 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Cameras Meet SPADs for High-Speed, Low-Bandwidth Imaging
Apr 17, 2024



Traditional cameras face a trade-off between low-light performance and high-speed imaging: longer exposure times to capture sufficient light results in motion blur, whereas shorter exposures result in Poisson-corrupted noisy images. While burst photography techniques help mitigate this tradeoff, conventional cameras are fundamentally limited in their sensor noise characteristics. Event cameras and single-photon avalanche diode (SPAD) sensors have emerged as promising alternatives to conventional cameras due to their desirable properties. SPADs are capable of single-photon sensitivity with microsecond temporal resolution, and event cameras can measure brightness changes up to 1 MHz with low bandwidth requirements. We show that these properties are complementary, and can help achieve low-light, high-speed image reconstruction with low bandwidth requirements. We introduce a sensor fusion framework to combine SPADs with event cameras to improves the reconstruction of high-speed, low-light scenes while reducing the high bandwidth cost associated with using every SPAD frame. Our evaluation, on both synthetic and real sensor data, demonstrates significant enhancements ( > 5 dB PSNR) in reconstructing low-light scenes at high temporal resolution (100 kHz) compared to conventional cameras. Event-SPAD fusion shows great promise for real-world applications, such as robotics or medical imaging.
Seeing Behind Dynamic Occlusions with Event Cameras
Aug 01, 2023
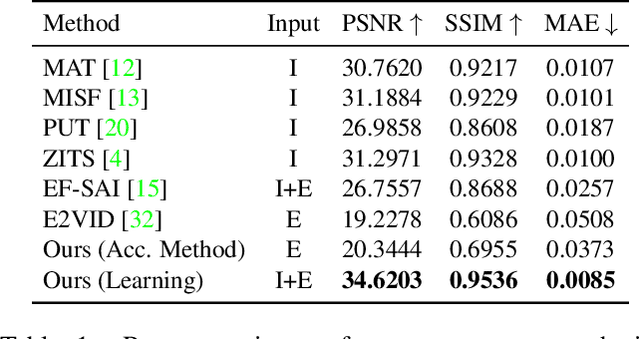
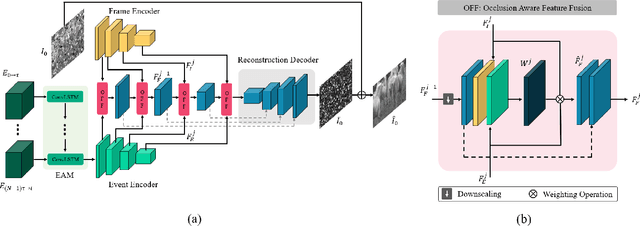
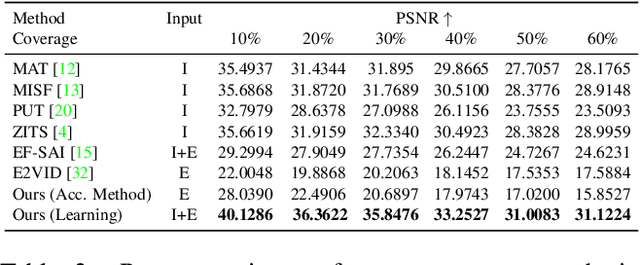
Unwanted camera occlusions, such as debris, dust, rain-drops, and snow, can severely degrade the performance of computer-vision systems. Dynamic occlusions are particularly challenging because of the continuously changing pattern. Existing occlusion-removal methods currently use synthetic aperture imaging or image inpainting. However, they face issues with dynamic occlusions as these require multiple viewpoints or user-generated masks to hallucinate the background intensity. We propose a novel approach to reconstruct the background from a single viewpoint in the presence of dynamic occlusions. Our solution relies for the first time on the combination of a traditional camera with an event camera. When an occlusion moves across a background image, it causes intensity changes that trigger events. These events provide additional information on the relative intensity changes between foreground and background at a high temporal resolution, enabling a truer reconstruction of the background content. We present the first large-scale dataset consisting of synchronized images and event sequences to evaluate our approach. We show that our method outperforms image inpainting methods by 3dB in terms of PSNR on our dataset.
