 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space
Jun 26, 2024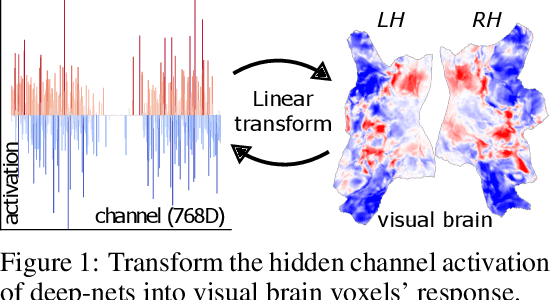
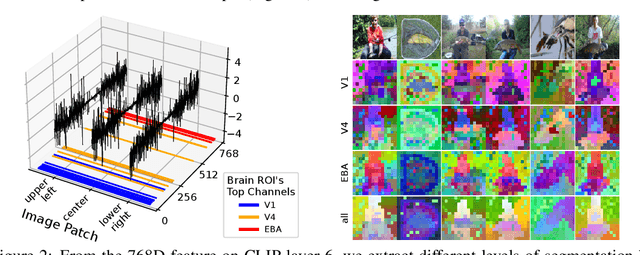

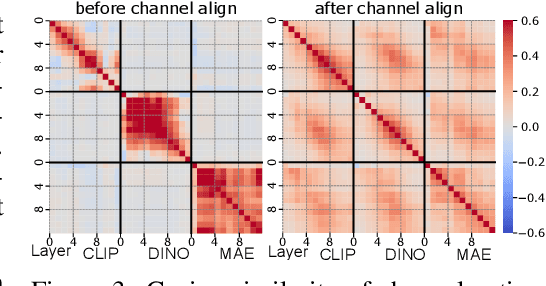
We study the intriguing connection between visual data, deep networks, and the brain. Our method creates a universal channel alignment by using brain voxel fMRI response prediction as the training objective. We discover that deep networks, trained with different objectives, share common feature channels across various models. These channels can be clustered into recurring sets, corresponding to distinct brain regions, indicating the formation of visual concepts. Tracing the clusters of channel responses onto the images, we see semantically meaningful object segments emerge, even without any supervised decoder. Furthermore, the universal feature alignment and the clustering of channels produce a picture and quantification of how visual information is processed through the different network layers, which produces precise comparisons between the networks.
Brain Decodes Deep Nets
Dec 03, 2023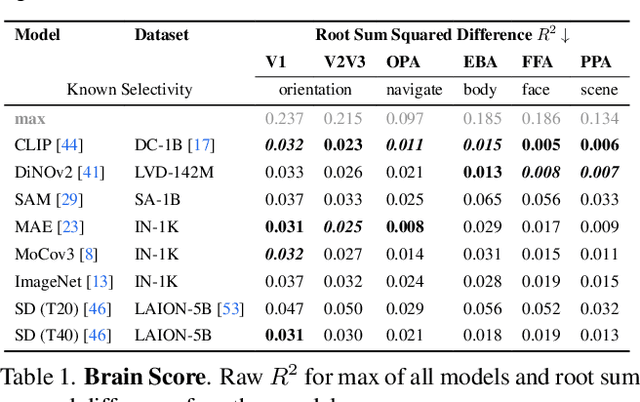
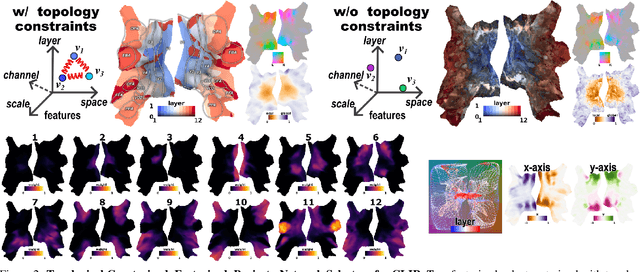

