 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time vs. Discrete-Time Vision-based SLAM: A Comparative Study
Feb 17, 2022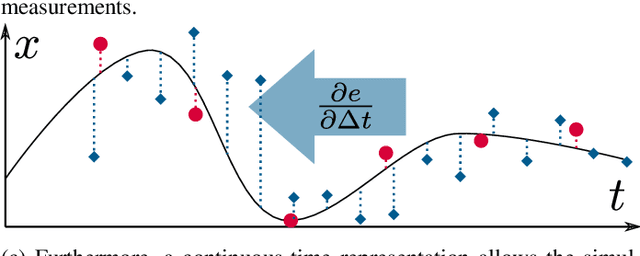
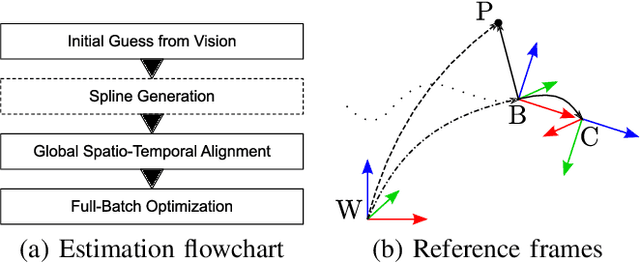
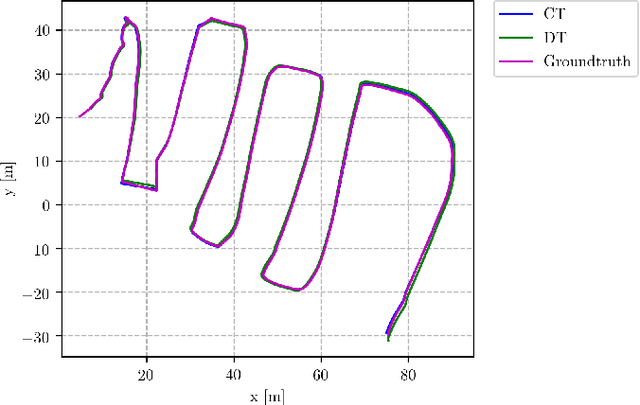
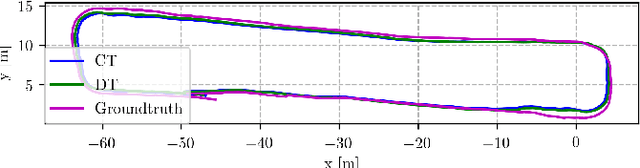
Robotic practitioners generally approach the vision-based SLAM problem through discrete-time formulations. This has the advantage of a consolidated theory and very good understanding of success and failure cases. However, discrete-time SLAM needs tailored algorithms and simplifying assumptions when high-rate and/or asynchronous measurements, coming from different sensors, are present in the estimation process. Conversely, continuous-time SLAM, often overlooked by practitioners, does not suffer from these limitations. Indeed, it allows integrating new sensor data asynchronously without adding a new optimization variable for each new measurement. In this way, the integration of asynchronous or continuous high-rate streams of sensor data does not require tailored and highly-engineered algorithms, enabling the fusion of multiple sensor modalities in an intuitive fashion. On the down side, continuous time introduces a prior that could worsen the trajectory estimates in some unfavorable situations. In this work, we aim at systematically comparing the advantages and limitations of the two formulations in vision-based SLAM. To do so, we perform an extensive experimental analysis, varying robot type, speed of motion, and sensor modalities. Our experimental analysis suggests that, independently of the trajectory type, continuous-time SLAM is superior to its discrete counterpart whenever the sensors are not time-synchronized. In the context of this work, we developed, and open source, a modular and efficient software architecture containing state-of-the-art algorithms to solve the SLAM problem in discrete and continuous time.
