 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained linguistic evaluation for state-of-the-art Machine Translation
Oct 14, 2020

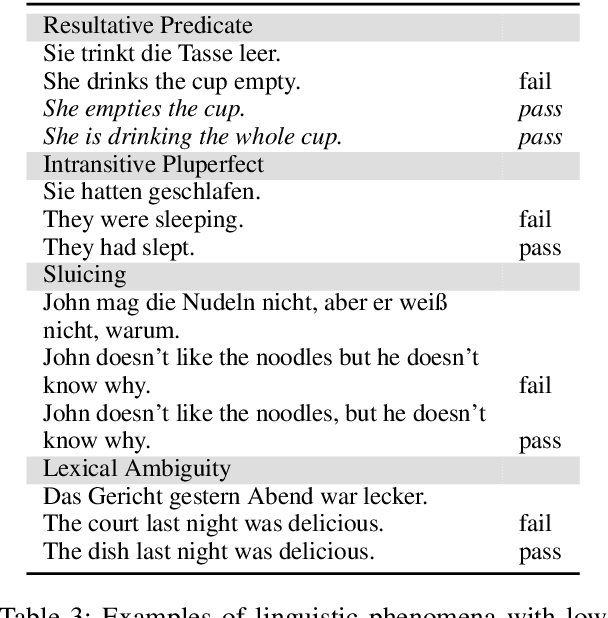
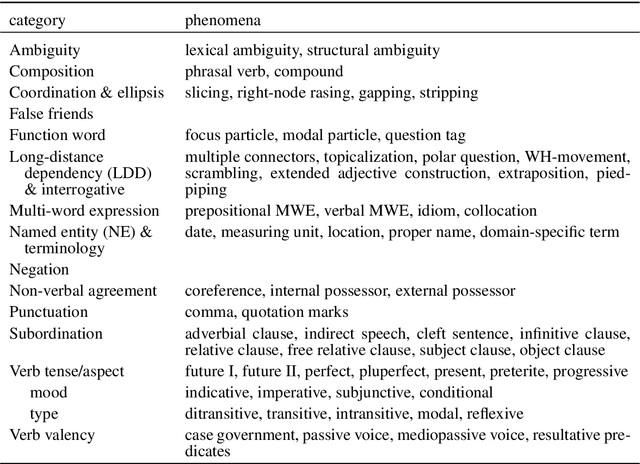
This paper describes a test suite submission providing detailed statistics of linguistic performance for the state-of-the-art German-English systems of the Fifth Conference of Machine Translation (WMT20). The analysis covers 107 phenomena organized in 14 categories based on about 5,500 test items, including a manual annotation effort of 45 person hours. Two systems (Tohoku and Huoshan) appear to have significantly better test suite accuracy than the others, although the best system of WMT20 is not significantly better than the one from WMT19 in a macro-average. Additionally, we identify some linguistic phenomena where all systems suffer (such as idioms, resultative predicates and pluperfect), but we are also able to identify particular weaknesses for individual systems (such as quotation marks, lexical ambiguity and sluicing). Most of the systems of WMT19 which submitted new versions this year show improvements.
Fine-grained evaluation of Quality Estimation for Machine translation based on a linguistically-motivated Test Suite
Oct 16, 2019



