 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Latent Action Policies for Model-Based Offline Reinforcement Learning
Nov 07, 2024


In offline reinforcement learning, a policy is learned using a static dataset in the absence of costly feedback from the environment. In contrast to the online setting, only using static datasets poses additional challenges, such as policies generating out-of-distribution samples. Model-based offline reinforcement learning methods try to overcome these by learning a model of the underlying dynamics of the environment and using it to guide policy search. It is beneficial but, with limited datasets, errors in the model and the issue of value overestimation among out-of-distribution states can worsen performance. Current model-based methods apply some notion of conservatism to the Bellman update, often implemented using uncertainty estimation derived from model ensembles. In this paper, we propose Constrained Latent Action Policies (C-LAP) which learns a generative model of the joint distribution of observations and actions. We cast policy learning as a constrained objective to always stay within the support of the latent action distribution, and use the generative capabilities of the model to impose an implicit constraint on the generated actions. Thereby eliminating the need to use additional uncertainty penalties on the Bellman update and significantly decreasing the number of gradient steps required to learn a policy. We empirically evaluate C-LAP on the D4RL and V-D4RL benchmark, and show that C-LAP is competitive to state-of-the-art methods, especially outperforming on datasets with visual observations.
LIMT: Language-Informed Multi-Task Visual World Models
Jul 18, 2024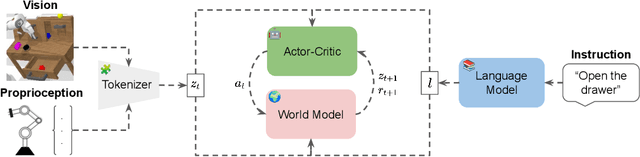
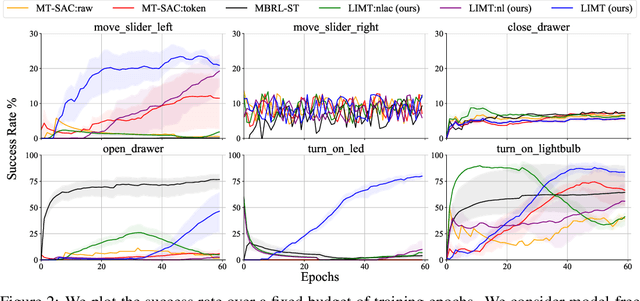
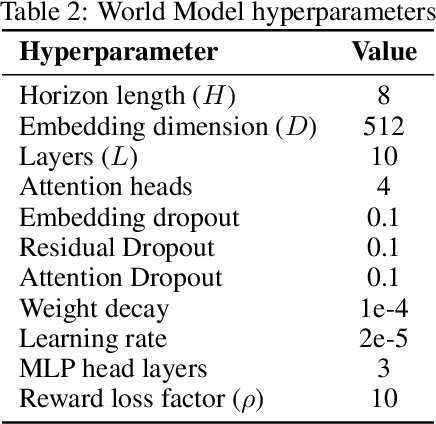
Most recent successes in robot reinforcement learning involve learning a specialized single-task agent. However, robots capable of performing multiple tasks can be much more valuable in real-world applications. Multi-task reinforcement learning can be very challenging due to the increased sample complexity and the potentially conflicting task objectives. Previous work on this topic is dominated by model-free approaches. The latter can be very sample inefficient even when learning specialized single-task agents. In this work, we focus on model-based multi-task reinforcement learning. We propose a method for learning multi-task visual world models, leveraging pre-trained language models to extract semantically meaningful task representations. These representations are used by the world model and policy to reason about task similarity in dynamics and behavior. Our results highlight the benefits of using language-driven task representations for world models and a clear advantage of model-based multi-task learning over the more common model-free paradigm.