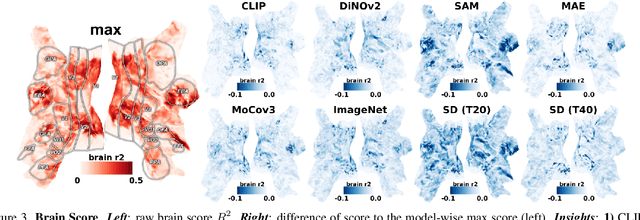
We developed a tool for visualizing and analyzing large pre-trained vision models by mapping them onto the brain, thus exposing their hidden inside. Our innovation arises from a surprising usage of brain encoding: predicting brain fMRI measurements in response to images. We report two findings. First, explicit mapping between the brain and deep-network features across dimensions of space, layers, scales, and channels is crucial. This mapping method, FactorTopy, is plug-and-play for any deep-network; with it, one can paint a picture of the network onto the brain (literally!). Second, our visualization shows how different training methods matter: they lead to remarkable differences in hierarchical organization and scaling behavior, growing with more data or network capacity. It also provides insight into finetuning: how pre-trained models change when adapting to small datasets. Our method is practical: only 3K images are enough to learn a network-to-brain mapping.
SplatArmor: Articulated Gaussian splatting for animatable humans from monocular RGB videos
Nov 17, 2023



We propose SplatArmor, a novel approach for recovering detailed and animatable human models by `armoring' a parameterized body model with 3D Gaussians. Our approach represents the human as a set of 3D Gaussians within a canonical space, whose articulation is defined by extending the skinning of the underlying SMPL geometry to arbitrary locations in the canonical space. To account for pose-dependent effects, we introduce a SE(3) field, which allows us to capture both the location and anisotropy of the Gaussians. Furthermore, we propose the use of a neural color field to provide color regularization and 3D supervision for the precise positioning of these Gaussians. We show that Gaussian splatting provides an interesting alternative to neural rendering based methods by leverging a rasterization primitive without facing any of the non-differentiability and optimization challenges typically faced in such approaches. The rasterization paradigms allows us to leverage forward skinning, and does not suffer from the ambiguities associated with inverse skinning and warping. We show compelling results on the ZJU MoCap and People Snapshot datasets, which underscore the effectiveness of our method for controllable human synthesis.
Memory Encoding Model
Aug 02, 2023



