 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Tracking and Prediction with Generative Disentangled State-Space Models
Paper and Code
Oct 14, 2019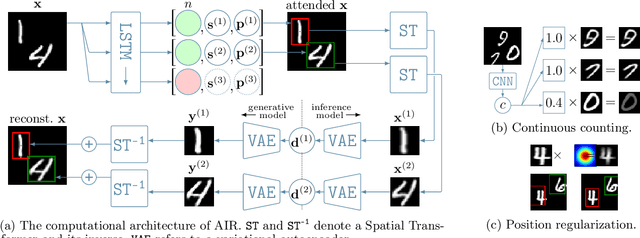
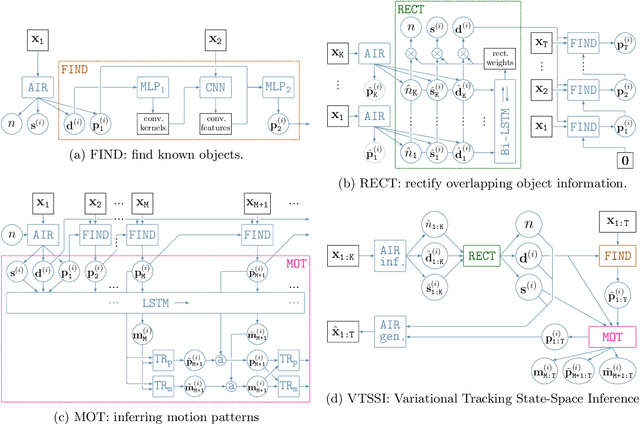


We address tracking and prediction of multiple moving objects in visual data streams as inference and sampling in a disentangled latent state-space model. By encoding objects separately and including explicit position information in the latent state space, we perform tracking via amortized variational Bayesian inference of the respective latent positions. Inference is implemented in a modular neural framework tailored towards our disentangled latent space. Generative and inference model are jointly learned from observations only. Comparing to related prior work, we empirically show that our Markovian state-space assumption enables faithful and much improved long-term prediction well beyond the training horizon. Further, our inference model correctly decomposes frames into objects, even in the presence of occlusions. Tracking performance is increased significantly over prior art.