Event-based Shape from Polarization
Jan 17, 2023State-of-the-art solutions for Shape-from-Polarization (SfP) suffer from a speed-resolution tradeoff: they either sacrifice the number of polarization angles measured or necessitate lengthy acquisition times due to framerate constraints, thus compromising either accuracy or latency. We tackle this tradeoff using event cameras. Event cameras operate at microseconds resolution with negligible motion blur, and output a continuous stream of events that precisely measures how light changes over time asynchronously. We propose a setup that consists of a linear polarizer rotating at high-speeds in front of an event camera. Our method uses the continuous event stream caused by the rotation to reconstruct relative intensities at multiple polarizer angles. Experiments demonstrate that our method outperforms physics-based baselines using frames, reducing the MAE by 25% in synthetic and real-world dataset. In the real world, we observe, however, that the challenging conditions (i.e., when few events are generated) harm the performance of physics-based solutions. To overcome this, we propose a learning-based approach that learns to estimate surface normals even at low event-rates, improving the physics-based approach by 52% on the real world dataset. The proposed system achieves an acquisition speed equivalent to 50 fps (>twice the framerate of the commercial polarization sensor) while retaining the spatial resolution of 1MP. Our evaluation is based on the first large-scale dataset for event-based SfP
Cracking Double-Blind Review: Authorship Attribution with Deep Learning
Nov 14, 2022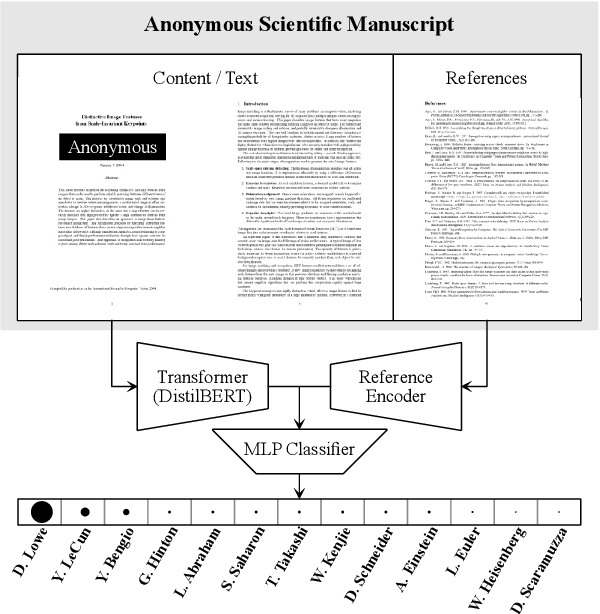



Double-blind peer review is considered a pillar of academic research because it is perceived to ensure a fair, unbiased, and fact-centered scientific discussion. Yet, experienced researchers can often correctly guess from which research group an anonymous submission originates, biasing the peer-review process. In this work, we present a transformer-based, neural-network architecture that only uses the text content and the author names in the bibliography to atttribute an anonymous manuscript to an author. To train and evaluate our method, we created the largest authorship-identification dataset to date. It leverages all research papers publicly available on arXiv amounting to over 2 million manuscripts. In arXiv-subsets with up to 2,000 different authors, our method achieves an unprecedented authorship attribution accuracy, where up to 95% of papers are attributed correctly. Thanks to our method, we are not only able to predict the author of an anonymous work but we also identify weaknesses of the double-blind review process by finding the key aspects that make a paper attributable. We believe that this work gives precious insights into how a submission can remain anonymous in order to support an unbiased double-blind review process.
