 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVEN: Multitask Retrieval Augmented Vision-Language Learning
Jun 27, 2024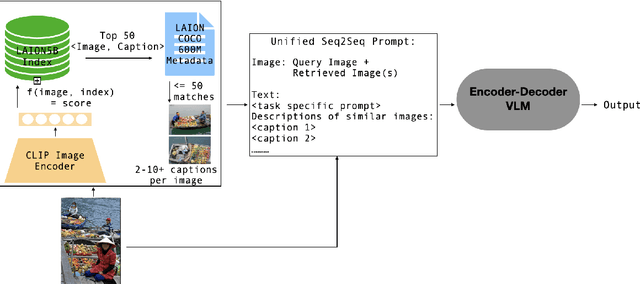
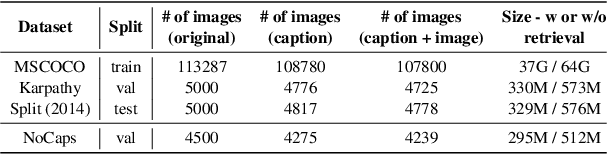
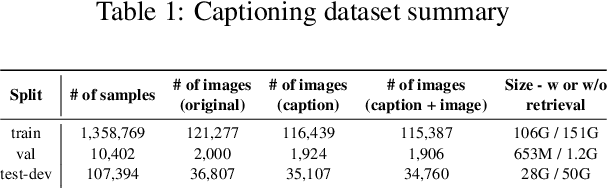

The scaling of large language models to encode all the world's knowledge in model parameters is unsustainable and has exacerbated resource barriers. Retrieval-Augmented Generation (RAG) presents a potential solution, yet its application to vision-language models (VLMs) is under explored. Existing methods focus on models designed for single tasks. Furthermore, they're limited by the need for resource intensive pre training, additional parameter requirements, unaddressed modality prioritization and lack of clear benefit over non-retrieval baselines. This paper introduces RAVEN, a multitask retrieval augmented VLM framework that enhances base VLMs through efficient, task specific fine-tuning. By integrating retrieval augmented samples without the need for additional retrieval-specific parameters, we show that the model acquires retrieval properties that are effective across multiple tasks. Our results and extensive ablations across retrieved modalities for the image captioning and VQA tasks indicate significant performance improvements compared to non retrieved baselines +1 CIDEr on MSCOCO, +4 CIDEr on NoCaps and nearly a +3\% accuracy on specific VQA question types. This underscores the efficacy of applying RAG approaches to VLMs, marking a stride toward more efficient and accessible multimodal learning.
Multi-Modal Hallucination Control by Visual Information Grounding
Mar 20, 2024



Generative Vision-Language Models (VLMs) are prone to generate plausible-sounding textual answers that, however, are not always grounded in the input image. We investigate this phenomenon, usually referred to as "hallucination" and show that it stems from an excessive reliance on the language prior. In particular, we show that as more tokens are generated, the reliance on the visual prompt decreases, and this behavior strongly correlates with the emergence of hallucinations. To reduce hallucinations, we introduce Multi-Modal Mutual-Information Decoding (M3ID), a new sampling method for prompt amplification. M3ID amplifies the influence of the reference image over the language prior, hence favoring the generation of tokens with higher mutual information with the visual prompt. M3ID can be applied to any pre-trained autoregressive VLM at inference time without necessitating further training and with minimal computational overhead. If training is an option, we show that M3ID can be paired with Direct Preference Optimization (DPO) to improve the model's reliance on the prompt image without requiring any labels. Our empirical findings show that our algorithms maintain the fluency and linguistic capabilities of pre-trained VLMs while reducing hallucinations by mitigating visually ungrounded answers. Specifically, for the LLaVA 13B model, M3ID and M3ID+DPO reduce the percentage of hallucinated objects in captioning tasks by 25% and 28%, respectively, and improve the accuracy on VQA benchmarks such as POPE by 21% and 24%.
