 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap when Conditioning Amortised Inference in Sequential Latent-Variable Models
Jan 18, 2021


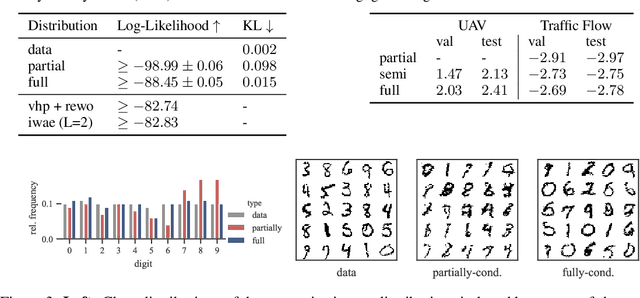
Amortised inference enables scalable learning of sequential latent-variable models (LVMs) with the evidence lower bound (ELBO). In this setting, variational posteriors are often only partially conditioned. While the true posteriors depend, e.g., on the entire sequence of observations, approximate posteriors are only informed by past observations. This mimics the Bayesian filter -- a mixture of smoothing posteriors. Yet, we show that the ELBO objective forces partially-conditioned amortised posteriors to approximate products of smoothing posteriors instead. Consequently, the learned generative model is compromised. We demonstrate these theoretical findings in three scenarios: traffic flow, handwritten digits, and aerial vehicle dynamics. Using fully-conditioned approximate posteriors, performance improves in terms of generative modelling and multi-step prediction.
Variational Tracking and Prediction with Generative Disentangled State-Space Models
Oct 14, 2019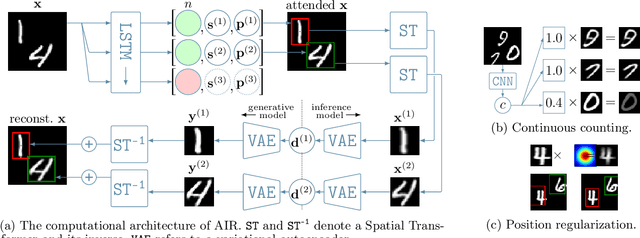
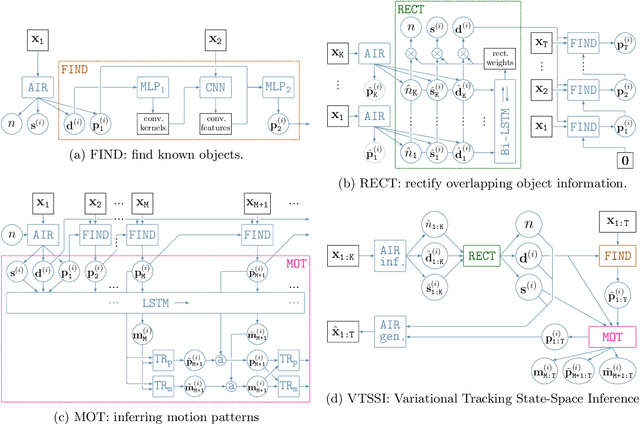


We address tracking and prediction of multiple moving objects in visual data streams as inference and sampling in a disentangled latent state-space model. By encoding objects separately and including explicit position information in the latent state space, we perform tracking via amortized variational Bayesian inference of the respective latent positions. Inference is implemented in a modular neural framework tailored towards our disentangled latent space. Generative and inference model are jointly learned from observations only. Comparing to related prior work, we empirically show that our Markovian state-space assumption enables faithful and much improved long-term prediction well beyond the training horizon. Further, our inference model correctly decomposes frames into objects, even in the presence of occlusions. Tracking performance is increased significantly over prior art.