Overcoming Knowledge Barriers: Online Imitation Learning from Observation with Pretrained World Models
Apr 29, 2024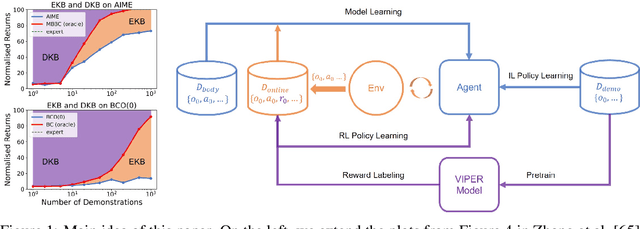
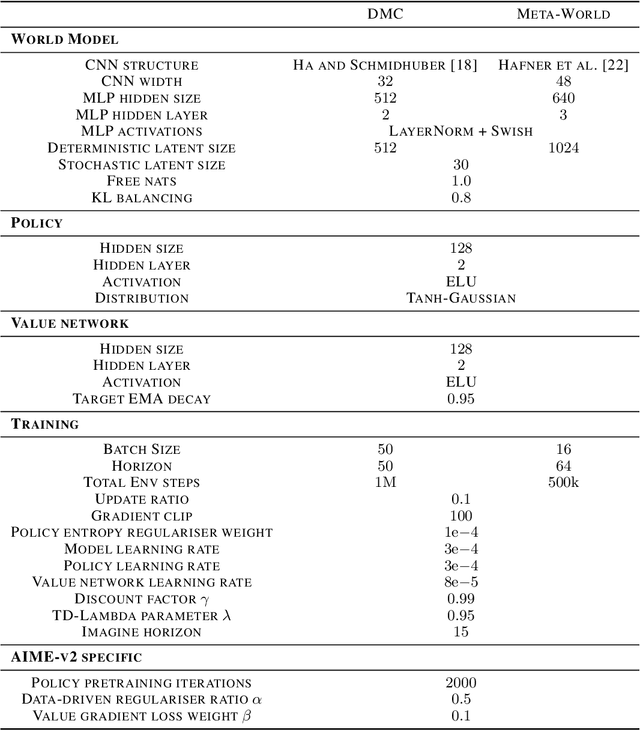
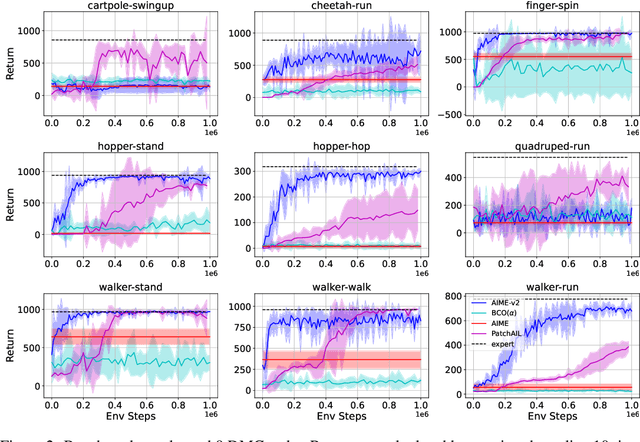
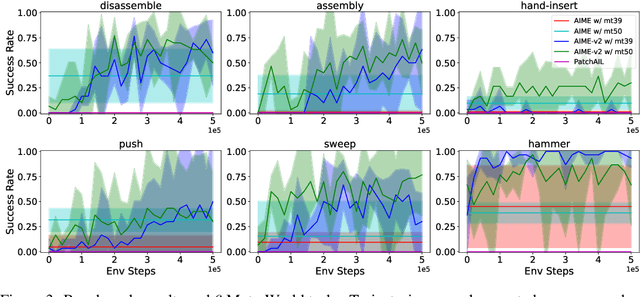
Incorporating the successful paradigm of pretraining and finetuning from Computer Vision and Natural Language Processing into decision-making has become increasingly popular in recent years. In this paper, we study Imitation Learning from Observation with pretrained models and find existing approaches such as BCO and AIME face knowledge barriers, specifically the Embodiment Knowledge Barrier (EKB) and the Demonstration Knowledge Barrier (DKB), greatly limiting their performance. The EKB arises when pretrained models lack knowledge about unseen observations, leading to errors in action inference. The DKB results from policies trained on limited demonstrations, hindering adaptability to diverse scenarios. We thoroughly analyse the underlying mechanism of these barriers and propose AIME-v2 upon AIME as a solution. AIME-v2 uses online interactions with data-driven regulariser to alleviate the EKB and mitigates the DKB by introducing a surrogate reward function to enhance policy training. Experimental results on tasks from the DeepMind Control Suite and Meta-World benchmarks demonstrate the effectiveness of these modifications in improving both sample-efficiency and converged performance. The study contributes valuable insights into resolving knowledge barriers for enhanced decision-making in pretraining-based approaches. Code will be available at https://github.com/argmax-ai/aime-v2.
