 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilter-Aware Model-Predictive Control
Apr 20, 2023Partially-observable problems pose a trade-off between reducing costs and gathering information. They can be solved optimally by planning in belief space, but that is often prohibitively expensive. Model-predictive control (MPC) takes the alternative approach of using a state estimator to form a belief over the state, and then plan in state space. This ignores potential future observations during planning and, as a result, cannot actively increase or preserve the certainty of its own state estimate. We find a middle-ground between planning in belief space and completely ignoring its dynamics by only reasoning about its future accuracy. Our approach, filter-aware MPC, penalises the loss of information by what we call "trackability", the expected error of the state estimator. We show that model-based simulation allows condensing trackability into a neural network, which allows fast planning. In experiments involving visual navigation, realistic every-day environments and a two-link robot arm, we show that filter-aware MPC vastly improves regular MPC.
PRISM: Probabilistic Real-Time Inference in Spatial World Models
Dec 06, 2022We introduce PRISM, a method for real-time filtering in a probabilistic generative model of agent motion and visual perception. Previous approaches either lack uncertainty estimates for the map and agent state, do not run in real-time, do not have a dense scene representation or do not model agent dynamics. Our solution reconciles all of these aspects. We start from a predefined state-space model which combines differentiable rendering and 6-DoF dynamics. Probabilistic inference in this model amounts to simultaneous localisation and mapping (SLAM) and is intractable. We use a series of approximations to Bayesian inference to arrive at probabilistic map and state estimates. We take advantage of well-established methods and closed-form updates, preserving accuracy and enabling real-time capability. The proposed solution runs at 10Hz real-time and is similarly accurate to state-of-the-art SLAM in small to medium-sized indoor environments, with high-speed UAV and handheld camera agents (Blackbird, EuRoC and TUM-RGBD).
Tracking and Planning with Spatial World Models
Jan 25, 2022

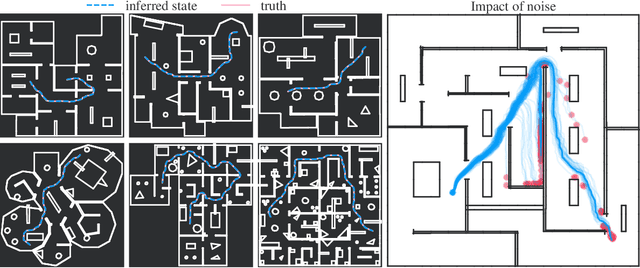

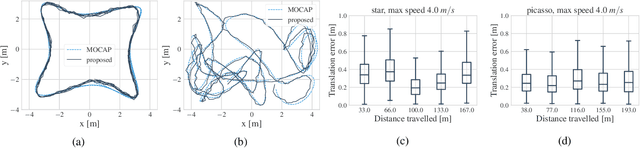
We introduce a method for real-time navigation and tracking with differentiably rendered world models. Learning models for control has led to impressive results in robotics and computer games, but this success has yet to be extended to vision-based navigation. To address this, we transfer advances in the emergent field of differentiable rendering to model-based control. We do this by planning in a learned 3D spatial world model, combined with a pose estimation algorithm previously used in the context of TSDF fusion, but now tailored to our setting and improved to incorporate agent dynamics. We evaluate over six simulated environments based on complex human-designed floor plans and provide quantitative results. We achieve up to 92% navigation success rate at a frequency of 15 Hz using only image and depth observations under stochastic, continuous dynamics.
Mind the Gap when Conditioning Amortised Inference in Sequential Latent-Variable Models
Jan 18, 2021


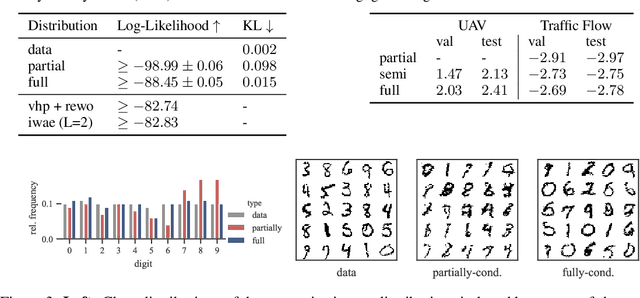
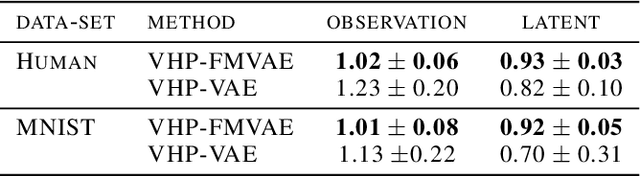
Amortised inference enables scalable learning of sequential latent-variable models (LVMs) with the evidence lower bound (ELBO). In this setting, variational posteriors are often only partially conditioned. While the true posteriors depend, e.g., on the entire sequence of observations, approximate posteriors are only informed by past observations. This mimics the Bayesian filter -- a mixture of smoothing posteriors. Yet, we show that the ELBO objective forces partially-conditioned amortised posteriors to approximate products of smoothing posteriors instead. Consequently, the learned generative model is compromised. We demonstrate these theoretical findings in three scenarios: traffic flow, handwritten digits, and aerial vehicle dynamics. Using fully-conditioned approximate posteriors, performance improves in terms of generative modelling and multi-step prediction.