* IEEE Robotics and Automation Letters (RA-L), 2022
AlphaPilot: Autonomous Drone Racing
May 26, 2020

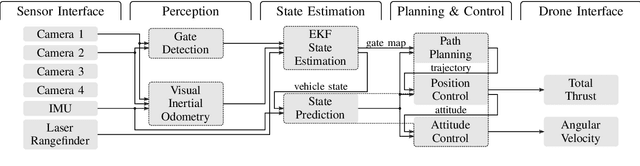

This paper presents a novel system for autonomous, vision-based drone racing combining learned data abstraction, nonlinear filtering, and time-optimal trajectory planning. The system has successfully been deployed at the first autonomous drone racing world championship: the 2019 AlphaPilot Challenge. Contrary to traditional drone racing systems, which only detect the next gate, our approach makes use of any visible gate and takes advantage of multiple, simultaneous gate detections to compensate for drift in the state estimate and build a global map of the gates. The global map and drift-compensated state estimate allow the drone to navigate through the race course even when the gates are not immediately visible and further enable to plan a near time-optimal path through the race course in real time based on approximate drone dynamics. The proposed system has been demonstrated to successfully guide the drone through tight race courses reaching speeds up to 8m/s and ranked second at the 2019 AlphaPilot Challenge.
Augmenting Visual Place Recognition with Structural Cues
Feb 29, 2020
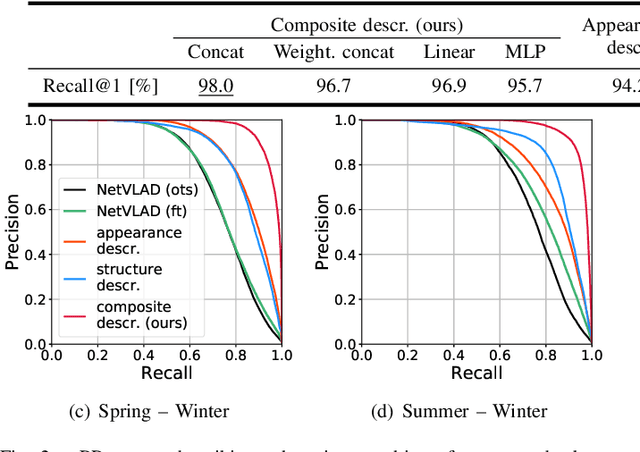
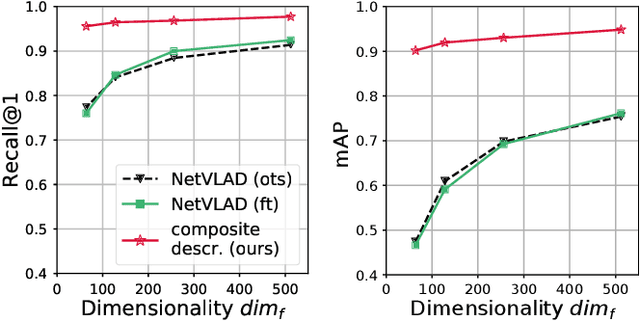
In this paper, we propose to augment image-based place recognition with structural cues. Specifically, these structural cues are obtained using structure-from-motion, such that no additional sensors are needed for place recognition. This is achieved by augmenting the 2D convolutional neural network (CNN) typically used for image-based place recognition with a 3D CNN that takes as input a voxel grid derived from the structure-from-motion point cloud. We evaluate different methods for fusing the 2D and 3D features and obtain best performance with global average pooling and simple concatenation. The resulting descriptor exhibits superior recognition performance compared to descriptors extracted from only one of the input modalities, including state-of-the-art image-based descriptors. Especially at low descriptor dimensionalities, we outperform state-of-the-art descriptors by up to 90%.