On the Role of the Action Space in Robot Manipulation Learning and Sim-to-Real Transfer
Dec 06, 2023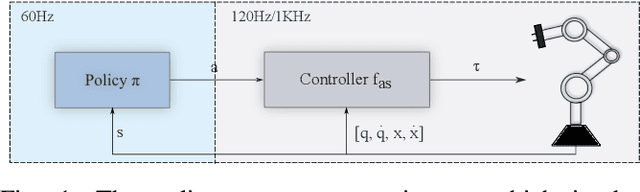

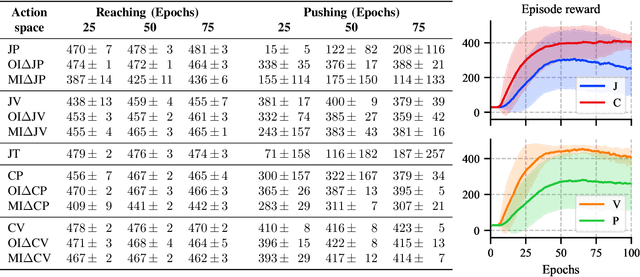
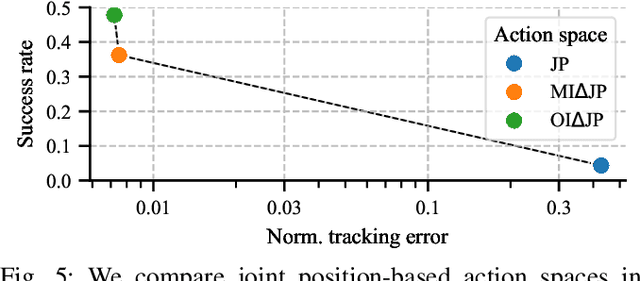
We study the choice of action space in robot manipulation learning and sim-to-real transfer. We define metrics that assess the performance, and examine the emerging properties in the different action spaces. We train over 250 reinforcement learning~(RL) agents in simulated reaching and pushing tasks, using 13 different control spaces. The choice of action spaces spans popular choices in the literature as well as novel combinations of common design characteristics. We evaluate the training performance in simulation and the transfer to a real-world environment. We identify good and bad characteristics of robotic action spaces and make recommendations for future designs. Our findings have important implications for the design of RL algorithms for robot manipulation tasks, and highlight the need for careful consideration of action spaces when training and transferring RL agents for real-world robotics.
Action Inference by Maximising Evidence: Zero-Shot Imitation from Observation with World Models
Dec 04, 2023Unlike most reinforcement learning agents which require an unrealistic amount of environment interactions to learn a new behaviour, humans excel at learning quickly by merely observing and imitating others. This ability highly depends on the fact that humans have a model of their own embodiment that allows them to infer the most likely actions that led to the observed behaviour. In this paper, we propose Action Inference by Maximising Evidence (AIME) to replicate this behaviour using world models. AIME consists of two distinct phases. In the first phase, the agent learns a world model from its past experience to understand its own body by maximising the ELBO. While in the second phase, the agent is given some observation-only demonstrations of an expert performing a novel task and tries to imitate the expert's behaviour. AIME achieves this by defining a policy as an inference model and maximising the evidence of the demonstration under the policy and world model. Our method is "zero-shot" in the sense that it does not require further training for the world model or online interactions with the environment after given the demonstration. We empirically validate the zero-shot imitation performance of our method on the Walker and Cheetah embodiment of the DeepMind Control Suite and find it outperforms the state-of-the-art baselines. Code is available at: https://github.com/argmax-ai/aime.