SplatArmor: Articulated Gaussian splatting for animatable humans from monocular RGB videos
Nov 17, 2023



We propose SplatArmor, a novel approach for recovering detailed and animatable human models by `armoring' a parameterized body model with 3D Gaussians. Our approach represents the human as a set of 3D Gaussians within a canonical space, whose articulation is defined by extending the skinning of the underlying SMPL geometry to arbitrary locations in the canonical space. To account for pose-dependent effects, we introduce a SE(3) field, which allows us to capture both the location and anisotropy of the Gaussians. Furthermore, we propose the use of a neural color field to provide color regularization and 3D supervision for the precise positioning of these Gaussians. We show that Gaussian splatting provides an interesting alternative to neural rendering based methods by leverging a rasterization primitive without facing any of the non-differentiability and optimization challenges typically faced in such approaches. The rasterization paradigms allows us to leverage forward skinning, and does not suffer from the ambiguities associated with inverse skinning and warping. We show compelling results on the ZJU MoCap and People Snapshot datasets, which underscore the effectiveness of our method for controllable human synthesis.
Mesh Strikes Back: Fast and Efficient Human Reconstruction from RGB videos
Mar 15, 2023Human reconstruction and synthesis from monocular RGB videos is a challenging problem due to clothing, occlusion, texture discontinuities and sharpness, and framespecific pose changes. Many methods employ deferred rendering, NeRFs and implicit methods to represent clothed humans, on the premise that mesh-based representations cannot capture complex clothing and textures from RGB, silhouettes, and keypoints alone. We provide a counter viewpoint to this fundamental premise by optimizing a SMPL+D mesh and an efficient, multi-resolution texture representation using only RGB images, binary silhouettes and sparse 2D keypoints. Experimental results demonstrate that our approach is more capable of capturing geometric details compared to visual hull, mesh-based methods. We show competitive novel view synthesis and improvements in novel pose synthesis compared to NeRF-based methods, which introduce noticeable, unwanted artifacts. By restricting the solution space to the SMPL+D model combined with differentiable rendering, we obtain dramatic speedups in compute, training times (up to 24x) and inference times (up to 192x). Our method therefore can be used as is or as a fast initialization to NeRF-based methods.
Data-Efficient Decentralized Visual SLAM
Oct 16, 2017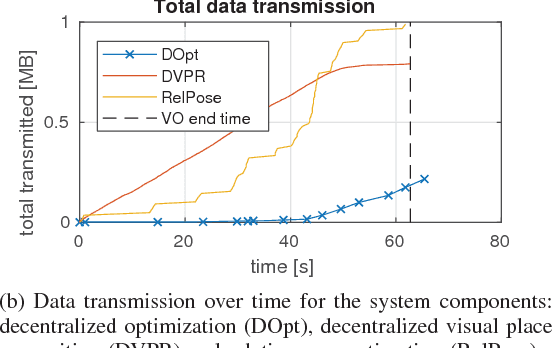
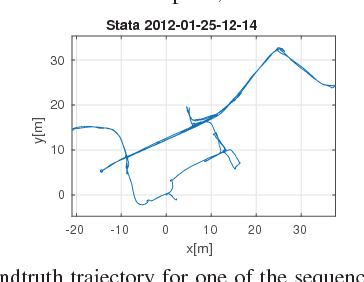
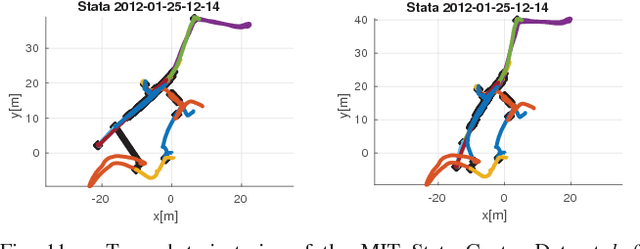
Decentralized visual simultaneous localization and mapping (SLAM) is a powerful tool for multi-robot applications in environments where absolute positioning systems are not available. Being visual, it relies on cameras, cheap, lightweight and versatile sensors, and being decentralized, it does not rely on communication to a central ground station. In this work, we integrate state-of-the-art decentralized SLAM components into a new, complete decentralized visual SLAM system. To allow for data association and co-optimization, existing decentralized visual SLAM systems regularly exchange the full map data between all robots, incurring large data transfers at a complexity that scales quadratically with the robot count. In contrast, our method performs efficient data association in two stages: in the first stage a compact full-image descriptor is deterministically sent to only one robot. In the second stage, which is only executed if the first stage succeeded, the data required for relative pose estimation is sent, again to only one robot. Thus, data association scales linearly with the robot count and uses highly compact place representations. For optimization, a state-of-the-art decentralized pose-graph optimization method is used. It exchanges a minimum amount of data which is linear with trajectory overlap. We characterize the resulting system and identify bottlenecks in its components. The system is evaluated on publicly available data and we provide open access to the code.
