 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Size Fits None: Rethinking Fairness in Medical AI
Jun 17, 2025Machine learning (ML) models are increasingly used to support clinical decision-making. However, real-world medical datasets are often noisy, incomplete, and imbalanced, leading to performance disparities across patient subgroups. These differences raise fairness concerns, particularly when they reinforce existing disadvantages for marginalized groups. In this work, we analyze several medical prediction tasks and demonstrate how model performance varies with patient characteristics. While ML models may demonstrate good overall performance, we argue that subgroup-level evaluation is essential before integrating them into clinical workflows. By conducting a performance analysis at the subgroup level, differences can be clearly identified-allowing, on the one hand, for performance disparities to be considered in clinical practice, and on the other hand, for these insights to inform the responsible development of more effective models. Thereby, our work contributes to a practical discussion around the subgroup-sensitive development and deployment of medical ML models and the interconnectedness of fairness and transparency.
Pragmatic auditing: a pilot-driven approach for auditing Machine Learning systems
May 21, 2024



The growing adoption and deployment of Machine Learning (ML) systems came with its share of ethical incidents and societal concerns. It also unveiled the necessity to properly audit these systems in light of ethical principles. For such a novel type of algorithmic auditing to become standard practice, two main prerequisites need to be available: A lifecycle model that is tailored towards transparency and accountability, and a principled risk assessment procedure that allows the proper scoping of the audit. Aiming to make a pragmatic step towards a wider adoption of ML auditing, we present a respective procedure that extends the AI-HLEG guidelines published by the European Commission. Our audit procedure is based on an ML lifecycle model that explicitly focuses on documentation, accountability, and quality assurance; and serves as a common ground for alignment between the auditors and the audited organisation. We describe two pilots conducted on real-world use cases from two different organisations and discuss the shortcomings of ML algorithmic auditing as well as future directions thereof.
When Performance is not Enough -- A Multidisciplinary View on Clinical Decision Support
Apr 27, 2022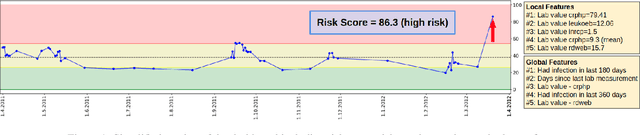
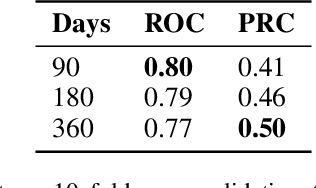
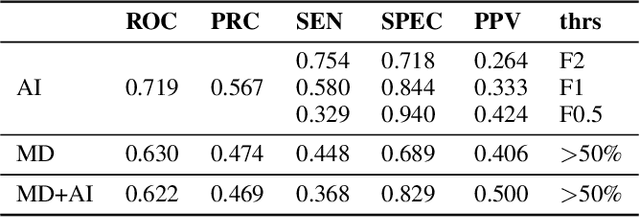

Scientific publications about machine learning in healthcare are often about implementing novel methods and boosting the performance - at least from a computer science perspective. However, beyond such often short-lived improvements, much more needs to be taken into consideration if we want to arrive at a sustainable progress in healthcare. What does it take to actually implement such a system, make it usable for the domain expert, and possibly bring it into practical usage? Targeted at Computer Scientists, this work presents a multidisciplinary view on machine learning in medical decision support systems and covers information technology, medical, as well as ethical aspects. Along with an implemented risk prediction system in nephrology, challenges and lessons learned in a pilot project are presented.
Fine-grained linguistic evaluation for state-of-the-art Machine Translation
Oct 14, 2020