Dense Continuous-Time Optical Flow from Events and Frames
Mar 25, 2022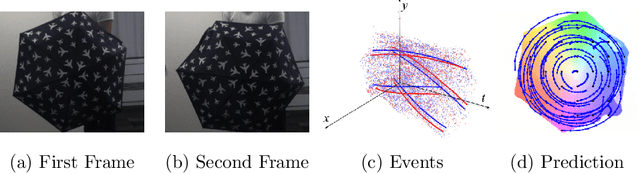
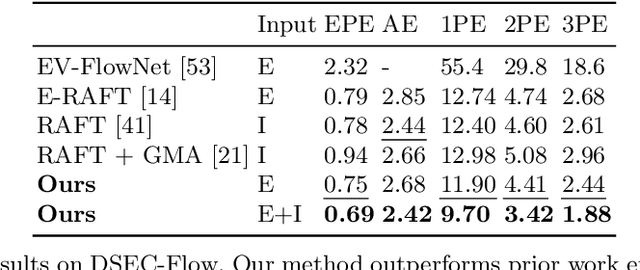
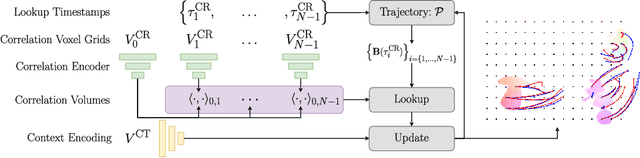
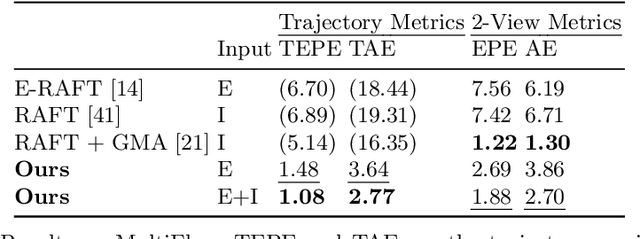
We present a method for estimating dense continuous-time optical flow. Traditional dense optical flow methods compute the pixel displacement between two images. Due to missing information, these approaches cannot recover the pixel trajectories in the blind time between two images. In this work, we show that it is possible to compute per-pixel, continuous-time optical flow by additionally using events from an event camera. Events provide temporally fine-grained information about movement in image space due to their asynchronous nature and microsecond response time. We leverage these benefits to predict pixel trajectories densely in continuous-time via parameterized B\'ezier curves. To achieve this, we introduce multiple innovations to build a neural network with strong inductive biases for this task: First, we build multiple sequential correlation volumes in time using event data. Second, we use B\'ezier curves to index these correlation volumes at multiple timestamps along the trajectory. Third, we use the retrieved correlation to update the B\'ezier curve representations iteratively. Our method can optionally include image pairs to boost performance further. The proposed approach outperforms existing image-based and event-based methods by 11.5 % lower EPE on DSEC-Flow. Finally, we introduce a novel synthetic dataset MultiFlow for pixel trajectory regression on which our method is currently the only successful approach.
ESL: Event-based Structured Light
Nov 30, 2021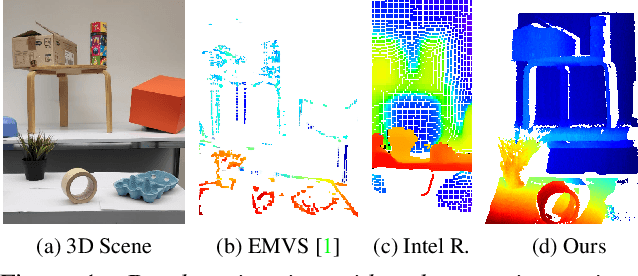
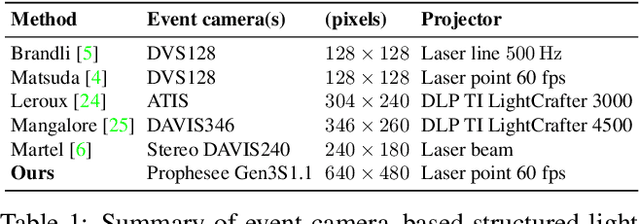

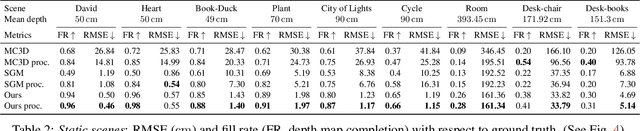
Event cameras are bio-inspired sensors providing significant advantages over standard cameras such as low latency, high temporal resolution, and high dynamic range. We propose a novel structured-light system using an event camera to tackle the problem of accurate and high-speed depth sensing. Our setup consists of an event camera and a laser-point projector that uniformly illuminates the scene in a raster scanning pattern during 16 ms. Previous methods match events independently of each other, and so they deliver noisy depth estimates at high scanning speeds in the presence of signal latency and jitter. In contrast, we optimize an energy function designed to exploit event correlations, called spatio-temporal consistency. The resulting method is robust to event jitter and therefore performs better at higher scanning speeds. Experiments demonstrate that our method can deal with high-speed motion and outperform state-of-the-art 3D reconstruction methods based on event cameras, reducing the RMSE by 83% on average, for the same acquisition time.