Exploration Without Global Consistency Using Local Volume Consolidation
Sep 03, 2019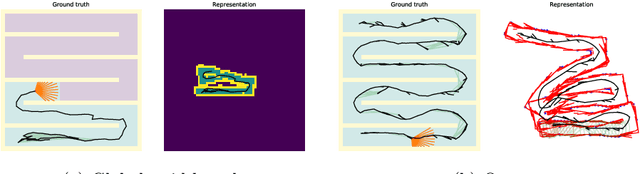
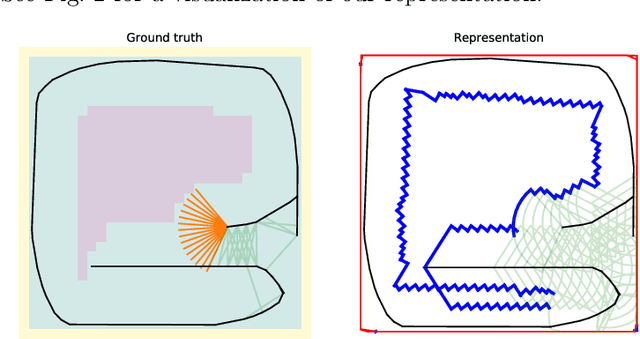
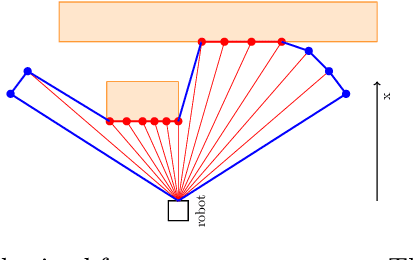

In exploration, the goal is to build a map of an unknown environment. Most state-of-the-art approaches use map representations that require drift-free state estimates to function properly. Real-world state estimators, however, exhibit drift. In this paper, we present a 2D map representation for exploration that is robust to drift. Rather than a global map, it uses local metric volumes connected by relative pose estimates. This pose-graph does not need to be globally consistent. Overlaps between the volumes are resolved locally, rather than on the faulty estimate of space. We demonstrate our representation with a frontier-based exploration approach, evaluate it under different conditions and compare it with a commonly-used grid-based representation. We show that, at the cost of longer exploration time, using the proposed representation allows full coverage of space even for very large drift in the state estimate, contrary to the grid-based representation. The system is validated in a real world experiment and we discuss its extension to 3D.
* 16 pages with large margins, accepted for publication at the International Symposium on Robotics Research (ISRR), Hanoi, 2019
Matching Features without Descriptors: Implicitly Matched Interest Points (IMIPs)
Nov 26, 2018
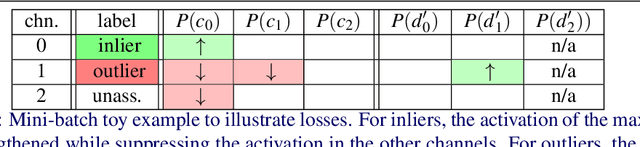
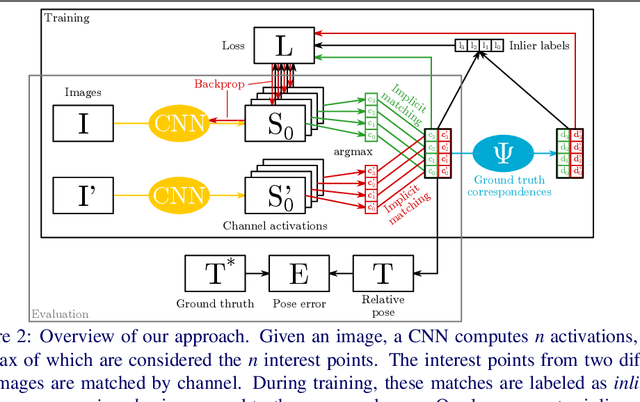
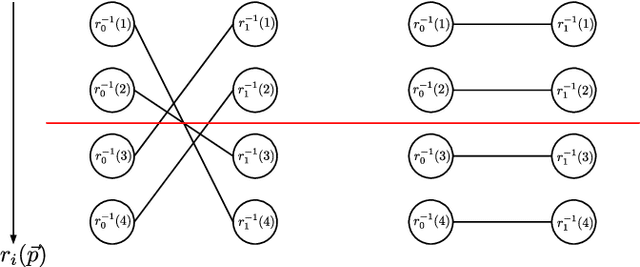
The extraction and matching of interest points is a prerequisite for visual pose estimation and related problems. Traditionally, matching has been achieved by assigning descriptors to interest points and matching points that have similar descriptors. In this paper, we propose a method by which interest points are instead already implicitly matched at detection time. Thanks to this, descriptors do not need to be calculated, stored, communicated, or matched any more. This is achieved by a convolutional neural network with multiple output channels. The i-th interest point is the location of the maximum of the i-th channel, and the i-th interest point in one image is implicitly matched with the i-th interest point in another image. This paper describes how to design and train such a network in a way that results in successful relative pose estimation performance with as little as 128 output channels. While the overall matching score is slightly lower than with traditional methods, the network also outputs the confidence for a specific interest point resulting in a valid match. Most importantly, the approach completely gets rid of descriptors and thus enables localization systems with a significantly smaller memory footprint and multi-agent localization systems that require significantly less bandwidth. We evaluate performance relative to state-of-the-art alternatives.