We explore a new class of brain encoding model by adding memory-related information as input. Memory is an essential brain mechanism that works alongside visual stimuli. During a vision-memory cognitive task, we found the non-visual brain is largely predictable using previously seen images. Our Memory Encoding Model (Mem) won the Algonauts 2023 visual brain competition even without model ensemble (single model score 66.8, ensemble score 70.8). Our ensemble model without memory input (61.4) can also stand a 3rd place. Furthermore, we observe periodic delayed brain response correlated to 6th-7th prior image, and hippocampus also showed correlated activity timed with this periodicity. We conjuncture that the periodic replay could be related to memory mechanism to enhance the working memory.
Retinotopy Inspired Brain Encoding Model and the All-for-One Training Recipe
Jul 26, 2023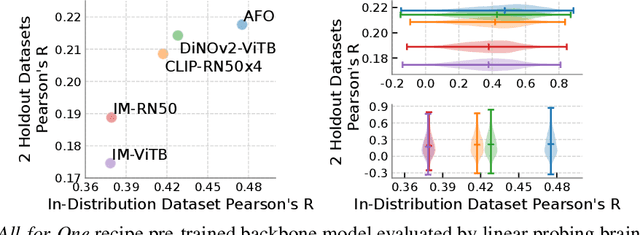
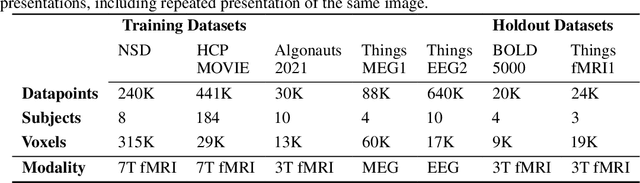
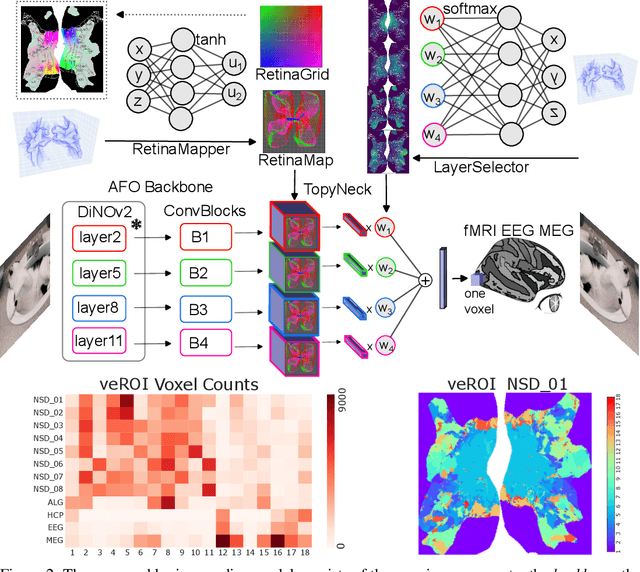
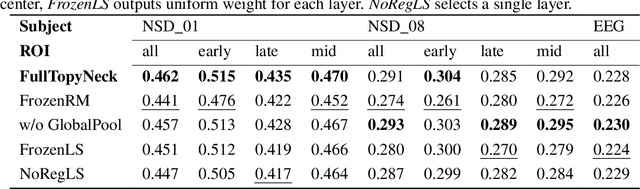
Brain encoding models aim to predict brain voxel-wise responses to stimuli images, replicating brain signals captured by neuroimaging techniques. There is a large volume of publicly available data, but training a comprehensive brain encoding model is challenging. The main difficulties stem from a) diversity within individual brain, with functional heterogeneous brain regions; b) diversity of brains from different subjects, due to genetic and developmental differences; c) diversity of imaging modalities and processing pipelines. We use this diversity to our advantage by introducing the All-for-One training recipe, which divides the challenging one-big-model problem into multiple small models, with the small models aggregating the knowledge while preserving the distinction between the different functional regions. Agnostic of the training recipe, we use biological knowledge of the brain, specifically retinotopy, to introduce inductive bias to learn a 3D brain-to-image mapping that ensures a) each neuron knows which image regions and semantic levels to gather information, and b) no neurons are left behind in the model. We pre-trained a brain encoding model using over one million data points from five public datasets spanning three imaging modalities. To the best of our knowledge, this is the most comprehensive brain encoding model to the date. We demonstrate the effectiveness of the pre-trained model as a drop-in replacement for commonly used vision backbone models. Furthermore, we demonstrate the application of the model to brain decoding. Code and the model checkpoint will be made available.
Mesh Strikes Back: Fast and Efficient Human Reconstruction from RGB videos
Mar 15, 2023Human reconstruction and synthesis from monocular RGB videos is a challenging problem due to clothing, occlusion, texture discontinuities and sharpness, and framespecific pose changes. Many methods employ deferred rendering, NeRFs and implicit methods to represent clothed humans, on the premise that mesh-based representations cannot capture complex clothing and textures from RGB, silhouettes, and keypoints alone. We provide a counter viewpoint to this fundamental premise by optimizing a SMPL+D mesh and an efficient, multi-resolution texture representation using only RGB images, binary silhouettes and sparse 2D keypoints. Experimental results demonstrate that our approach is more capable of capturing geometric details compared to visual hull, mesh-based methods. We show competitive novel view synthesis and improvements in novel pose synthesis compared to NeRF-based methods, which introduce noticeable, unwanted artifacts. By restricting the solution space to the SMPL+D model combined with differentiable rendering, we obtain dramatic speedups in compute, training times (up to 24x) and inference times (up to 192x). Our method therefore can be used as is or as a fast initialization to NeRF-based methods.
Learning-Based Radiomic Prediction of Type 2 Diabetes Mellitus Using Image-Derived Phenotypes
Sep 20, 2022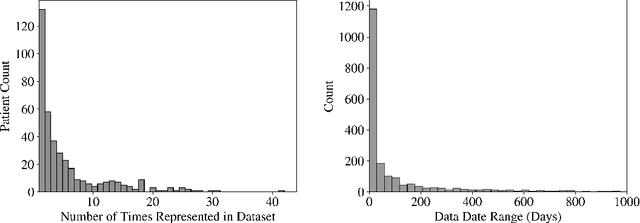