Event Guided Depth Sensing
Oct 20, 2021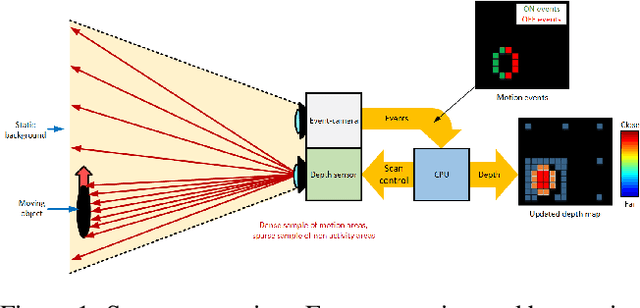

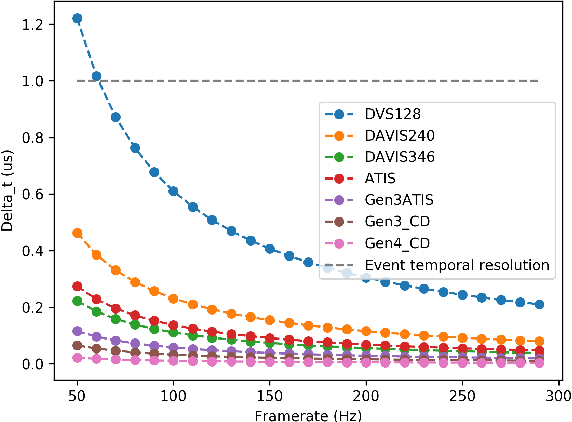

Active depth sensors like structured light, lidar, and time-of-flight systems sample the depth of the entire scene uniformly at a fixed scan rate. This leads to limited spatio-temporal resolution where redundant static information is over-sampled and precious motion information might be under-sampled. In this paper, we present an efficient bio-inspired event-camera-driven depth estimation algorithm. In our approach, we dynamically illuminate areas of interest densely, depending on the scene activity detected by the event camera, and sparsely illuminate areas in the field of view with no motion. The depth estimation is achieved by an event-based structured light system consisting of a laser point projector coupled with a second event-based sensor tuned to detect the reflection of the laser from the scene. We show the feasibility of our approach in a simulated autonomous driving scenario and real indoor sequences using our prototype. We show that, in natural scenes like autonomous driving and indoor environments, moving edges correspond to less than 10% of the scene on average. Thus our setup requires the sensor to scan only 10% of the scene, which could lead to almost 90% less power consumption by the illumination source. While we present the evaluation and proof-of-concept for an event-based structured-light system, the ideas presented here are applicable for a wide range of depth-sensing modalities like LIDAR, time-of-flight, and standard stereo.
How to Calibrate Your Event Camera
May 26, 2021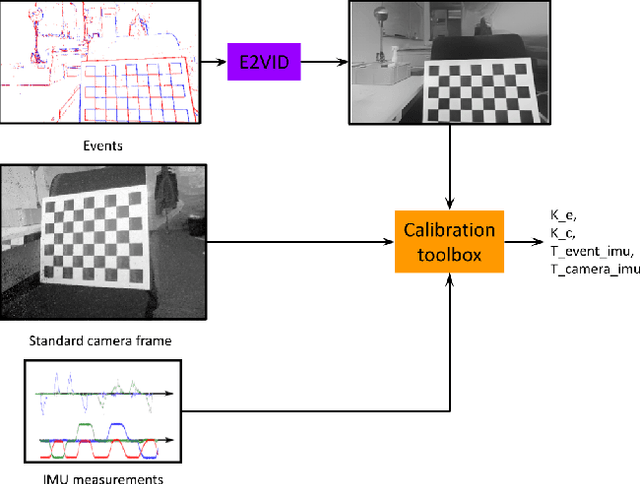



We propose a generic event camera calibration framework using image reconstruction. Instead of relying on blinking LED patterns or external screens, we show that neural-network-based image reconstruction is well suited for the task of intrinsic and extrinsic calibration of event cameras. The advantage of our proposed approach is that we can use standard calibration patterns that do not rely on active illumination. Furthermore, our approach enables the possibility to perform extrinsic calibration between frame-based and event-based sensors without additional complexity. Both simulation and real-world experiments indicate that calibration through image reconstruction is accurate under common distortion models and a wide variety of distortion parameters
AlphaPilot: Autonomous Drone Racing
May 26, 2020

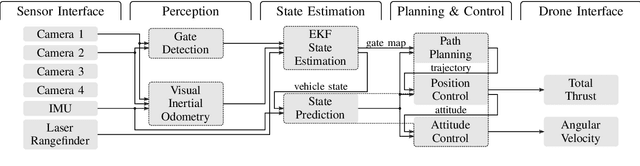

This paper presents a novel system for autonomous, vision-based drone racing combining learned data abstraction, nonlinear filtering, and time-optimal trajectory planning. The system has successfully been deployed at the first autonomous drone racing world championship: the 2019 AlphaPilot Challenge. Contrary to traditional drone racing systems, which only detect the next gate, our approach makes use of any visible gate and takes advantage of multiple, simultaneous gate detections to compensate for drift in the state estimate and build a global map of the gates. The global map and drift-compensated state estimate allow the drone to navigate through the race course even when the gates are not immediately visible and further enable to plan a near time-optimal path through the race course in real time based on approximate drone dynamics. The proposed system has been demonstrated to successfully guide the drone through tight race courses reaching speeds up to 8m/s and ranked second at the 2019 AlphaPilot Challenge.
