 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Imitation Learning for Event-based Quadrotor Flight in Cluttered Environments
Mar 08, 2026Event cameras offer high temporal resolution and low latency, making them ideal sensors for high-speed robotic applications where conventional cameras suffer from image degradations such as motion blur. In addition, their low power consumption can enhance endurance, which is critical for resource-constrained platforms. Motivated by these properties, we present a novel approach that enables a quadrotor to fly through cluttered environments at high speed by perceiving the environment with a single event camera. Our proposed method employs an end-to-end neural network trained to map event data directly to control commands, eliminating the reliance on standard cameras. To enable efficient training in simulation, where rendering synthetic event data is computationally expensive, we propose Approximate Imitation Learning, a novel imitation learning framework. Our approach leverages a large-scale offline dataset to learn a task-specific representation space. Subsequently, the policy is trained through online interactions that rely solely on lightweight, simulated state information, eliminating the need to render events during training. This enables the efficient training of event-based control policies for fast quadrotor flight, highlighting the potential of our framework for other modalities where data simulation is costly or impractical. Our approach outperforms standard imitation learning baselines in simulation and demonstrates robust performance in real-world flight tests, achieving speeds up to 9.8 ms-1 in cluttered environments.
The Reality Gap in Robotics: Challenges, Solutions, and Best Practices
Oct 23, 2025Machine learning has facilitated significant advancements across various robotics domains, including navigation, locomotion, and manipulation. Many such achievements have been driven by the extensive use of simulation as a critical tool for training and testing robotic systems prior to their deployment in real-world environments. However, simulations consist of abstractions and approximations that inevitably introduce discrepancies between simulated and real environments, known as the reality gap. These discrepancies significantly hinder the successful transfer of systems from simulation to the real world. Closing this gap remains one of the most pressing challenges in robotics. Recent advances in sim-to-real transfer have demonstrated promising results across various platforms, including locomotion, navigation, and manipulation. By leveraging techniques such as domain randomization, real-to-sim transfer, state and action abstractions, and sim-real co-training, many works have overcome the reality gap. However, challenges persist, and a deeper understanding of the reality gap's root causes and solutions is necessary. In this survey, we present a comprehensive overview of the sim-to-real landscape, highlighting the causes, solutions, and evaluation metrics for the reality gap and sim-to-real transfer.
Learning on the Fly: Rapid Policy Adaptation via Differentiable Simulation
Aug 28, 2025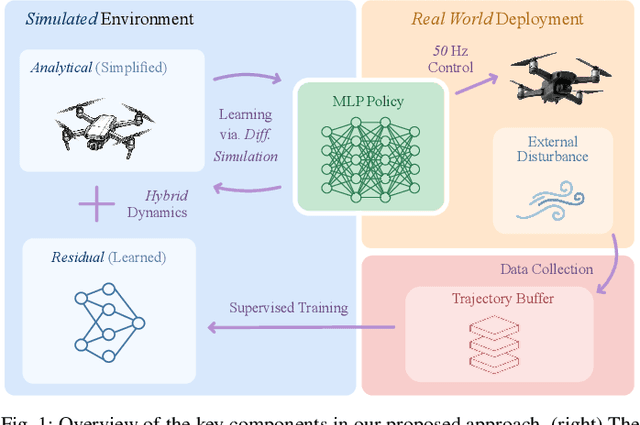

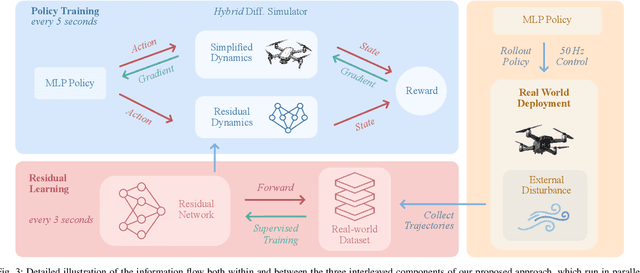
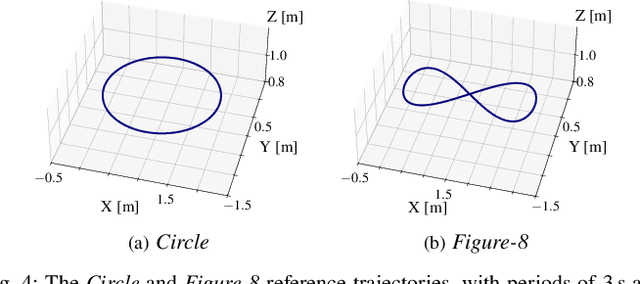
Learning control policies in simulation enables rapid, safe, and cost-effective development of advanced robotic capabilities. However, transferring these policies to the real world remains difficult due to the sim-to-real gap, where unmodeled dynamics and environmental disturbances can degrade policy performance. Existing approaches, such as domain randomization and Real2Sim2Real pipelines, can improve policy robustness, but either struggle under out-of-distribution conditions or require costly offline retraining. In this work, we approach these problems from a different perspective. Instead of relying on diverse training conditions before deployment, we focus on rapidly adapting the learned policy in the real world in an online fashion. To achieve this, we propose a novel online adaptive learning framework that unifies residual dynamics learning with real-time policy adaptation inside a differentiable simulation. Starting from a simple dynamics model, our framework refines the model continuously with real-world data to capture