 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Event Pretraining with Foundation Model Alignment
Mar 24, 2026Event cameras provide robust visual signals under fast motion and challenging illumination conditions thanks to their microsecond latency and high dynamic range. However, their unique sensing characteristics and limited labeled data make it challenging to train event-based visual foundation models (VFMs), which are crucial for learning visual features transferable across tasks. To tackle this problem, we propose GEP (Generative Event Pretraining), a two-stage framework that transfers semantic knowledge learned from internet-scale image datasets to event data while learning event-specific temporal dynamics. First, an event encoder is aligned to a frozen VFM through a joint regression-contrastive objective, grounding event features in image semantics. Second, a transformer backbone is autoregressively pretrained on mixed event-image sequences to capture the temporal structure unique to events. Our approach outperforms state-of-the-art event pretraining methods on a diverse range of downstream tasks, including object recognition, segmentation, and depth estimation. Together, VFM-guided alignment and generative sequence modeling yield a semantically rich, temporally aware event model that generalizes robustly across domains.
Approximate Imitation Learning for Event-based Quadrotor Flight in Cluttered Environments
Mar 08, 2026Event cameras offer high temporal resolution and low latency, making them ideal sensors for high-speed robotic applications where conventional cameras suffer from image degradations such as motion blur. In addition, their low power consumption can enhance endurance, which is critical for resource-constrained platforms. Motivated by these properties, we present a novel approach that enables a quadrotor to fly through cluttered environments at high speed by perceiving the environment with a single event camera. Our proposed method employs an end-to-end neural network trained to map event data directly to control commands, eliminating the reliance on standard cameras. To enable efficient training in simulation, where rendering synthetic event data is computationally expensive, we propose Approximate Imitation Learning, a novel imitation learning framework. Our approach leverages a large-scale offline dataset to learn a task-specific representation space. Subsequently, the policy is trained through online interactions that rely solely on lightweight, simulated state information, eliminating the need to render events during training. This enables the efficient training of event-based control policies for fast quadrotor flight, highlighting the potential of our framework for other modalities where data simulation is costly or impractical. Our approach outperforms standard imitation learning baselines in simulation and demonstrates robust performance in real-world flight tests, achieving speeds up to 9.8 ms-1 in cluttered environments.
Motion-aware Event Suppression for Event Cameras
Feb 26, 2026In this work, we introduce the first framework for Motion-aware Event Suppression, which learns to filter events triggered by IMOs and ego-motion in real time. Our model jointly segments IMOs in the current event stream while predicting their future motion, enabling anticipatory suppression of dynamic events before they occur. Our lightweight architecture achieves 173 Hz inference on consumer-grade GPUs with less than 1 GB of memory usage, outperforming previous state-of-the-art methods on the challenging EVIMO benchmark by 67\% in segmentation accuracy while operating at a 53\% higher inference rate. Moreover, we demonstrate significant benefits for downstream applications: our method accelerates Vision Transformer inference by 83\% via token pruning and improves event-based visual odometry accuracy, reducing Absolute Trajectory Error (ATE) by 13\%.
Reading in the Dark with Foveated Event Vision
Jun 07, 2025



Current smart glasses equipped with RGB cameras struggle to perceive the environment in low-light and high-speed motion scenarios due to motion blur and the limited dynamic range of frame cameras. Additionally, capturing dense images with a frame camera requires large bandwidth and power consumption, consequently draining the battery faster. These challenges are especially relevant for developing algorithms that can read text from images. In this work, we propose a novel event-based Optical Character Recognition (OCR) approach for smart glasses. By using the eye gaze of the user, we foveate the event stream to significantly reduce bandwidth by around 98% while exploiting the benefits of event cameras in high-dynamic and fast scenes. Our proposed method performs deep binary reconstruction trained on synthetic data and leverages multimodal LLMs for OCR, outperforming traditional OCR solutions. Our results demonstrate the ability to read text in low light environments where RGB cameras struggle while using up to 2400 times less bandwidth than a wearable RGB camera.
