 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Features without Descriptors: Implicitly Matched Interest Points (IMIPs)
Paper and Code

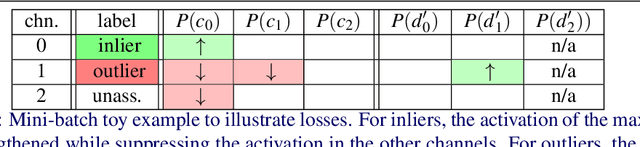
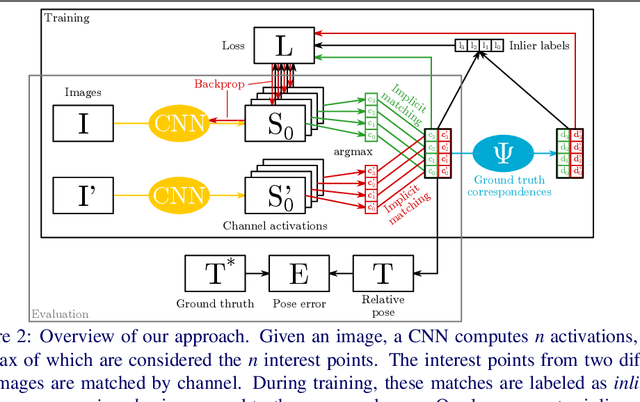
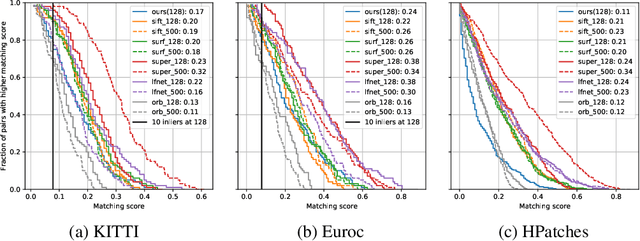
The extraction and matching of interest points is a prerequisite for visual pose estimation and related problems. Traditionally, matching has been achieved by assigning descriptors to interest points and matching points that have similar descriptors. In this paper, we propose a method by which interest points are instead already implicitly matched at detection time. Thanks to this, descriptors do not need to be calculated, stored, communicated, or matched any more. This is achieved by a convolutional neural network with multiple output channels. The i-th interest point is the location of the maximum of the i-th channel, and the i-th interest point in one image is implicitly matched with the i-th interest point in another image. This paper describes how to design and train such a network in a way that results in successful relative pose estimation performance with as little as 128 output channels. While the overall matching score is slightly lower than with traditional methods, the network also outputs the confidence for a specific interest point resulting in a valid match. Most importantly, the approach completely gets rid of descriptors and thus enables localization systems with a significantly smaller memory footprint and multi-agent localization systems that require significantly less bandwidth. We evaluate performance relative to state-of-the-art alternatives.