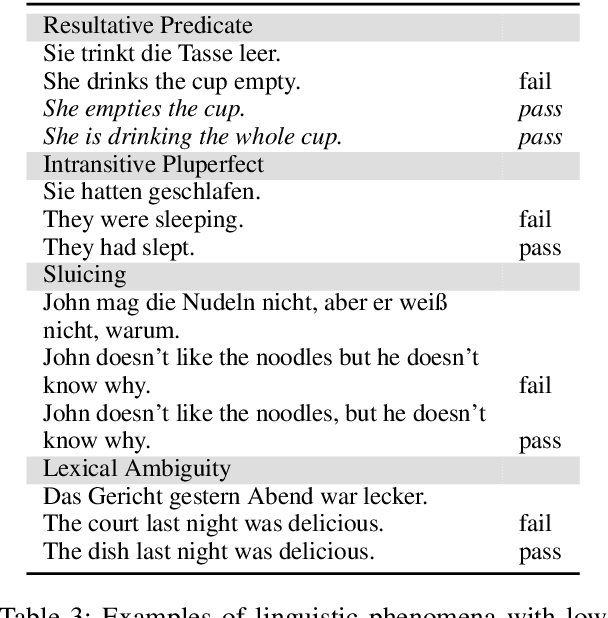
This paper describes a test suite submission providing detailed statistics of linguistic performance for the state-of-the-art German-English systems of the Fifth Conference of Machine Translation (WMT20). The analysis covers 107 phenomena organized in 14 categories based on about 5,500 test items, including a manual annotation effort of 45 person hours. Two systems (Tohoku and Huoshan) appear to have significantly better test suite accuracy than the others, although the best system of WMT20 is not significantly better than the one from WMT19 in a macro-average. Additionally, we identify some linguistic phenomena where all systems suffer (such as idioms, resultative predicates and pluperfect), but we are also able to identify particular weaknesses for individual systems (such as quotation marks, lexical ambiguity and sluicing). Most of the systems of WMT19 which submitted new versions this year show improvements.
Fine-grained evaluation of German-English Machine Translation based on a Test Suite
Oct 16, 2019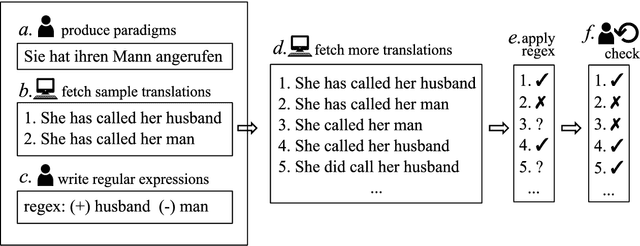
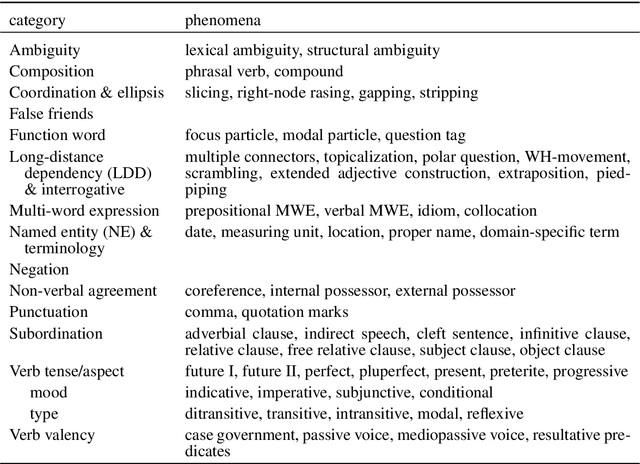
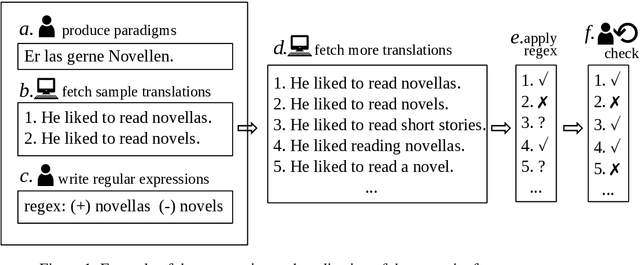
We present an analysis of 16 state-of-the-art MT systems on German-English based on a linguistically-motivated test suite. The test suite has been devised manually by a team of language professionals in order to cover a broad variety of linguistic phenomena that MT often fails to translate properly. It contains 5,000 test sentences covering 106 linguistic phenomena in 14 categories, with an increased focus on verb tenses, aspects and moods. The MT outputs are evaluated in a semi-automatic way through regular expressions that focus only on the part of the sentence that is relevant to each phenomenon. Through our analysis, we are able to compare systems based on their performance on these categories. Additionally, we reveal strengths and weaknesses of particular systems and we identify grammatical phenomena where the overall performance of MT is relatively low.