ForesightNav: Learning Scene Imagination for Efficient Exploration
Apr 22, 2025Understanding how humans leverage prior knowledge to navigate unseen environments while making exploratory decisions is essential for developing autonomous robots with similar abilities. In this work, we propose ForesightNav, a novel exploration strategy inspired by human imagination and reasoning. Our approach equips robotic agents with the capability to predict contextual information, such as occupancy and semantic details, for unexplored regions. These predictions enable the robot to efficiently select meaningful long-term navigation goals, significantly enhancing exploration in unseen environments. We validate our imagination-based approach using the Structured3D dataset, demonstrating accurate occupancy prediction and superior performance in anticipating unseen scene geometry. Our experiments show that the imagination module improves exploration efficiency in unseen environments, achieving a 100% completion rate for PointNav and an SPL of 67% for ObjectNav on the Structured3D Validation split. These contributions demonstrate the power of imagination-driven reasoning for autonomous systems to enhance generalizable and efficient exploration.
Student-Informed Teacher Training
Dec 12, 2024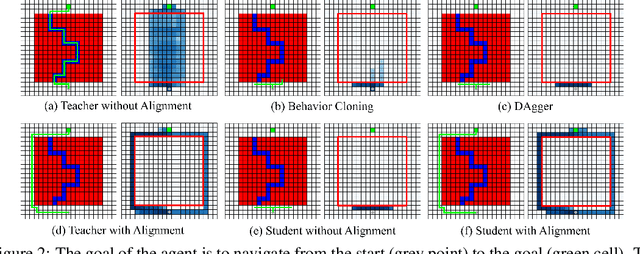
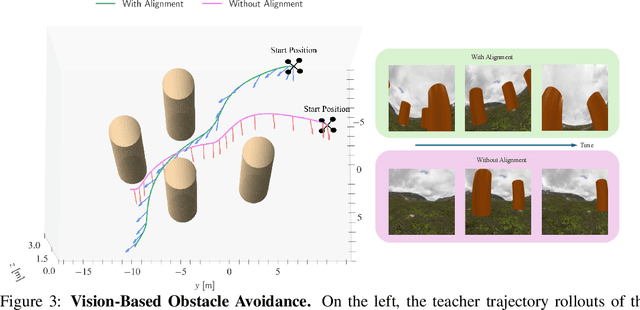
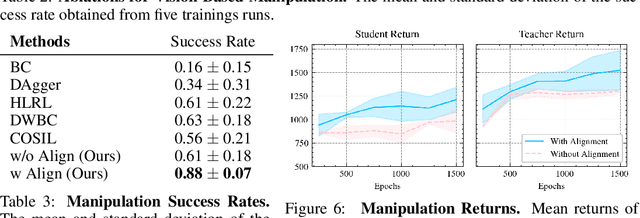
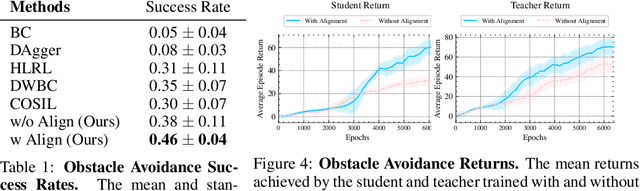
Imitation learning with a privileged teacher has proven effective for learning complex control behaviors from high-dimensional inputs, such as images. In this framework, a teacher is trained with privileged task information, while a student tries to predict the actions of the teacher with more limited observations, e.g., in a robot navigation task, the teacher might have access to distances to nearby obstacles, while the student only receives visual observations of the scene. However, privileged imitation learning faces a key challenge: the student might be unable to imitate the teacher's behavior due to partial observability. This problem arises because the teacher is trained without considering if the student is capable of imitating the learned behavior. To address this teacher-student asymmetry, we propose a framework for joint training of the teacher and student policies, encouraging the teacher to learn behaviors that can be imitated by the student despite the latters' limited access to information and its partial observability. Based on the performance bound in imitation learning, we add (i) the approximated action difference between teacher and student as a penalty term to the reward function of the teacher, and (ii) a supervised teacher-student alignment step. We motivate our method with a maze navigation task and demonstrate its effectiveness on complex vision-based quadrotor flight and manipulation tasks.