CLAS: Coordinating Multi-Robot Manipulation with Central Latent Action Spaces
Nov 28, 2022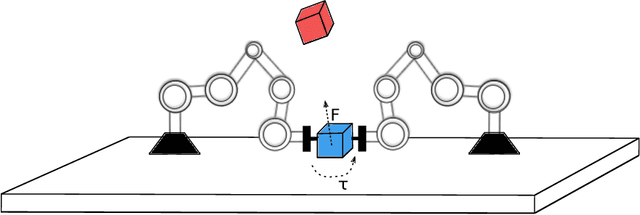
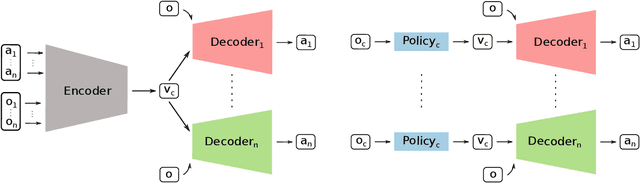
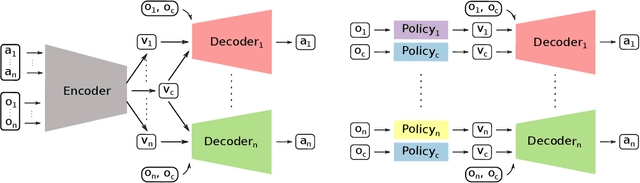

Multi-robot manipulation tasks involve various control entities that can be separated into dynamically independent parts. A typical example of such real-world tasks is dual-arm manipulation. Learning to naively solve such tasks with reinforcement learning is often unfeasible due to the sample complexity and exploration requirements growing with the dimensionality of the action and state spaces. Instead, we would like to handle such environments as multi-agent systems and have several agents control parts of the whole. However, decentralizing the generation of actions requires coordination across agents through a channel limited to information central to the task. This paper proposes an approach to coordinating multi-robot manipulation through learned latent action spaces that are shared across different agents. We validate our method in simulated multi-robot manipulation tasks and demonstrate improvement over previous baselines in terms of sample efficiency and learning performance.
Learning to Fly via Deep Model-Based Reinforcement Learning
Mar 19, 2020
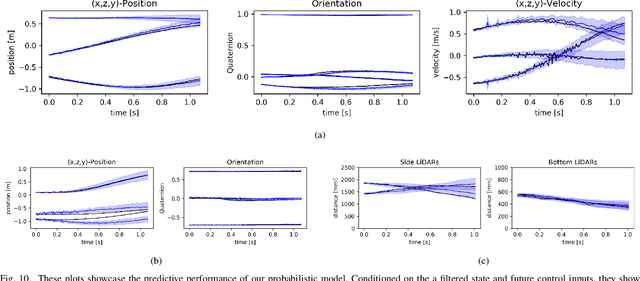

Learning to control robots without requiring models has been a long-term goal, promising diverse and novel applications. Yet, reinforcement learning has only achieved limited impact on real-time robot control due to its high demand of real-world interactions. In this work, by leveraging a learnt probabilistic model of drone dynamics, we achieve human-like quadrotor control through model-based reinforcement learning. No prior knowledge of the flight dynamics is assumed; instead, a sequential latent variable model, used generatively and as an online filter, is learnt from raw sensory input. The controller and value function are optimised entirely by propagating stochastic analytic gradients through generated latent trajectories. We show that "learning to fly" can be achieved with less than 30 minutes of experience with a single drone, and can be deployed solely using onboard computational resources and sensors, on a self-built drone.
