 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond mAP: Re-evaluating and Improving Performance in Instance Segmentation with Semantic Sorting and Contrastive Flow
Jul 04, 2022
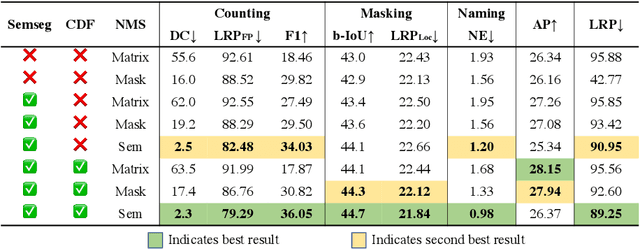
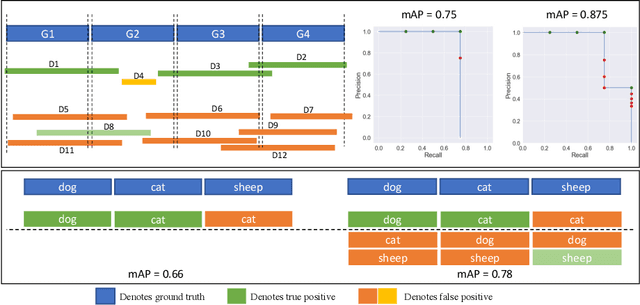

Top-down instance segmentation methods improve mAP by hedging bets on low-confidence predictions to match a ground truth. Moreover, the query-key paradigm of top-down methods leads to the instance merging problem. An excessive number of duplicate predictions leads to the (over)counting error, and the independence of category and localization branches leads to the naming error. The de-facto mAP metric doesn't capture these errors, as we show that a trivial dithering scheme can simultaneously increase mAP with hedging errors. To this end, we propose two graph-based metrics that quantifies the amount of hedging both inter-and intra-class. We conjecture the source of the hedging problem is due to feature merging and propose a) Contrastive Flow Field to encode contextual differences between instances as a supervisory signal, and b) Semantic Sorting and NMS step to suppress duplicates and incorrectly categorized prediction. Ablations show that our method encodes contextual information better than baselines, and experiments on COCO our method simultaneously reduces merging and hedging errors compared to state-of-the-art instance segmentation methods.
An Improved Learning Framework for Covariant Local Feature Detection
Nov 01, 2018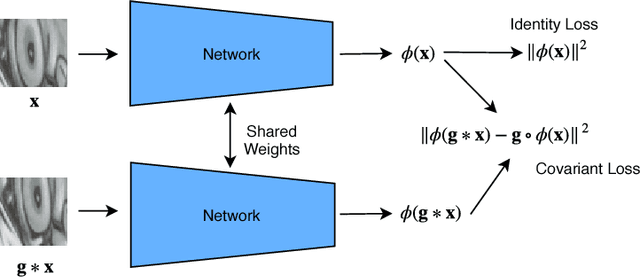
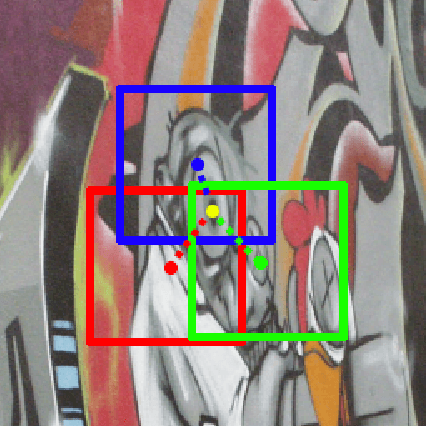
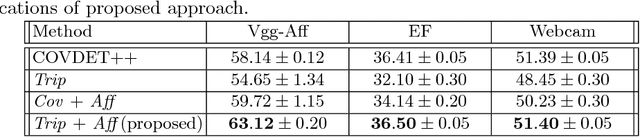

Learning feature detection has been largely an unexplored area when compared to handcrafted feature detection. Recent learning formulations use the covariant constraint in their loss function to learn covariant detectors. However, just learning from covariant constraint can lead to detection of unstable features. To impart further, stability detectors are trained to extract pre-determined features obtained by hand-crafted detectors. However, in the process they lose the ability to detect novel features. In an attempt to overcome the above limitations, we propose an improved scheme by incorporating covariant constraints in form of triplets with addition to an affine covariant constraint. We show that using these additional constraints one can learn to detect novel and stable features without using pre-determined features for training. Extensive experiments show our model achieves state-of-the-art performance in repeatability score on the well known datasets such as Vgg-Affine, EF, and Webcam.
* 15 pages
A Large Dataset for Improving Patch Matching
Apr 17, 2018
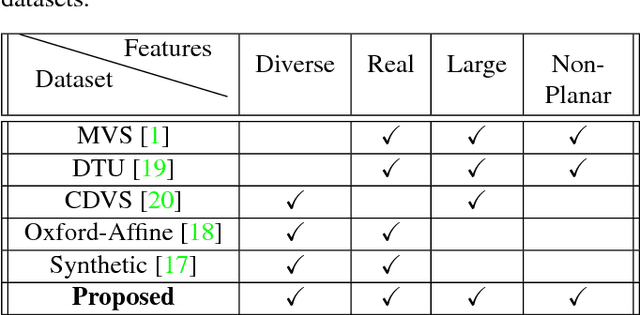

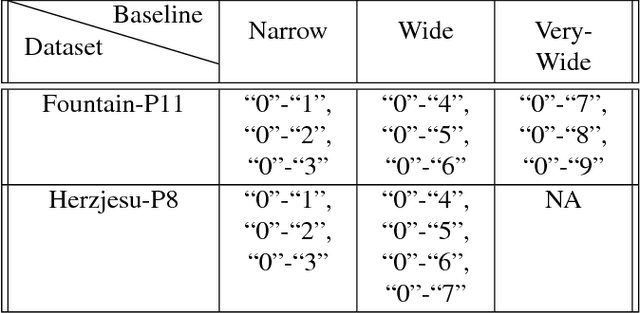
We propose a new dataset for learning local image descriptors which can be used for significantly improved patch matching. Our proposed dataset consists of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) dataset from Brown et al. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. Our dataset also provides supplementary information like RGB patches with scale and rotations values, and intrinsic and extrinsic camera parameters which as shown later can be used to customize training data as per application. We train an existing state-of-the-art model on our dataset and evaluate on publicly available benchmarks such as HPatches dataset and Strecha et al.\cite{strecha} to quantify the image descriptor performance. Experimental evaluations show that the descriptors trained using our proposed dataset outperform the current state-of-the-art descriptors trained on MVS by 8%, 4% and 10% on matching, verification and retrieval tasks respectively on the HPatches dataset. Similarly on the Strecha dataset, we see an improvement of 3-5% for the matching task in non-planar scenes.