Environment as Policy: Learning to Race in Unseen Tracks
Oct 29, 2024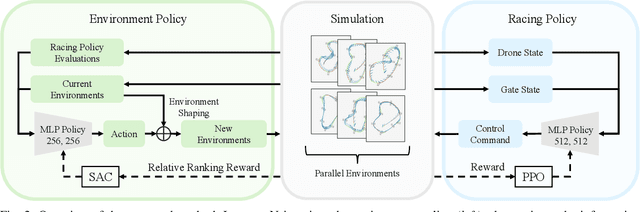

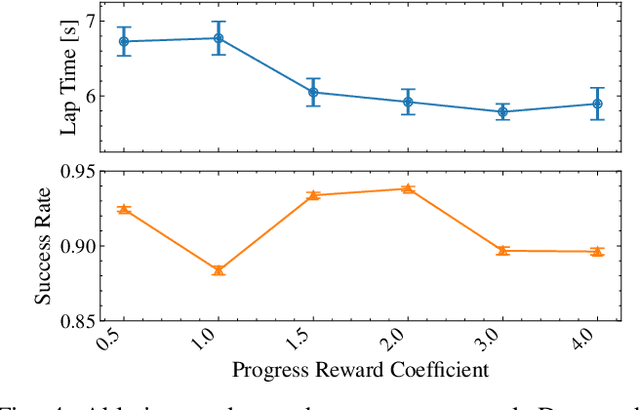
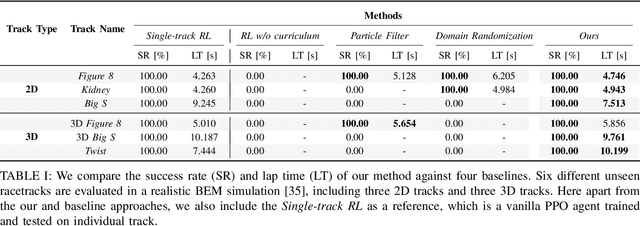
Reinforcement learning (RL) has achieved outstanding success in complex robot control tasks, such as drone racing, where the RL agents have outperformed human champions in a known racing track. However, these agents fail in unseen track configurations, always requiring complete retraining when presented with new track layouts. This work aims to develop RL agents that generalize effectively to novel track configurations without retraining. The naive solution of training directly on a diverse set of track layouts can overburden the agent, resulting in suboptimal policy learning as the increased complexity of the environment impairs the agent's ability to learn to fly. To enhance the generalizability of the RL agent, we propose an adaptive environment-shaping framework that dynamically adjusts the training environment based on the agent's performance. We achieve this by leveraging a secondary RL policy to design environments that strike a balance between being challenging and achievable, allowing the agent to adapt and improve progressively. Using our adaptive environment shaping, one single racing policy efficiently learns to race in diverse challenging tracks. Experimental results validated in both simulation and the real world show that our method enables drones to successfully fly complex and unseen race tracks, outperforming existing environment-shaping techniques. Project page: http://rpg.ifi.uzh.ch/env_as_policy/index.html
S7: Selective and Simplified State Space Layers for Sequence Modeling
Oct 04, 2024A central challenge in sequence modeling is efficiently handling tasks with extended contexts. While recent state-space models (SSMs) have made significant progress in this area, they often lack input-dependent filtering or require substantial increases in model complexity to handle input variability. We address this gap by introducing S7, a simplified yet powerful SSM that can handle input dependence while incorporating stable reparameterization and specific design choices to dynamically adjust state transitions based on input content, maintaining efficiency and performance. We prove that this reparameterization ensures stability in long-sequence modeling by keeping state transitions well-behaved over time. Additionally, it controls the gradient norm, enabling efficient training and preventing issues like exploding or vanishing gradients. S7 significantly outperforms baselines across various sequence modeling tasks, including neuromorphic event-based datasets, Long Range Arena benchmarks, and various physical and biological time series. Overall, S7 offers a more straightforward approach to sequence modeling without relying on complex, domain-specific inductive biases, achieving significant improvements across key benchmarks.
