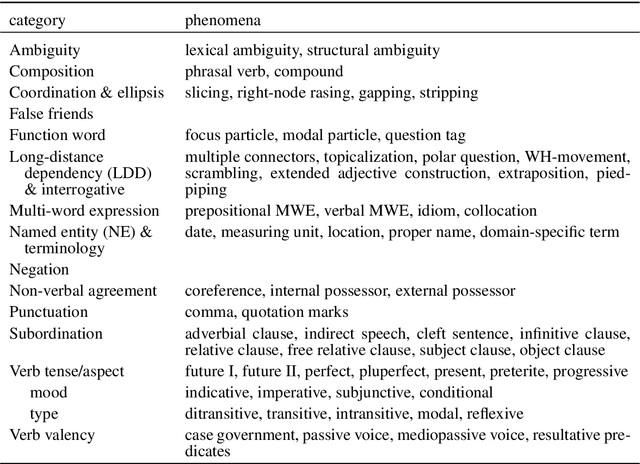
We present an analysis of 16 state-of-the-art MT systems on German-English based on a linguistically-motivated test suite. The test suite has been devised manually by a team of language professionals in order to cover a broad variety of linguistic phenomena that MT often fails to translate properly. It contains 5,000 test sentences covering 106 linguistic phenomena in 14 categories, with an increased focus on verb tenses, aspects and moods. The MT outputs are evaluated in a semi-automatic way through regular expressions that focus only on the part of the sentence that is relevant to each phenomenon. Through our analysis, we are able to compare systems based on their performance on these categories. Additionally, we reveal strengths and weaknesses of particular systems and we identify grammatical phenomena where the overall performance of MT is relatively low.
Linguistic evaluation of German-English Machine Translation using a Test Suite
Oct 16, 2019

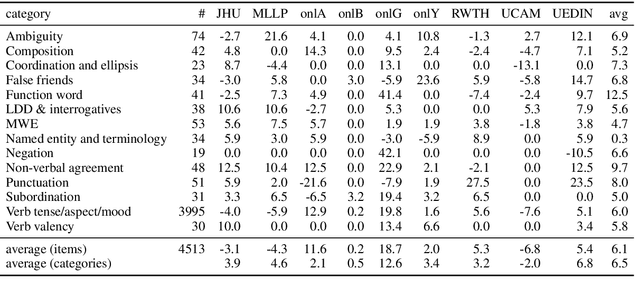
We present the results of the application of a grammatical test suite for German$\rightarrow$English MT on the systems submitted at WMT19, with a detailed analysis for 107 phenomena organized in 14 categories. The systems still translate wrong one out of four test items in average. Low performance is indicated for idioms, modals, pseudo-clefts, multi-word expressions and verb valency. When compared to last year, there has been a improvement of function words, non-verbal agreement and punctuation. More detailed conclusions about particular systems and phenomena are also presented.
Train, Sort, Explain: Learning to Diagnose Translation Models
Mar 28, 2019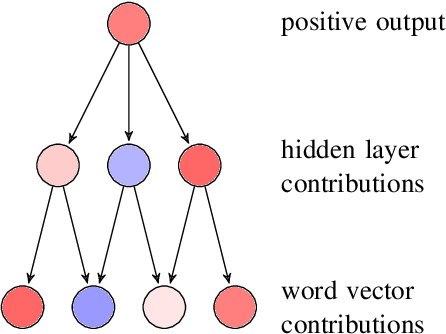

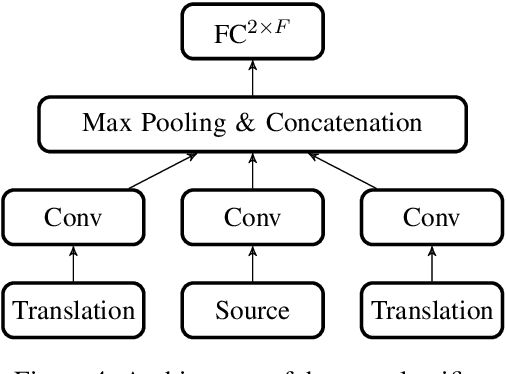
Evaluating translation models is a trade-off between effort and detail. On the one end of the spectrum there are automatic count-based methods such as BLEU, on the other end linguistic evaluations by humans, which arguably are more informative but also require a disproportionately high effort. To narrow the spectrum, we propose a general approach on how to automatically expose systematic differences between human and machine translations to human experts. Inspired by adversarial settings, we train a neural text classifier to distinguish human from machine translations. A classifier that performs and generalizes well after training should recognize systematic differences between the two classes, which we uncover with neural explainability methods. Our proof-of-concept implementation, DiaMaT, is open source. Applied to a dataset translated by a state-of-the-art neural Transformer model, DiaMaT achieves a classification accuracy of 75% and exposes meaningful differences between humans and the Transformer, amidst the current discussion about human parity.