SIPS: Unsupervised Succinct Interest Points
May 03, 2018


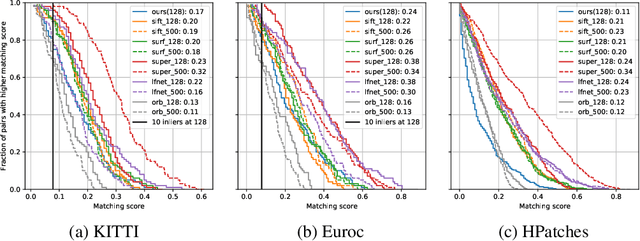
Detecting interest points is a key component of vision-based estimation algorithms, such as visual odometry or visual SLAM. Classically, interest point detection has been done with methods such as Harris, FAST, or DoG. Recently, better detectors have been proposed based on Neural Networks. Traditionally, interest point detectors have been designed to maximize repeatability or matching score. Instead, we pursue another metric, which we call succinctness. This metric captures the minimum amount of interest points that need to be extracted in order to achieve accurate relative pose estimation. Extracting a minimum amount of interest points is attractive for many applications, because it reduces computational load, memory, and, potentially, data transmission. We propose a novel reinforcement- and ranking-based training framework, which uses a full relative pose estimation pipeline during training. It can be trained in an unsupervised manner, without pose or 3D point ground truth. Using this training framework, we present a detector which outperforms previous interest point detectors in terms of succinctness on a variety of publicly available datasets.
Data-Efficient Decentralized Visual SLAM
Oct 16, 2017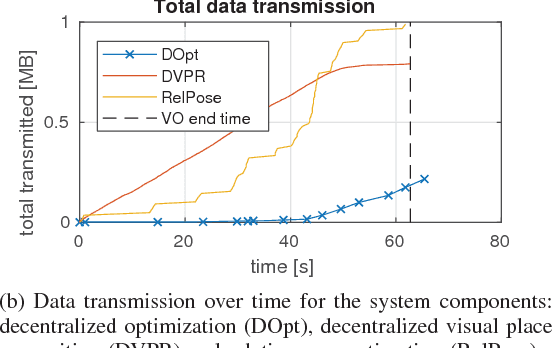
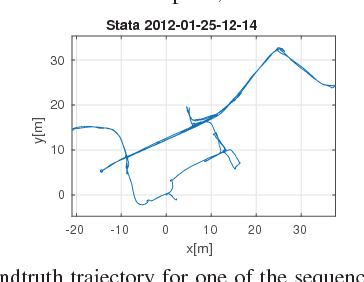
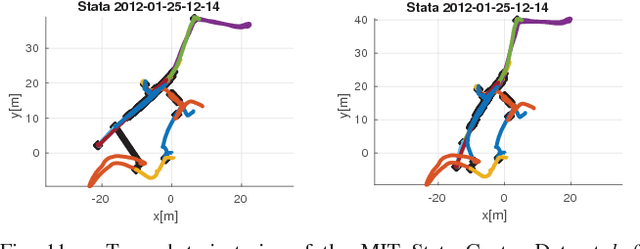
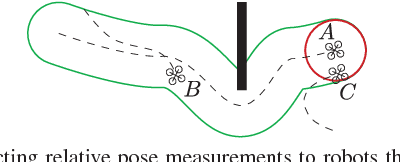
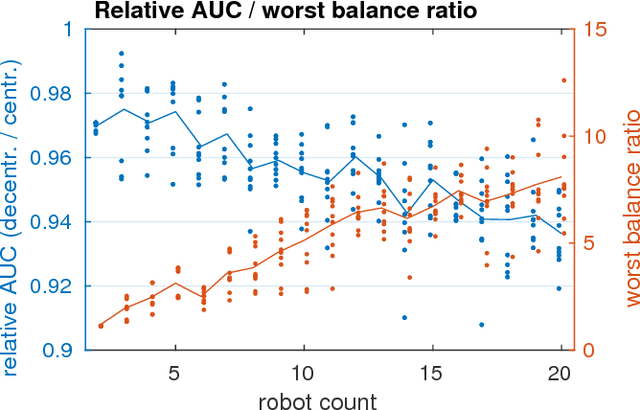
Decentralized visual simultaneous localization and mapping (SLAM) is a powerful tool for multi-robot applications in environments where absolute positioning systems are not available. Being visual, it relies on cameras, cheap, lightweight and versatile sensors, and being decentralized, it does not rely on communication to a central ground station. In this work, we integrate state-of-the-art decentralized SLAM components into a new, complete decentralized visual SLAM system. To allow for data association and co-optimization, existing decentralized visual SLAM systems regularly exchange the full map data between all robots, incurring large data transfers at a complexity that scales quadratically with the robot count. In contrast, our method