 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Collaborative, Human-Centred Taxonomy of AI, Algorithmic, and Automation Harms
Jul 01, 2024This paper introduces a collaborative, human-centered taxonomy of AI, algorithmic and automation harms. We argue that existing taxonomies, while valuable, can be narrow, unclear, typically cater to practitioners and government, and often overlook the needs of the wider public. Drawing on existing taxonomies and a large repository of documented incidents, we propose a taxonomy that is clear and understandable to a broad set of audiences, as well as being flexible, extensible, and interoperable. Through iterative refinement with topic experts and crowdsourced annotation testing, we propose a taxonomy that can serve as a powerful tool for civil society organisations, educators, policymakers, product teams and the general public. By fostering a greater understanding of the real-world harms of AI and related technologies, we aim to increase understanding, empower NGOs and individuals to identify and report violations, inform policy discussions, and encourage responsible technology development and deployment.
Pragmatic auditing: a pilot-driven approach for auditing Machine Learning systems
May 21, 2024



The growing adoption and deployment of Machine Learning (ML) systems came with its share of ethical incidents and societal concerns. It also unveiled the necessity to properly audit these systems in light of ethical principles. For such a novel type of algorithmic auditing to become standard practice, two main prerequisites need to be available: A lifecycle model that is tailored towards transparency and accountability, and a principled risk assessment procedure that allows the proper scoping of the audit. Aiming to make a pragmatic step towards a wider adoption of ML auditing, we present a respective procedure that extends the AI-HLEG guidelines published by the European Commission. Our audit procedure is based on an ML lifecycle model that explicitly focuses on documentation, accountability, and quality assurance; and serves as a common ground for alignment between the auditors and the audited organisation. We describe two pilots conducted on real-world use cases from two different organisations and discuss the shortcomings of ML algorithmic auditing as well as future directions thereof.
Flat latent manifolds for music improvisation between human and machine
Feb 23, 2022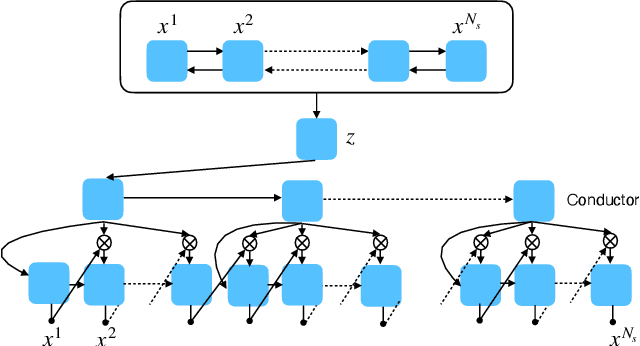
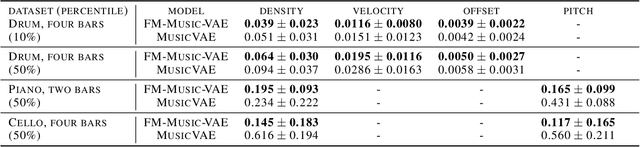
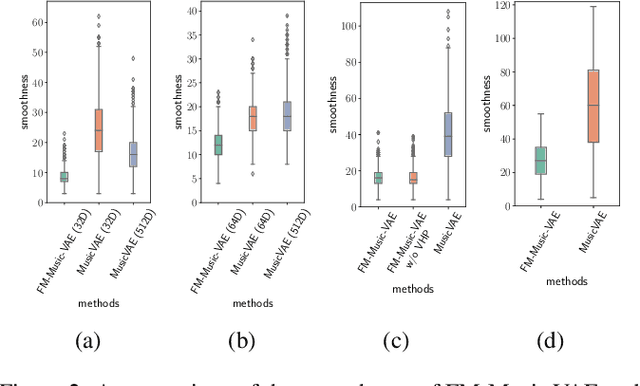
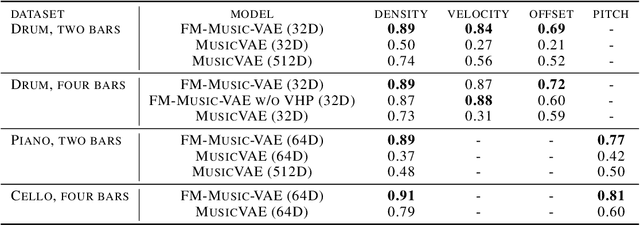
The use of machine learning in artistic music generation leads to controversial discussions of the quality of art, for which objective quantification is nonsensical. We therefore consider a music-generating algorithm as a counterpart to a human musician, in a setting where reciprocal improvisation is to lead to new experiences, both for the musician and the audience. To obtain this behaviour, we resort to the framework of recurrent Variational Auto-Encoders (VAE) and learn to generate music, seeded by a human musician. In the learned model, we generate novel musical sequences by interpolation in latent space. Standard VAEs however do not guarantee any form of smoothness in their latent representation. This translates into abrupt changes in the generated music sequences. To overcome these limitations, we regularise the decoder and endow the latent space with a flat Riemannian manifold, i.e., a manifold that is isometric to the Euclidean space. As a result, linearly interpolating in the latent space yields realistic and smooth musical changes that fit the type of machine--musician interactions we aim for. We provide empirical evidence for our method via a set of experiments on music datasets and we deploy our model for an interactive jam session with a professional drummer. The live performance provides qualitative evidence that the latent representation can be intuitively interpreted and exploited by the drummer to drive the interplay. Beyond the musical application, our approach showcases an instance of human-centred design of machine-learning models, driven by interpretability and the interaction with the end user.