unmodeled effects and disturbances such as payload changes and wind. The refined dynamics model is embedded in a differentiable simulation framework, enabling gradient backpropagation through the dynamics and thus rapid, sample-efficient policy updates beyond the reach of classical RL methods like PPO. All components of our system are designed for rapid adaptation, enabling the policy to adjust to unseen disturbances within 5 seconds of training. We validate the approach on agile quadrotor control under various disturbances in both simulation and the real world. Our framework reduces hovering error by up to 81% compared to L1-MPC and 55% compared to DATT, while also demonstrating robustness in vision-based control without explicit state estimation.
Accelerating Model-Based Reinforcement Learning with State-Space World Models
Feb 27, 2025Reinforcement learning (RL) is a powerful approach for robot learning. However, model-free RL (MFRL) requires a large number of environment interactions to learn successful control policies. This is due to the noisy RL training updates and the complexity of robotic systems, which typically involve highly non-linear dynamics and noisy sensor signals. In contrast, model-based RL (MBRL) not only trains a policy but simultaneously learns a world model that captures the environment's dynamics and rewards. The world model can either be used for planning, for data collection, or to provide first-order policy gradients for training. Leveraging a world model significantly improves sample efficiency compared to model-free RL. However, training a world model alongside the policy increases the computational complexity, leading to longer training times that are often intractable for complex real-world scenarios. In this work, we propose a new method for accelerating model-based RL using state-space world models. Our approach leverages state-space models (SSMs) to parallelize the training of the dynamics model, which is typically the main computational bottleneck. Additionally, we propose an architecture that provides privileged information to the world model during training, which is particularly relevant for partially observable environments. We evaluate our method in several real-world agile quadrotor flight tasks, involving complex dynamics, for both fully and partially observable environments. We demonstrate a significant speedup, reducing the world model training time by up to 10 times, and the overall MBRL training time by up to 4 times. This benefit comes without compromising performance, as our method achieves similar sample efficiency and task rewards to state-of-the-art MBRL methods.
Dream to Fly: Model-Based Reinforcement Learning for Vision-Based Drone Flight
Jan 24, 2025Autonomous drone racing has risen as a challenging robotic benchmark for testing the limits of learning, perception, planning, and control. Expert human pilots are able to agilely fly a drone through a race track by mapping the real-time feed from a single onboard camera directly to control commands. Recent works in autonomous drone racing attempting direct pixel-to-commands control policies (without explicit state estimation) have relied on either intermediate representations that simplify the observation space or performed extensive bootstrapping using Imitation Learning (IL). This paper introduces an approach that learns policies from scratch, allowing a quadrotor to autonomously navigate a race track by directly mapping raw onboard camera pixels to control commands, just as human pilots do. By leveraging model-based reinforcement learning~(RL) - specifically DreamerV3 - we train visuomotor policies capable of agile flight through a race track using only raw pixel observations. While model-free RL methods such as PPO struggle to learn under these conditions, DreamerV3 efficiently acquires complex visuomotor behaviors. Moreover, because our policies learn directly from pixel inputs, the perception-aware reward term employed in previous RL approaches to guide the training process is no longer needed. Our experiments demonstrate in both simulation and real-world flight how the proposed approach can be deployed on agile quadrotors. This approach advances the frontier of vision-based autonomous flight and shows that model-based RL is a promising direction for real-world robotics.