Reinforcement Learning Meets Visual Odometry
Jul 22, 2024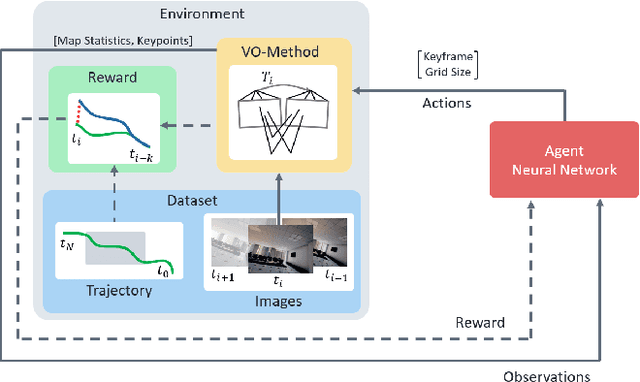

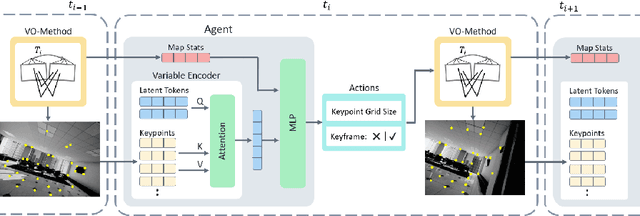

Visual Odometry (VO) is essential to downstream mobile robotics and augmented/virtual reality tasks. Despite recent advances, existing VO methods still rely on heuristic design choices that require several weeks of hyperparameter tuning by human experts, hindering generalizability and robustness. We address these challenges by reframing VO as a sequential decision-making task and applying Reinforcement Learning (RL) to adapt the VO process dynamically. Our approach introduces a neural network, operating as an agent within the VO pipeline, to make decisions such as keyframe and grid-size selection based on real-time conditions. Our method minimizes reliance on heuristic choices using a reward function based on pose error, runtime, and other metrics to guide the system. Our RL framework treats the VO system and the image sequence as an environment, with the agent receiving observations from keypoints, map statistics, and prior poses. Experimental results using classical VO methods and public benchmarks demonstrate improvements in accuracy and robustness, validating the generalizability of our RL-enhanced VO approach to different scenarios. We believe this paradigm shift advances VO technology by eliminating the need for time-intensive parameter tuning of heuristics.
Contrastive Initial State Buffer for Reinforcement Learning
Sep 20, 2023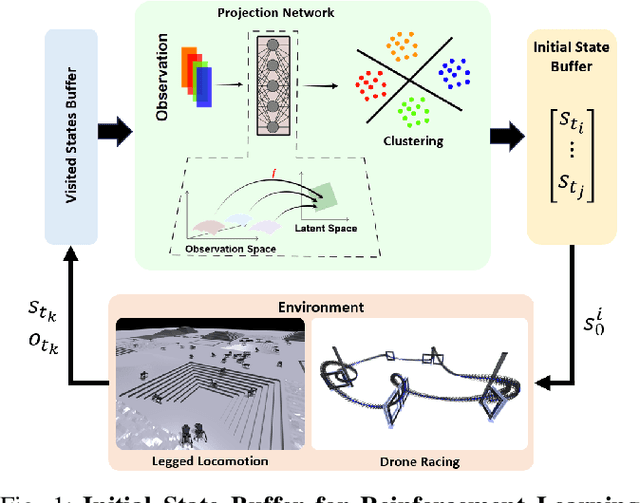
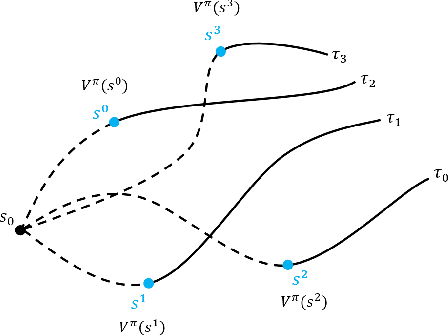
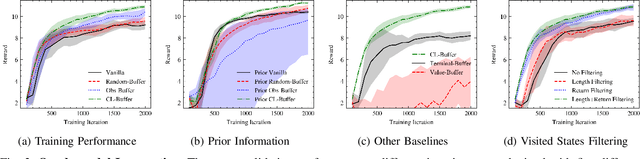

In Reinforcement Learning, the trade-off between exploration and exploitation poses a complex challenge for achieving efficient learning from limited samples. While recent works have been effective in leveraging past experiences for policy updates, they often overlook the potential of reusing past experiences for data collection. Independent of the underlying RL algorithm, we introduce the concept of a Contrastive Initial State Buffer, which strategically selects states from past experiences and uses them to initialize the agent in the environment in order to guide it toward more informative states. We validate our approach on two complex robotic tasks without relying on any prior information about the environment: (i) locomotion of a quadruped robot traversing challenging terrains and (ii) a quadcopter drone racing through a track. The experimental results show that our initial state buffer achieves higher task performance than the nominal baseline while also speeding up training convergence.