Variational State-Space Models for Localisation and Dense 3D Mapping in 6 DoF
Jun 17, 2020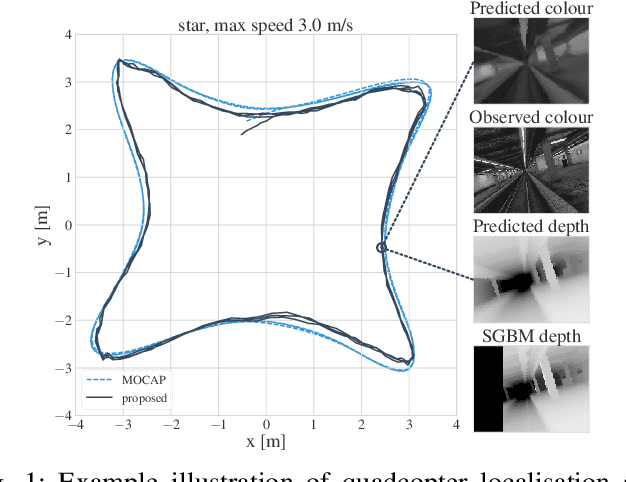
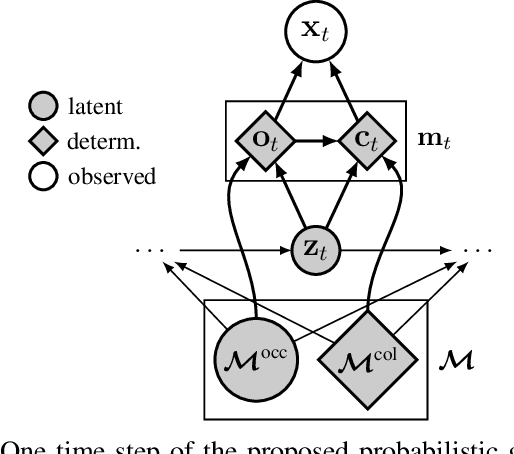
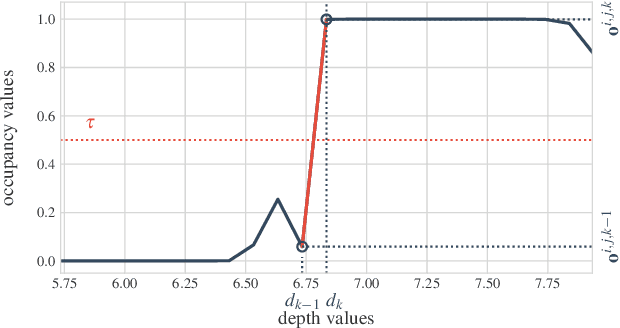
We solve the problem of 6-DoF localisation and 3D dense reconstruction in spatial environments as approximate Bayesian inference in a deep generative approach which combines learned with engineered models. This principled treatment of uncertainty and probabilistic inference overcomes the shortcoming of current state-of-the-art solutions to rely on heavily engineered, heterogeneous pipelines. Variational inference enables us to use neural networks for system identification, while a differentiable raycaster is used for the emission model. This ensures that our model is amenable to end-to-end gradient-based optimisation. We evaluate our approach on realistic unmanned aerial vehicle flight data, nearing the performance of a state-of-the-art visual inertial odometry system. The applicability of the learned model to downstream tasks such as generative prediction and planning is investigated.