Multi-Task Reinforcement Learning for Quadrotors
Dec 17, 2024Reinforcement learning (RL) has shown great effectiveness in quadrotor control, enabling specialized policies to develop even human-champion-level performance in single-task scenarios. However, these specialized policies often struggle with novel tasks, requiring a complete retraining of the policy from scratch. To address this limitation, this paper presents a novel multi-task reinforcement learning (MTRL) framework tailored for quadrotor control, leveraging the shared physical dynamics of the platform to enhance sample efficiency and task performance. By employing a multi-critic architecture and shared task encoders, our framework facilitates knowledge transfer across tasks, enabling a single policy to execute diverse maneuvers, including high-speed stabilization, velocity tracking, and autonomous racing. Our experimental results, validated both in simulation and real-world scenarios, demonstrate that our framework outperforms baseline approaches in terms of sample efficiency and overall task performance.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
Student-Informed Teacher Training
Dec 12, 2024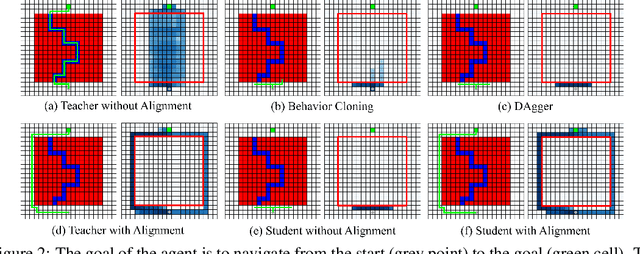
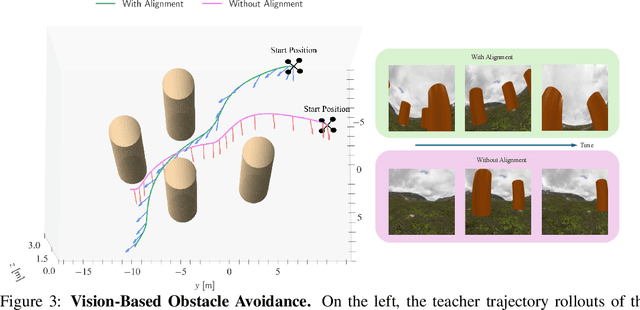
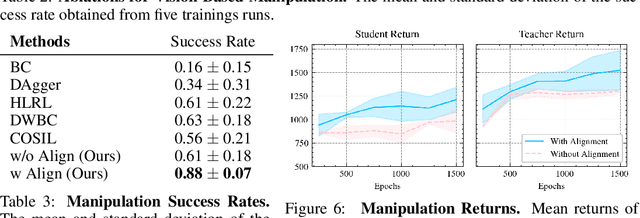
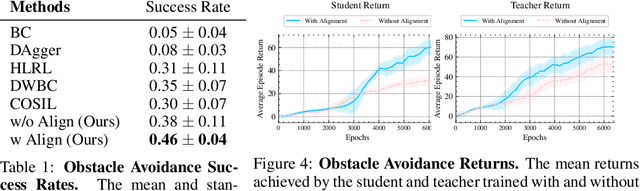
Imitation learning with a privileged teacher has proven effective for learning complex control behaviors from high-dimensional inputs, such as images. In this framework, a teacher is trained with privileged task information, while a student tries to predict the actions of the teacher with more limited observations, e.g., in a robot navigation task, the teacher might have access to distances to nearby obstacles, while the student only receives visual observations of the scene. However, privileged imitation learning faces a key challenge: the student might be unable to imitate the teacher's behavior due to partial observability. This problem arises because the teacher is trained without considering if the student is capable of imitating the learned behavior. To address this teacher-student asymmetry, we propose a framework for joint training of the teacher and student policies, encouraging the teacher to learn behaviors that can be imitated by the student despite the latters' limited access to information and its partial observability. Based on the performance bound in imitation learning, we add (i) the approximated action difference between teacher and student as a penalty term to the reward function of the teacher, and (ii) a supervised teacher-student alignment step. We motivate our method with a maze navigation task and demonstrate its effectiveness on complex vision-based quadrotor flight and manipulation tasks.