Beta DVBF: Learning State-Space Models for Control from High Dimensional Observations
Nov 02, 2019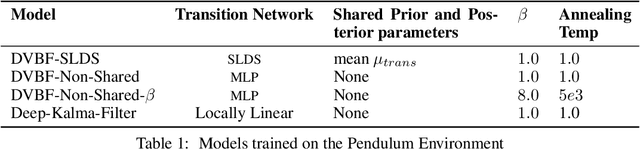
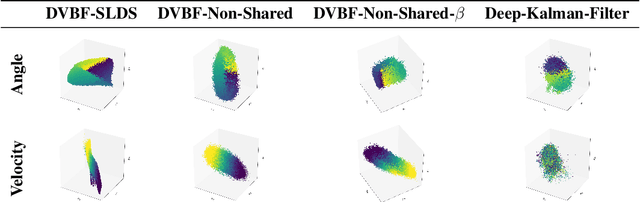
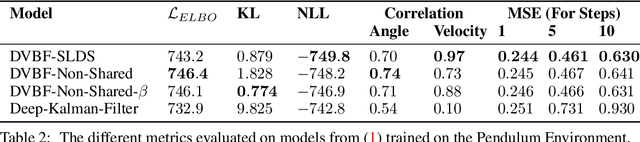
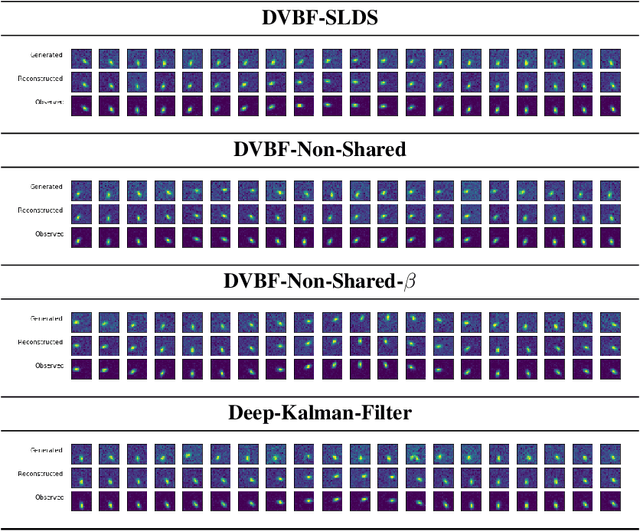
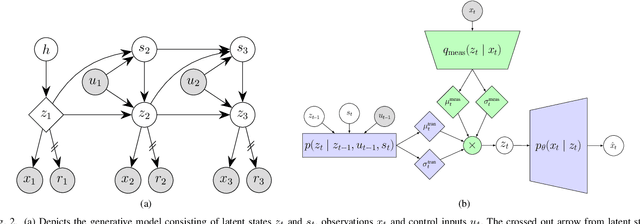
Learning a model of dynamics from high-dimensional images can be a core ingredient for success in many applications across different domains, especially in sequential decision making. However, currently prevailing methods based on latent-variable models are limited to working with low resolution images only. In this work, we show that some of the issues with using high-dimensional observations arise from the discrepancy between the dimensionality of the latent and observable space, and propose solutions to overcome them.
Unsupervised Real-Time Control through Variational Empowerment
Oct 13, 2017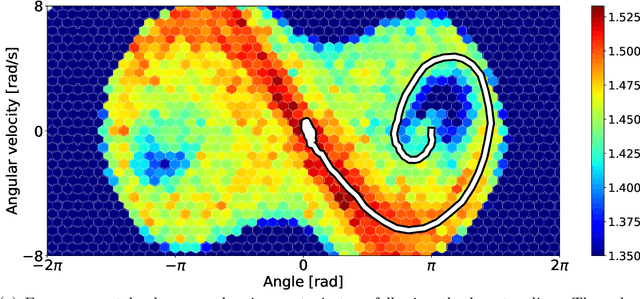
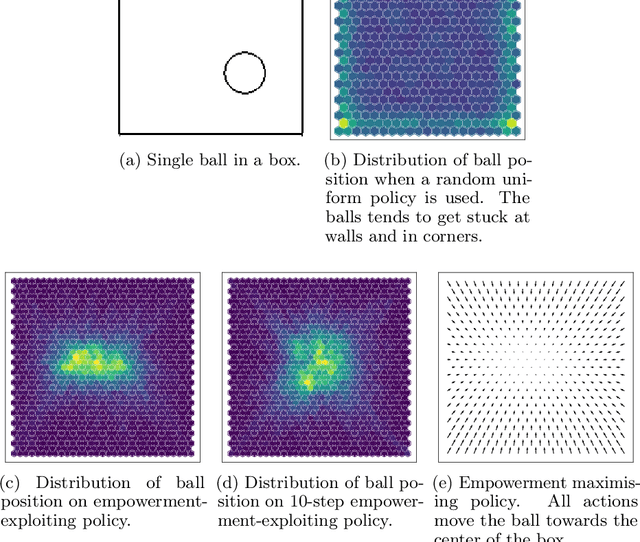
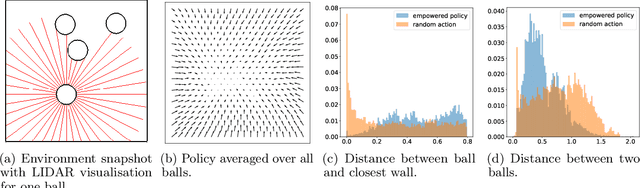
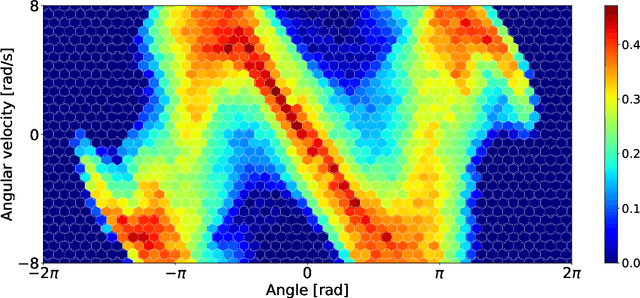
We introduce a methodology for efficiently computing a lower bound to empowerment, allowing it to be used as an unsupervised cost function for policy learning in real-time control. Empowerment, being the channel capacity between actions and states, maximises the influence of an agent on its near