 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Dataset for Improving Patch Matching
Apr 17, 2018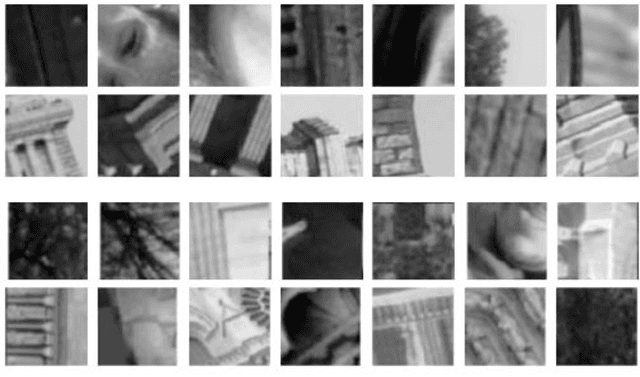
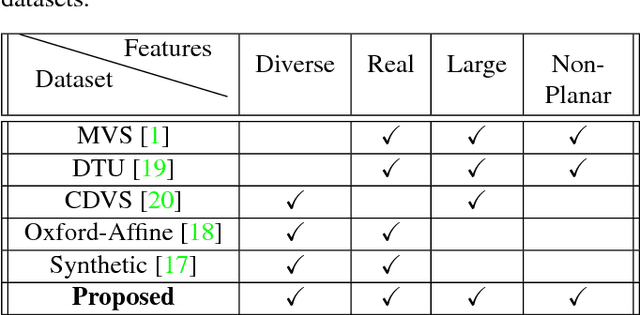

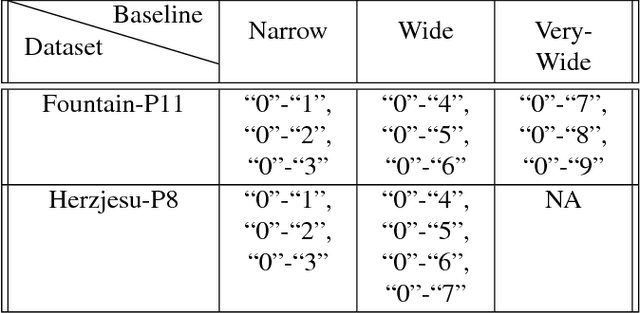
We propose a new dataset for learning local image descriptors which can be used for significantly improved patch matching. Our proposed dataset consists of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) dataset from Brown et al. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. Our dataset also provides supplementary information like RGB patches with scale and rotations values, and intrinsic and extrinsic camera parameters which as shown later can be used to customize training data as per application. We train an existing state-of-the-art model on our dataset and evaluate on publicly available benchmarks such as HPatches dataset and Strecha et al.\cite{strecha} to quantify the image descriptor performance. Experimental evaluations show that the descriptors trained using our proposed dataset outperform the current state-of-the-art descriptors trained on MVS by 8%, 4% and 10% on matching, verification and retrieval tasks respectively on the HPatches dataset. Similarly on the Strecha dataset, we see an improvement of 3-5% for the matching task in non-planar scenes.