* 8 pages, submitted to ICRA 2018
Distributed Mapping with Privacy and Communication Constraints: Lightweight Algorithms and Object-based Models
Feb 11, 2017
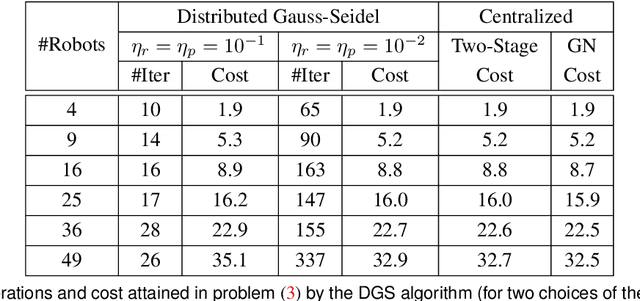
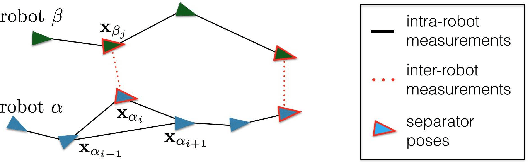
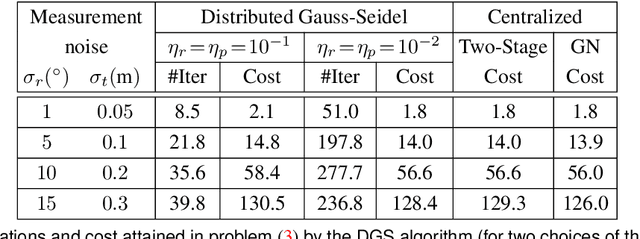
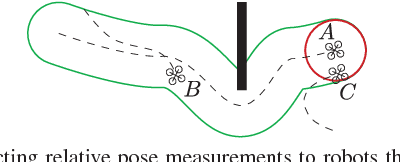
We consider the following problem: a team of robots is deployed in an unknown environment and it has to collaboratively build a map of the area without a reliable infrastructure for communication. The backbone for modern mapping techniques is pose graph optimization, which estimates the trajectory of the robots, from which the map can be easily built. The first contribution of this paper is a set of distributed algorithms for pose graph optimization: rather than sending all sensor data to a remote sensor fusion server, the robots exchange very partial and noisy information to reach an agreement on the pose graph configuration. Our approach can be considered as a distributed implementation of the two-stage approach of Carlone et al., where we use the Successive Over-Relaxation (SOR) and the Jacobi Over-Relaxation (JOR) as workhorses to split the computation among the robots. As a second contribution, we extend %and demonstrate the applicability of the proposed distributed algorithms to work with object-based map models. The use of object-based models avoids the exchange of raw sensor measurements (e.g., point clouds) further reducing the communication burden. Our third contribution is an extensive experimental evaluation of the proposed techniques, including tests in realistic Gazebo simulations and field experiments in a military test facility. Abundant experimental evidence suggests that one of the proposed algorithms (the Distributed Gauss-Seidel method or DGS) has excellent performance. The DGS requires minimal information exchange, has an anytime flavor, scales well to large teams, is robust to noise, and is easy to implement. Our field tests show that the combined use of our distributed algorithms and object-based models reduces the communication requirements by several orders of magnitude and enables distributed mapping with large teams of robots in real-world problems.