Voxel Map for Visual SLAM
Mar 04, 2020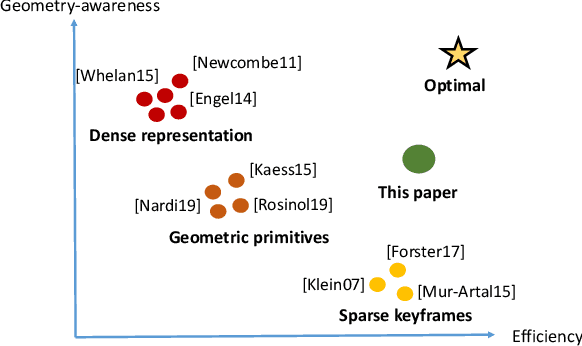
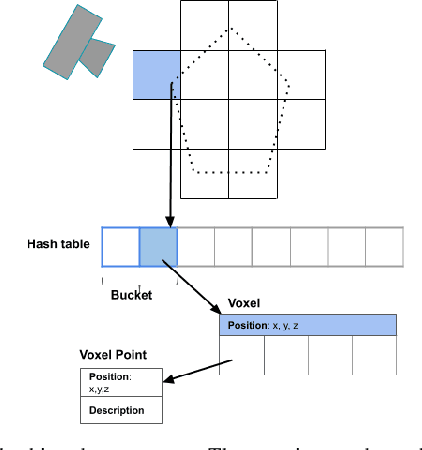
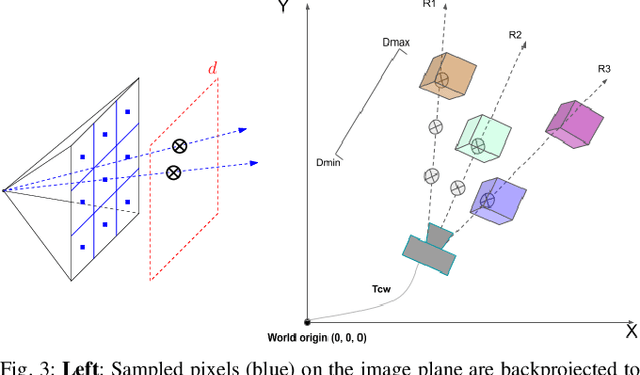
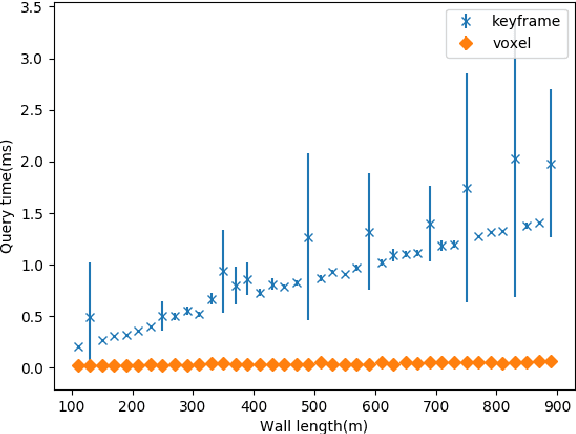
In modern visual SLAM systems, it is a standard practice to retrieve potential candidate map points from overlapping keyframes for further feature matching or direct tracking. In this work, we argue that keyframes are not the optimal choice for this task, due to several inherent limitations, such as weak geometric reasoning and poor scalability. We propose a voxel-map representation to efficiently retrieve map points for visual SLAM. In particular, we organize the map points in a regular voxel grid. Visible points from a camera pose are queried by sampling the camera frustum in a raycasting manner, which can be done in constant time using an efficient voxel hashing method. Compared with keyframes, the retrieved points using our method are geometrically guaranteed to fall in the camera field-of-view, and occluded points can be identified and removed to a certain extend. This method also naturally scales up to large scenes and complicated multicamera configurations. Experimental results show that our voxel map representation is as efficient as a keyframe map with 5 keyframes and provides significantly higher localization accuracy (average 46% improvement in RMSE) on the EuRoC dataset. The proposed voxel-map representation is a general approach to a fundamental functionality in visual SLAM and widely applicable.