Active Learning based on Data Uncertainty and Model Sensitivity
Aug 06, 2018
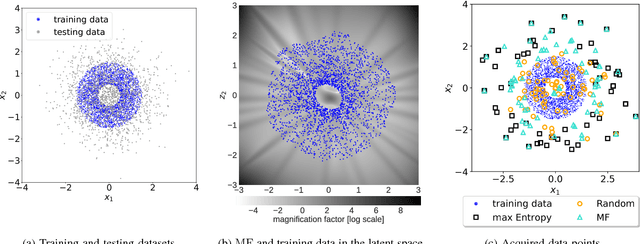
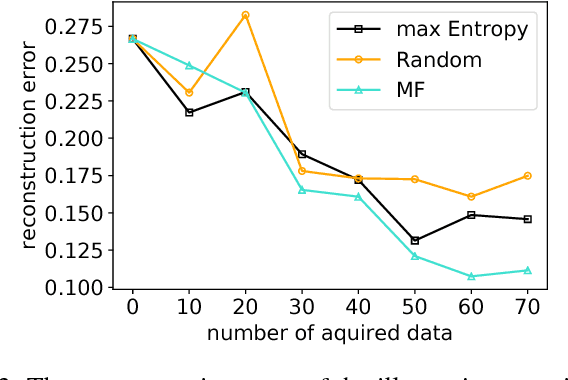
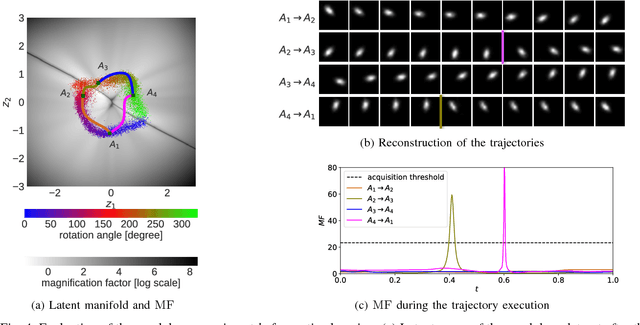
Robots can rapidly acquire new skills from demonstrations. However, during generalisation of skills or transitioning across fundamentally different skills, it is unclear whether the robot has the necessary knowledge to perform the task. Failing to detect missing information often leads to abrupt movements or to collisions with the environment. Active learning can quantify the uncertainty of performing the task and, in general, locate regions of missing information. We introduce a novel algorithm for active learning and demonstrate its utility for generating smooth trajectories. Our approach is based on deep generative models and metric learning in latent spaces. It relies on the Jacobian of the likelihood to detect non-smooth transitions in the latent space, i.e., transitions that lead to abrupt changes in the movement of the robot. When non-smooth transitions are detected, our algorithm asks for an additional demonstration from that specific region. The newly acquired knowledge modifies the data manifold and allows for learning a latent representation for generating smooth movements. We demonstrate the efficacy of our approach on generalising elementary skills, transitioning across different skills, and implicitly avoiding collisions with the environment. For our experiments, we use a simulated pendulum where we observe its motion from images and a 7-DoF anthropomorphic arm.