Learning Flat Latent Manifolds with VAEs
Feb 12, 2020
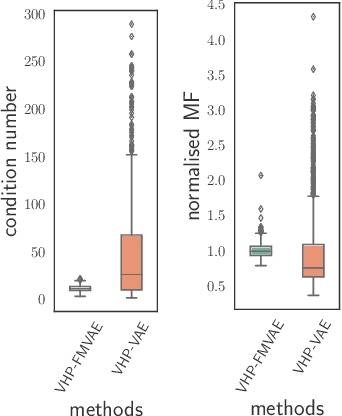
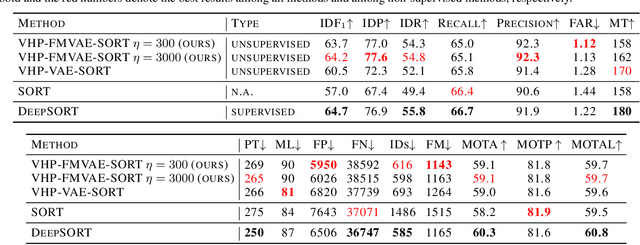
Measuring the similarity between data points often requires domain knowledge. This can in parts be compensated by relying on unsupervised methods such as latent-variable models, where similarity/distance is estimated in a more compact latent space. Prevalent is the use of the Euclidean metric, which has the drawback of ignoring information about similarity of data stored in the decoder, as captured by the framework of Riemannian geometry. Alternatives---such as approximating the geodesic---are often computationally inefficient, rendering the methods impractical. We propose an extension to the framework of variational auto-encoders allows learning flat latent manifolds, where the Euclidean metric is a proxy for the similarity between data points. This is achieved by defining the latent space as a Riemannian manifold and by regularising the metric tensor to be a scaled identity matrix. Additionally, we replace the compact prior typically used in variational auto-encoders with a recently presented, more expressive hierarchical one---and formulate the learning problem as a constrained optimisation problem. We evaluate our method on a range of data-sets, including a video-tracking benchmark, where the performance of our unsupervised approach nears that of state-of-the-art supervised approaches, while retaining the computational efficiency of straight-line-based approaches.
Variational Tracking and Prediction with Generative Disentangled State-Space Models
Oct 14, 2019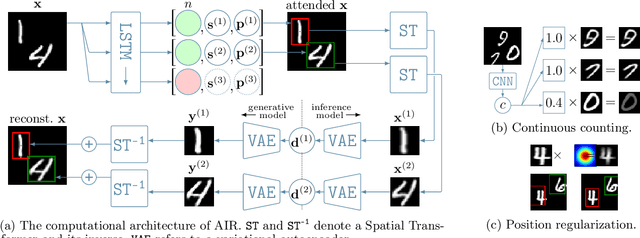
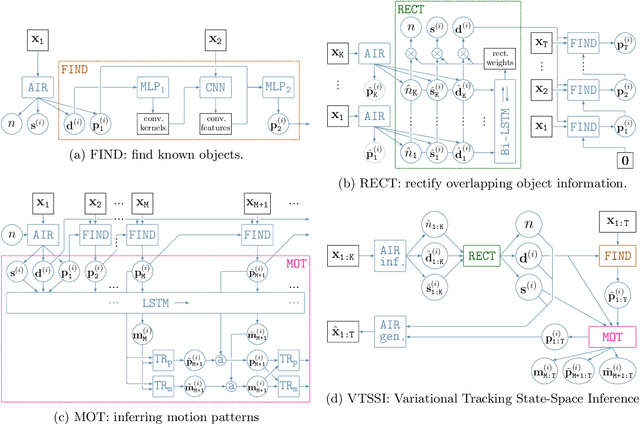


We address tracking and prediction of multiple moving objects in visual data streams as inference and sampling in a disentangled latent state-space model. By encoding objects separately and including explicit position information in the latent state space, we perform tracking via amortized variational Bayesian inference of the respective latent positions. Inference is implemented in a modular neural framework tailored towards our disentangled latent space. Generative and inference model are jointly learned from observations only. Comparing to related prior work, we empirically show that our Markovian state-space assumption enables faithful and much improved long-term prediction well beyond the training horizon. Further, our inference model correctly decomposes frames into objects, even in the presence of occlusions. Tracking performance is increased significantly over prior art.
Increasing the Generalisation Capacity of Conditional VAEs
Sep 10, 2019
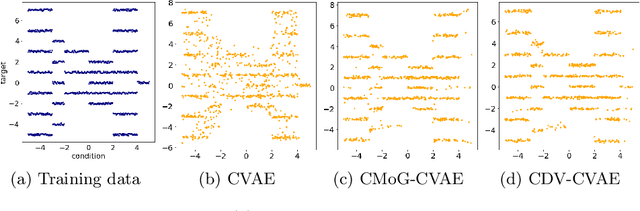


We address the problem of one-to-many mappings in supervised learning, where a single instance has many different solutions of possibly equal cost. The framework of conditional variational autoencoders describes a class of methods to tackle such structured-prediction tasks by means of latent variables. We propose to incentivise informative latent representations for increasing the generalisation capacity of conditional variational autoencoders. To this end, we modify the latent variable model by defining the likelihood as a function of the latent variable only and introduce an expressive multimodal prior to enable the model for capturing semantically meaningful features of the data. To validate our approach, we train our model on the Cornell Robot Grasping dataset, and modified versions of MNIST and Fashion-MNIST obtaining results that show a significantly higher generalisation capability.