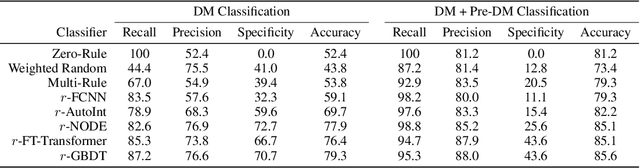
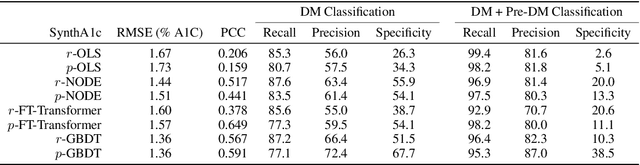
Early diagnosis of Type 2 Diabetes Mellitus (T2DM) is crucial to enable timely therapeutic interventions and lifestyle modifications. As medical imaging data become more widely available for many patient populations, we sought to investigate whether image-derived phenotypic data could be leveraged in tabular learning classifier models to predict T2DM incidence without the use of invasive blood lab measurements. We show that both neural network and decision tree models that use image-derived phenotypes can predict patient T2DM status with recall scores as high as 87.6%. We also propose the novel use of these same architectures as 'SynthA1c encoders' that are able to output interpretable values mimicking blood hemoglobin A1C empirical lab measurements. Finally, we demonstrate that T2DM risk prediction model sensitivity to small perturbations in input vector components can be used to predict performance on covariates sampled from previously unseen patient populations.
Beyond mAP: Re-evaluating and Improving Performance in Instance Segmentation with Semantic Sorting and Contrastive Flow
Jul 04, 2022
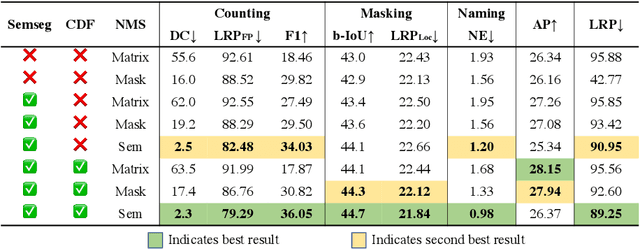
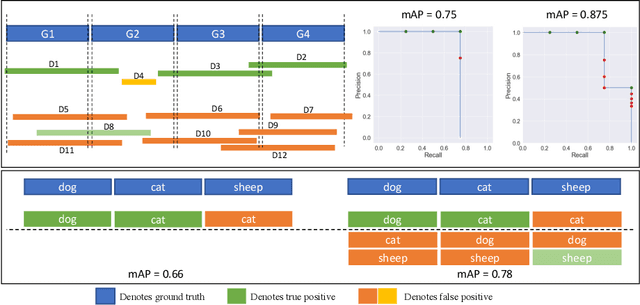