On Deep Set Learning and the Choice of Aggregations
Mar 18, 2019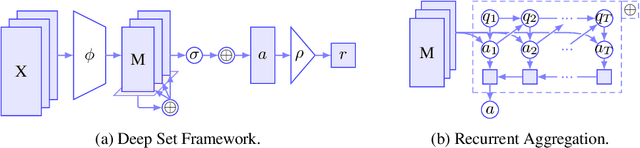



Recently, it has been shown that many functions on sets can be represented by sum decompositions. These decompositons easily lend themselves to neural approximations, extending the applicability of neural nets to set-valued inputs---Deep Set learning. This work investigates a core component of Deep Set architecture: aggregation functions. We suggest and examine alternatives to commonly used aggregation functions, including learnable recurrent aggregation functions. Empirically, we show that the Deep Set networks are highly sensitive to the choice of aggregation functions: beyond improved performance, we find that learnable aggregations lower hyper-parameter sensitivity and generalize better to out-of-distribution input size.
Unsupervised Real-Time Control through Variational Empowerment
Oct 13, 2017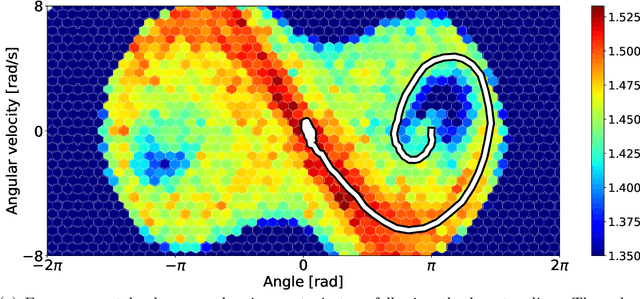
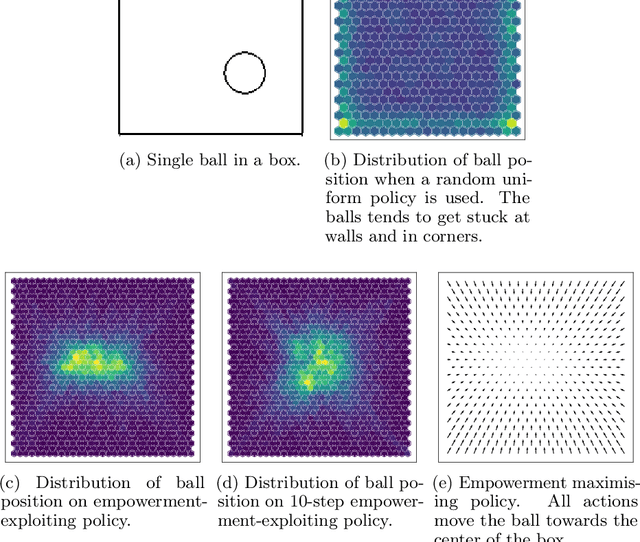
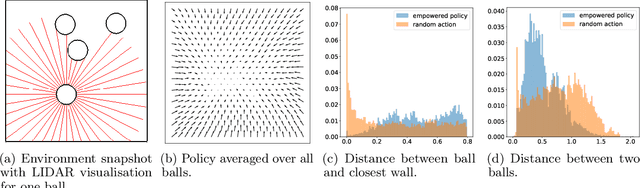
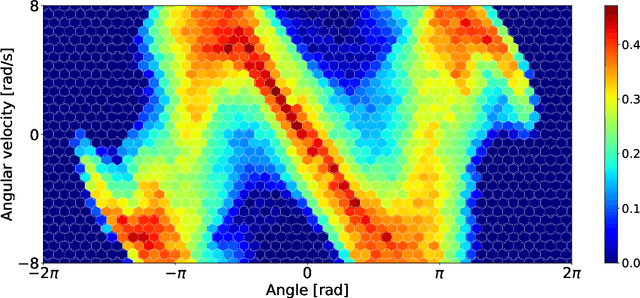
We introduce a methodology for efficiently computing a lower bound to empowerment, allowing it to be used as an unsupervised cost function for policy learning in real-time control. Empowerment, being the channel capacity between actions and states, maximises the influence of an agent on its near future. It has been shown to be a good model of biological behaviour in the absence of an extrinsic goal. But empowerment is also prohibitively hard to compute, especially in nonlinear continuous spaces. We introduce an efficient, amortised method for learning empowerment-maximising policies. We demonstrate that our algorithm can reliably handle continuous dynamical systems using system dynamics learned from raw data. The resulting policies consistently drive the agents into states where they can use their full potential.