LIMT: Language-Informed Multi-Task Visual World Models
Jul 18, 2024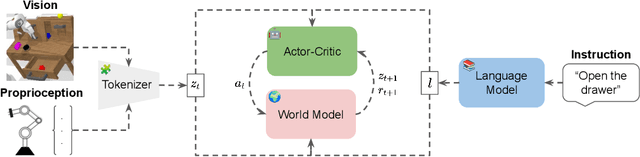
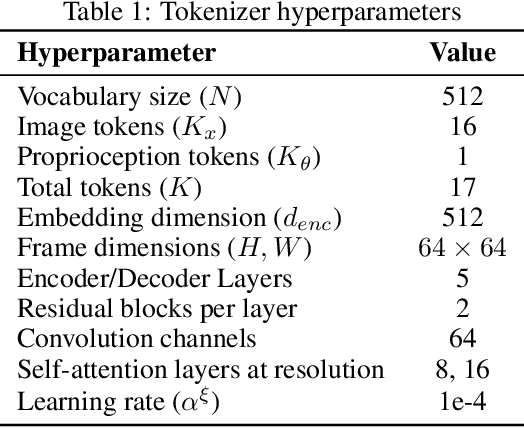
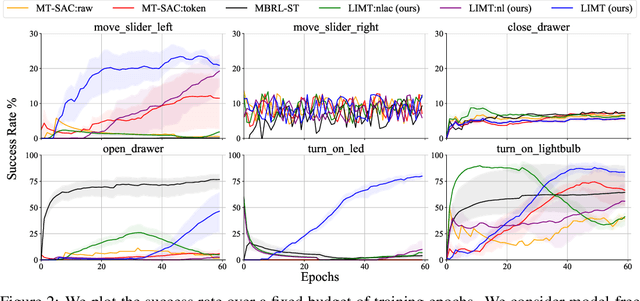
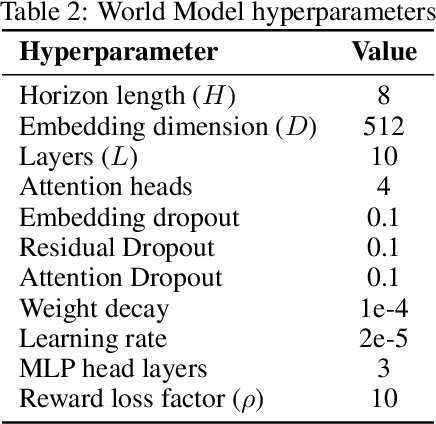
Most recent successes in robot reinforcement learning involve learning a specialized single-task agent. However, robots capable of performing multiple tasks can be much more valuable in real-world applications. Multi-task reinforcement learning can be very challenging due to the increased sample complexity and the potentially conflicting task objectives. Previous work on this topic is dominated by model-free approaches. The latter can be very sample inefficient even when learning specialized single-task agents. In this work, we focus on model-based multi-task reinforcement learning. We propose a method for learning multi-task visual world models, leveraging pre-trained language models to extract semantically meaningful task representations. These representations are used by the world model and policy to reason about task similarity in dynamics and behavior. Our results highlight the benefits of using language-driven task representations for world models and a clear advantage of model-based multi-task learning over the more common model-free paradigm.
The Shortcomings of Force-from-Motion in Robot Learning
Jul 03, 2024
Robotic manipulation requires accurate motion and physical interaction control. However, current robot learning approaches focus on motion-centric action spaces that do not explicitly give the policy control over the interaction. In this paper, we discuss the repercussions of this choice and argue for more interaction-explicit action spaces in robot learning.