Top-down instance segmentation methods improve mAP by hedging bets on low-confidence predictions to match a ground truth. Moreover, the query-key paradigm of top-down methods leads to the instance merging problem. An excessive number of duplicate predictions leads to the (over)counting error, and the independence of category and localization branches leads to the naming error. The de-facto mAP metric doesn't capture these errors, as we show that a trivial dithering scheme can simultaneously increase mAP with hedging errors. To this end, we propose two graph-based metrics that quantifies the amount of hedging both inter-and intra-class. We conjecture the source of the hedging problem is due to feature merging and propose a) Contrastive Flow Field to encode contextual differences between instances as a supervisory signal, and b) Semantic Sorting and NMS step to suppress duplicates and incorrectly categorized prediction. Ablations show that our method encodes contextual information better than baselines, and experiments on COCO our method simultaneously reduces merging and hedging errors compared to state-of-the-art instance segmentation methods.
Enhanced generative adversarial network for 3D brain MRI super-resolution
Jul 15, 2019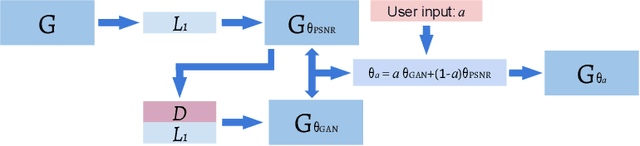
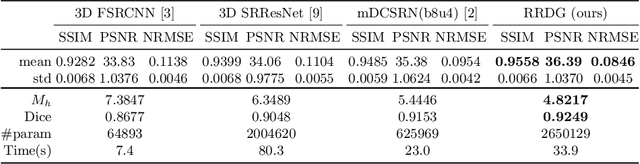
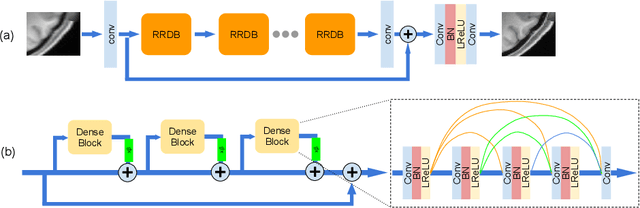

Single image super-resolution (SISR) reconstruction for magnetic resonance imaging (MRI) has generated significant interest because of its potential to not only speed up imaging but to improve quantitative processing and analysis of available image data. Generative Adversarial Networks (GAN) have proven to perform well in recovering image texture detail, and many variants have therefore been proposed for SISR. In this work, we develop an enhancement to tackle GAN-based 3D SISR by introducing a new residual-in-residual dense block (RRDG) generator that is both memory efficient and achieves state-of-the-art performance in terms of PSNR (Peak Signal to Noise Ratio), SSIM (Structural Similarity) and NRMSE (Normalized Root Mean Squared Error) metrics. We also introduce a patch GAN discriminator with improved convergence behavior to better model brain image texture. We proposed a novel the anatomical fidelity evaluation of the results using a pre-trained brain parcellation network. Finally, these developments are combined through a simple and efficient method to balance etween image and texture quality in the final output.
Barnes-Hut Approximation for Point SetGeodesic Shooting
Jul 10, 2019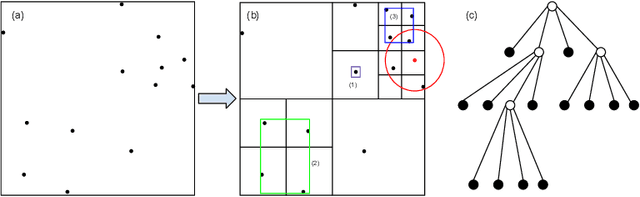

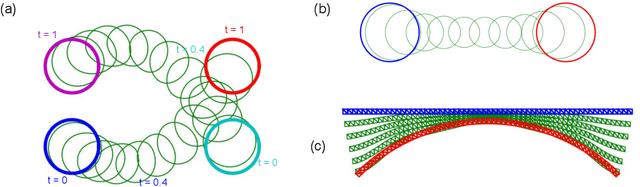

Geodesic shooting has been successfully applied to diffeo-morphic registration of point sets. Exact computation of the geodesicshooting between point sets, however, requiresO(N2) calculations each time step on the number of points in the point set. We proposean approximation approach based on the Barnes-Hut algorithm to speedup point set geodesic shooting. This approximation can reduce the al-gorithm complexity toO(N b+N logN). The evaluation of the proposedmethod in both simulated images and the medial temporal lobe thick-ness analysis demonstrates a comparable accuracy to the exact point set geodesic shooting while offering up to 3-fold speed up. This improvementopens up a range of clinical research studies and practical problems towhich the method can be effectively applied.