Deep Variational Bayes Filters: Unsupervised Learning of State Space Models from Raw Data
Mar 03, 2017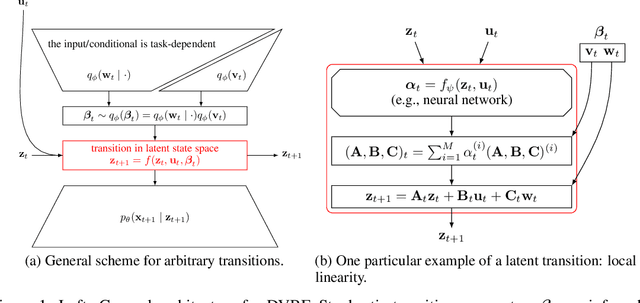
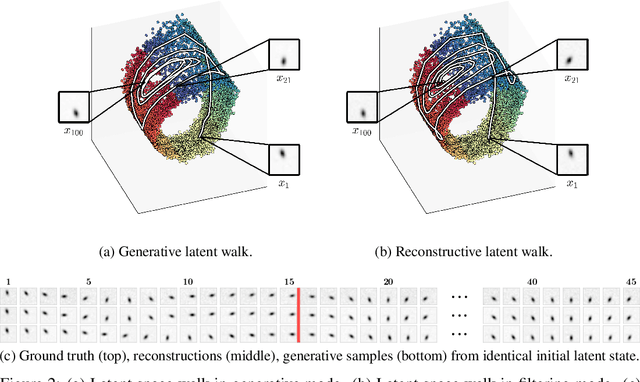
We introduce Deep Variational Bayes Filters (DVBF), a new method for unsupervised learning and identification of latent Markovian state space models. Leveraging recent advances in Stochastic Gradient Variational Bayes, DVBF can overcome intractable inference distributions via variational inference. Thus, it can handle highly nonlinear input data with temporal and spatial dependencies such as image sequences without domain knowledge. Our experiments show that enabling backpropagation through transitions enforces state space assumptions and significantly improves information content of the latent embedding. This also enables realistic long-term prediction.
Variational Inference for On-line Anomaly Detection in High-Dimensional Time Series
Jun 14, 2016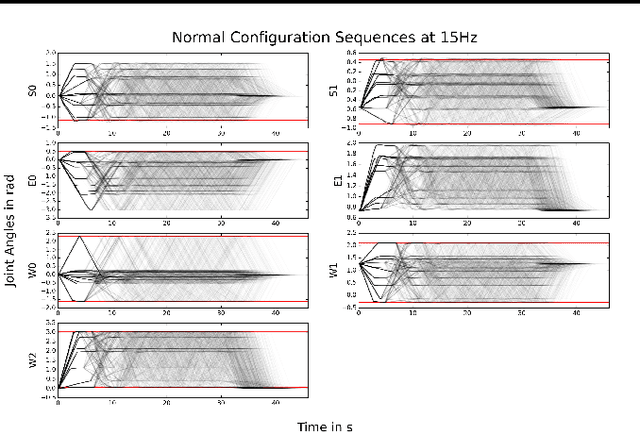



Approximate variational inference has shown to be a powerful tool for modeling unknown complex probability distributions. Recent advances in the field allow us to learn probabilistic models of sequences that actively exploit spatial and temporal structure. We apply a Stochastic Recurrent Network (STORN) to learn robot time series data. Our evaluation demonstrates that we can robustly detect anomalies both off- and on-line.