future. It has been shown to be a good model of biological behaviour in the absence of an extrinsic goal. But empowerment is also prohibitively hard to compute, especially in nonlinear continuous spaces. We introduce an efficient, amortised method for learning empowerment-maximising policies. We demonstrate that our algorithm can reliably handle continuous dynamical systems using system dynamics learned from raw data. The resulting policies consistently drive the agents into states where they can use their full potential.
Deep Variational Bayes Filters: Unsupervised Learning of State Space Models from Raw Data
Mar 03, 2017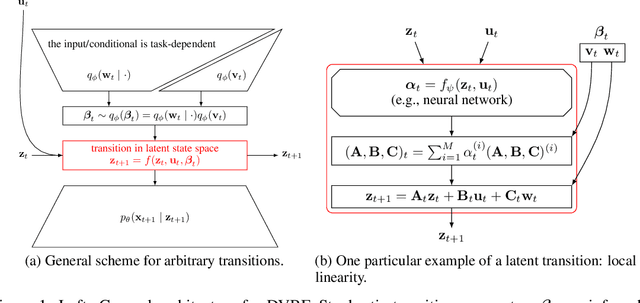
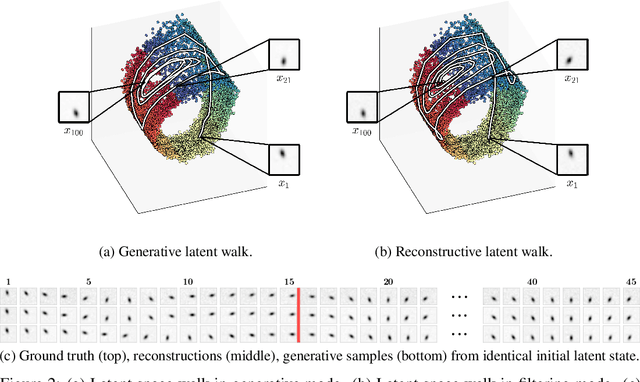
We introduce Deep Variational Bayes Filters (DVBF), a new method for unsupervised learning and identification of latent Markovian state space models. Leveraging recent advances in Stochastic Gradient Variational Bayes, DVBF can overcome intractable inference distributions via variational inference. Thus, it can handle highly nonlinear input data with temporal and spatial dependencies such as image sequences without domain knowledge. Our experiments show that enabling backpropagation through transitions enforces state space assumptions and significantly improves information content of the latent embedding. This also enables realistic long-term prediction.