Unsupervised Real-Time Control through Variational Empowerment
Oct 13, 2017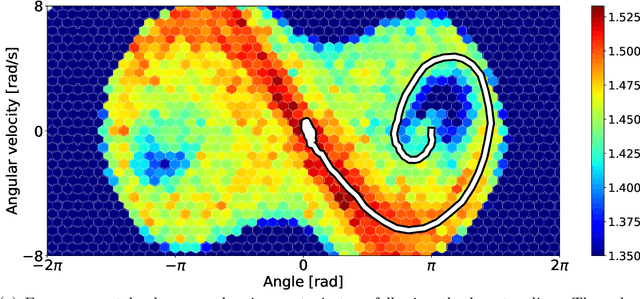
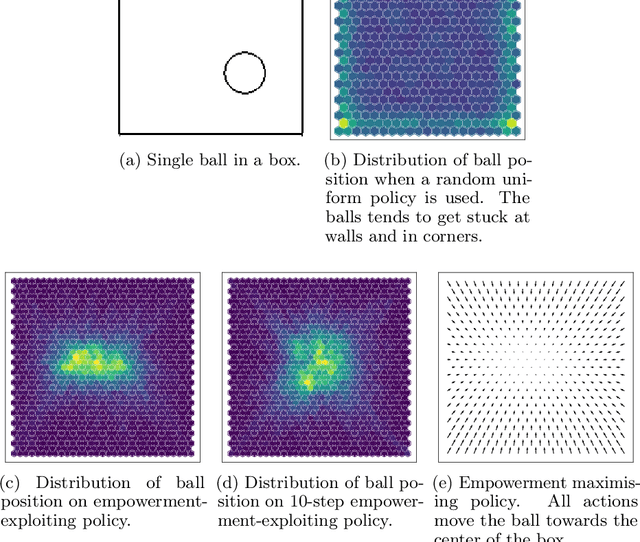
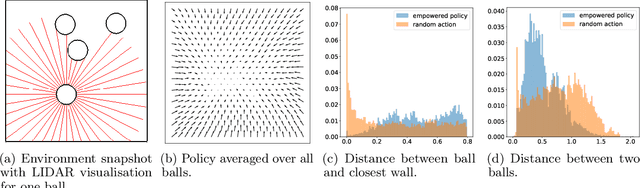
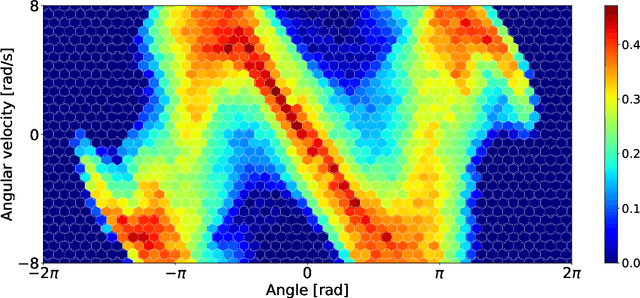
We introduce a methodology for efficiently computing a lower bound to empowerment, allowing it to be used as an unsupervised cost function for policy learning in real-time control. Empowerment, being the channel capacity between actions and states, maximises the influence of an agent on its near future. It has been shown to be a good model of biological behaviour in the absence of an extrinsic goal. But empowerment is also prohibitively hard to compute, especially in nonlinear continuous spaces. We introduce an efficient, amortised method for learning empowerment-maximising policies. We demonstrate that our algorithm can reliably handle continuous dynamical systems using system dynamics learned from raw data. The resulting policies consistently drive the agents into states where they can use their full potential.
Fast classification using sparse decision DAGs
Jun 27, 2012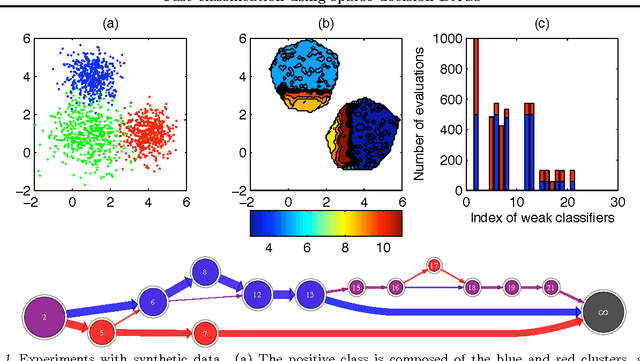
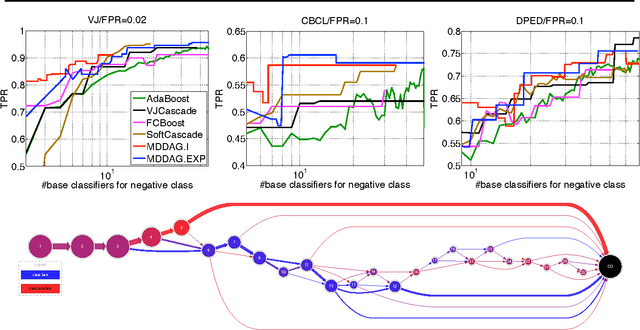
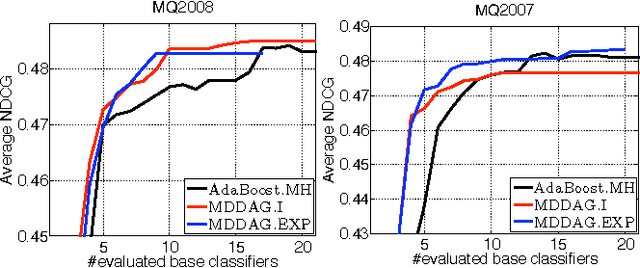
In this paper we propose an algorithm that builds sparse decision DAGs (directed acyclic graphs) from a list of base classifiers provided by an external learning method such as AdaBoost. The basic idea is to cast the DAG design task as a Markov decision process. Each instance can decide to use or to skip each base classifier, based on the current state of the classifier being built. The result is a sparse decision DAG where the base classifiers are selected in a data-dependent way. The method has a single hyperparameter with a clear semantics of controlling the accuracy/speed trade-off. The algorithm is competitive with state-of-the-art cascade detectors on three object-detection benchmarks, and it clearly outperforms them when there is a small number of base classifiers. Unlike cascades, it is also readily applicable for multi-class classification. Using the multi-class setup, we show on a benchmark web page ranking data set that we can significantly improve the decision speed without harming the performance of the ranker.