performs efficient data association in two stages: in the first stage a compact full-image descriptor is deterministically sent to only one robot. In the second stage, which is only executed if the first stage succeeded, the data required for relative pose estimation is sent, again to only one robot. Thus, data association scales linearly with the robot count and uses highly compact place representations. For optimization, a state-of-the-art decentralized pose-graph optimization method is used. It exchanges a minimum amount of data which is linear with trajectory overlap. We characterize the resulting system and identify bottlenecks in its components. The system is evaluated on publicly available data and we provide open access to the code.
* 8 pages, submitted to ICRA 2018
Efficient Decentralized Visual Place Recognition From Full-Image Descriptors
May 30, 2017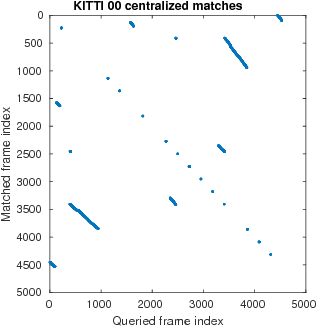

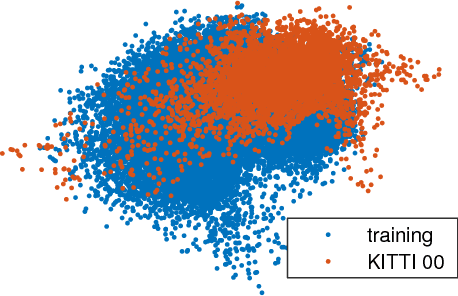
In this paper, we discuss the adaptation of our decentralized place recognition method described in [1] to full image descriptors. As we had shown, the key to making a scalable decentralized visual place recognition lies in exploting deterministic key assignment in a distributed key-value map. Through this, it is possible to reduce bandwidth by up to a factor of n, the robot count, by casting visual place recognition to a key-value lookup problem. In [1], we exploited this for the bag-of-words method [3], [4]. Our method of casting bag-of-words, however, results in a complex decentralized system, which has inherently worse recall than its centralized counterpart. In this paper, we instead start from the recent full-image description method NetVLAD [5]. As we show, casting this to a key-value lookup problem can be achieved with k-means clustering, and results in a much simpler system than [1]. The resulting system still has some flaws, albeit of a completely different nature: it suffers when the environment seen during deployment lies in a different distribution in feature space than the environment seen during training.
* 3 pages, 4 figures. This is a self-published paper that accompanies our original work [1] as well as the ICRA 2017 Workshop on Multi-robot Perception-Driven Control and Planning [2]