We present an alternative method of evaluating Quality Estimation systems, which is based on a linguistically-motivated Test Suite. We create a test-set consisting of 14 linguistic error categories and we gather for each of them a set of samples with both correct and erroneous translations. Then, we measure the performance of 5 Quality Estimation systems by checking their ability to distinguish between the correct and the erroneous translations. The detailed results are much more informative about the ability of each system. The fact that different Quality Estimation systems perform differently at various phenomena confirms the usefulness of the Test Suite.
Fine-grained evaluation of German-English Machine Translation based on a Test Suite
Oct 16, 2019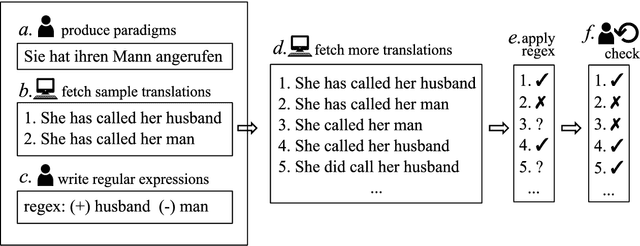
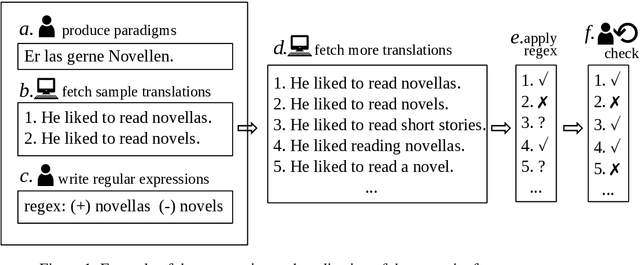
We present an analysis of 16 state-of-the-art MT systems on German-English based on a linguistically-motivated test suite. The test suite has been devised manually by a team of language professionals in order to cover a broad variety of linguistic phenomena that MT often fails to translate properly. It contains 5,000 test sentences covering 106 linguistic phenomena in 14 categories, with an increased focus on verb tenses, aspects and moods. The MT outputs are evaluated in a semi-automatic way through regular expressions that focus only on the part of the sentence that is relevant to each phenomenon. Through our analysis, we are able to compare systems based on their performance on these categories. Additionally, we reveal strengths and weaknesses of particular systems and we identify grammatical phenomena where the overall performance of MT is relatively low.
Linguistic evaluation of German-English Machine Translation using a Test Suite
Oct 16, 2019

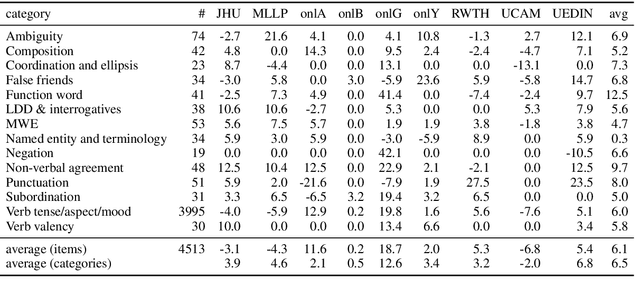
We present the results of the application of a grammatical test suite for German$\rightarrow$English MT on the systems submitted at WMT19, with a detailed analysis for 107 phenomena organized in 14 categories. The systems still translate wrong one out of four test items in average. Low performance is indicated for idioms, modals, pseudo-clefts, multi-word expressions and verb valency. When compared to last year, there has been a improvement of function words, non-verbal agreement and punctuation. More detailed conclusions about particular systems and phenomena are also presented.
Train, Sort, Explain: Learning to Diagnose Translation Models
Mar 28, 2019

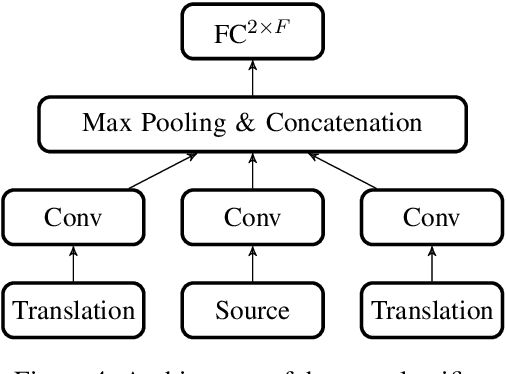
Evaluating translation models is a trade-off between effort and detail. On the one end of the spectrum there are automatic count-based methods such as BLEU, on the other end linguistic evaluations by humans, which arguably are more informative but also require a disproportionately high effort. To narrow the spectrum, we propose a general approach on how to automatically expose systematic differences between human and machine translations to human experts. Inspired by adversarial settings, we train a neural text classifier to distinguish human from machine translations. A classifier that performs and generalizes well after training should recognize systematic differences between the two classes, which we uncover with neural explainability methods. Our proof-of-concept implementation, DiaMaT, is open source. Applied to a dataset translated by a state-of-the-art neural Transformer model, DiaMaT achieves a classification accuracy of 75% and exposes meaningful differences between humans and the Transformer, amidst the current discussion about human parity.