 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Tracking and Prediction with Generative Disentangled State-Space Models
Oct 14, 2019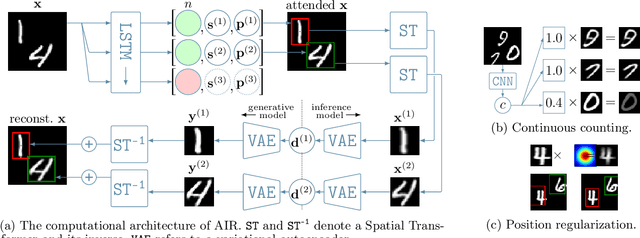


We address tracking and prediction of multiple moving objects in visual data streams as inference and sampling in a disentangled latent state-space model. By encoding objects separately and including explicit position information in the latent state space, we perform tracking via amortized variational Bayesian inference of the respective latent positions. Inference is implemented in a modular neural framework tailored towards our disentangled latent space. Generative and inference model are jointly learned from observations only. Comparing to related prior work, we empirically show that our Markovian state-space assumption enables faithful and much improved long-term prediction well beyond the training horizon. Further, our inference model correctly decomposes frames into objects, even in the presence of occlusions. Tracking performance is increased significantly over prior art.
On Deep Set Learning and the Choice of Aggregations
Mar 18, 2019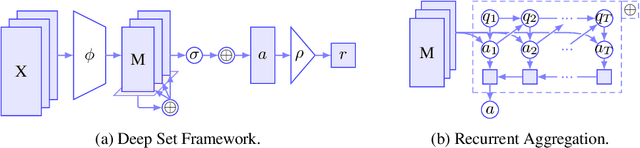



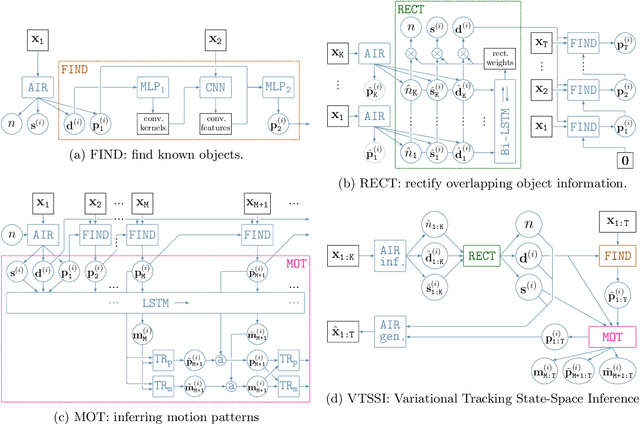
Recently, it has been shown that many functions on sets can be represented by sum decompositions. These decompositons easily lend themselves to neural approximations, extending the applicability of neural nets to set-valued inputs---Deep Set learning. This work investigates a core component of Deep Set architecture: aggregation functions. We suggest and examine alternatives to commonly used aggregation functions, including learnable recurrent aggregation functions. Empirically, we show that the Deep Set networks are highly sensitive to the choice of aggregation functions: beyond improved performance, we find that learnable aggregations lower hyper-parameter sensitivity and generalize better to out-of-distribution input size.
Sequence Labeling: A Practical Approach
Aug 12, 2018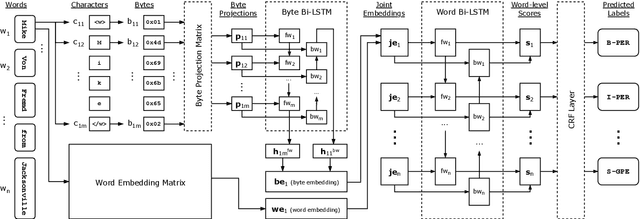
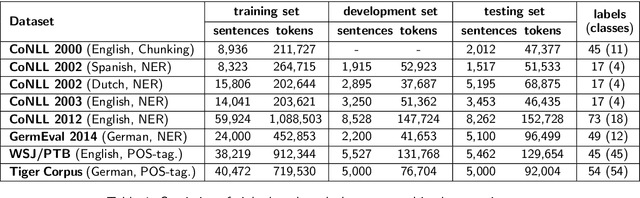
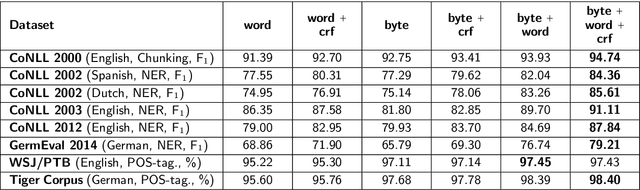
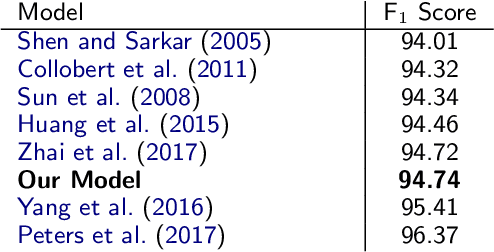
We take a practical approach to solving sequence labeling problem assuming unavailability of domain expertise and scarcity of informational and computational resources. To this end, we utilize a universal end-to-end Bi-LSTM-based neural sequence labeling model applicable to a wide range of NLP tasks and languages. The model combines morphological, semantic, and structural cues extracted from data to arrive at informed predictions. The model's performance is evaluated on eight benchmark datasets (covering three tasks: POS-tagging, NER, and Chunking, and four languages: English, German, Dutch, and Spanish). We observe state-of-the-art results on four of them: CoNLL-2012 (English NER), CoNLL-2002 (Dutch NER), GermEval 2014 (German NER), Tiger Corpus (German POS-tagging), and competitive performance on the rest.