On Deep Set Learning and the Choice of Aggregations
Mar 18, 2019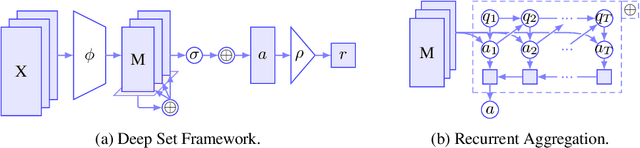



Recently, it has been shown that many functions on sets can be represented by sum decompositions. These decompositons easily lend themselves to neural approximations, extending the applicability of neural nets to set-valued inputs---Deep Set learning. This work investigates a core component of Deep Set architecture: aggregation functions. We suggest and examine alternatives to commonly used aggregation functions, including learnable recurrent aggregation functions. Empirically, we show that the Deep Set networks are highly sensitive to the choice of aggregation functions: beyond improved performance, we find that learnable aggregations lower hyper-parameter sensitivity and generalize better to out-of-distribution input size.
Bayesian Learning of Neural Network Architectures
Jan 27, 2019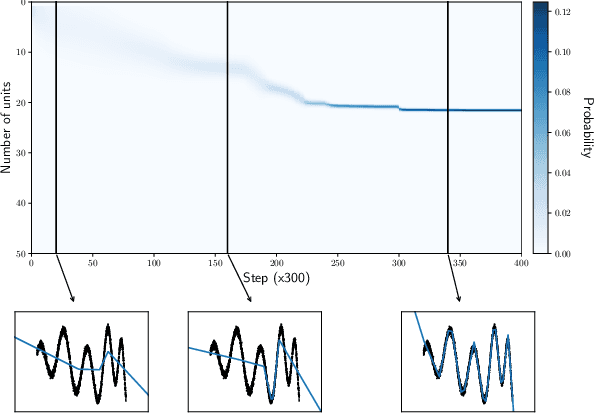
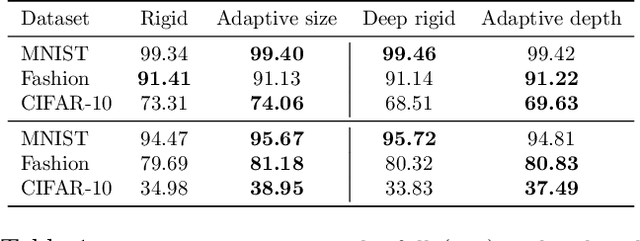
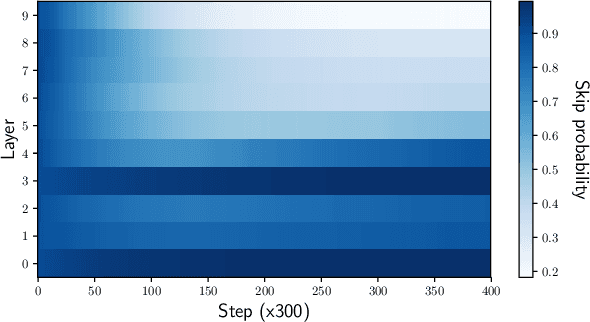
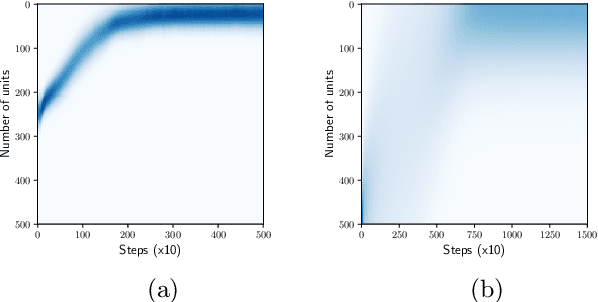
In this paper we propose a Bayesian method for estimating architectural parameters of neural networks, namely layer size and network depth. We do this by learning concrete distributions over these parameters. Our results show that regular networks with a learnt structure can generalise better on small datasets, while fully stochastic networks can be more robust to parameter initialisation. The proposed method relies on standard neural variational learning and, unlike randomised architecture search, does not require a retraining of the model, thus keeping the computational overhead at minimum.