 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan viewer proximity be a behavioural marker for Autism Spectrum Disorder?
Nov 23, 2021
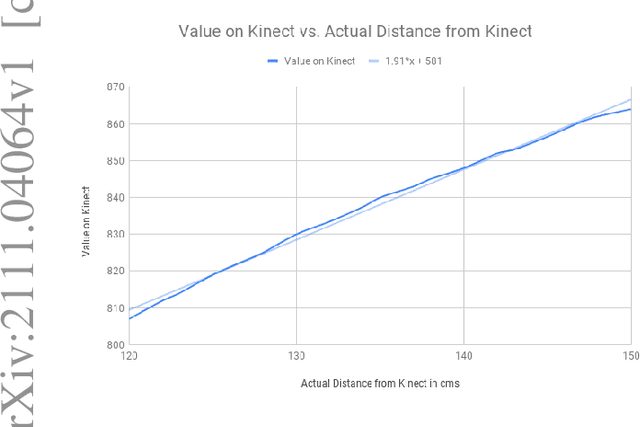


Screening for any of the Autism Spectrum Disorders is a complicated process often involving a hybrid of behavioural observations and questionnaire based tests. Typically carried out in a controlled setting, this process requires trained clinicians or psychiatrists for such assessments. Riding on the wave of technical advancement in mobile platforms, several attempts have been made at incorporating such assessments on mobile and tablet devices. In this paper we analyse videos generated using one such screening test. This paper reports the first use of the efficacy of using the observer's distance from the display screen while administering a sensory sensitivity test as a behavioural marker for autism for children aged 2-7 years The potential for using a test such as this in casual home settings is promising.
Low radiation tomographic reconstruction with and without template information
Dec 23, 2019



Low-dose tomography is highly preferred in medical procedures for its reduced radiation risk when compared to standard-dose Computed Tomography (CT). However, the lower the intensity of X-rays, the higher the acquisition noise and hence the reconstructions suffer from artefacts. A large body of work has focussed on improving the algorithms to minimize these artefacts. In this work, we propose two new techniques, rescaled non-linear least squares and Poisson-Gaussian convolution, that reconstruct the underlying image making use of an accurate or near-accurate statistical model of the noise in the projections. We also propose a reconstruction method when prior knowledge of the underlying object is available in the form of templates. This is applicable to longitudinal studies wherein the same object is scanned multiple times to observe the changes that evolve in it over time. Our results on 3D data show that prior information can be used to compensate for the low-dose artefacts, and we demonstrate that it is possible to simultaneously prevent the prior from adversely biasing the reconstructions of new changes in the test object, via a method called ``re-irradiation''. Additionally, we also present two techniques for automated tuning of the regularization parameters for tomographic inversion.
Tomographic reconstruction to detect evolving structures
Sep 11, 2019

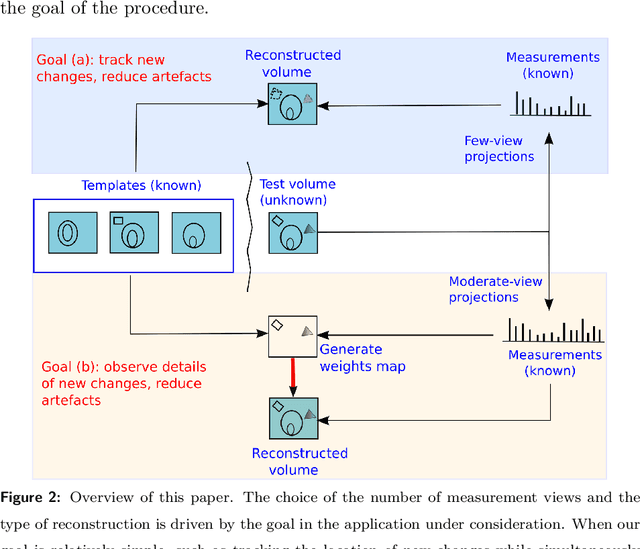

The need for tomographic reconstruction from sparse measurements arises when the measurement process is potentially harmful, needs to be rapid, or is uneconomical. In such cases, information from previous longitudinal scans of the same object helps to reconstruct the current object while requiring significantly fewer updating measurements. Our work is based on longitudinal data acquisition scenarios where we wish to study new changes that evolve within an object over time, such as in repeated scanning for disease monitoring, or in tomography-guided surgical procedures. While this is easily feasible when measurements are acquired from a large number of projection views, it is challenging when the number of views is limited. If the goal is to track the changes while simultaneously reducing sub-sampling artefacts, we propose (1) acquiring measurements from a small number of views and using a global unweighted prior-based reconstruction. If the goal is to observe details of new changes, we propose (2) acquiring measurements from a moderate number of views and using a more involved reconstruction routine. We show that in the latter case, a weighted technique is necessary in order to prevent the prior from adversely affecting the reconstruction of new structures that are absent in any of the earlier scans. The reconstruction of new regions is safeguarded from the bias of the prior by computing regional weights that moderate the local influence of the priors. We are thus able to effectively reconstruct both the old and the new structures in the test. In addition to testing on simulated data, we have validated the efficacy of our method on real tomographic data. The results demonstrate the use of both unweighted and weighted priors in different scenarios.
Learning from past scans: Tomographic reconstruction to detect new structures
Dec 23, 2018
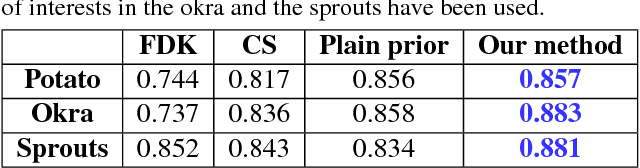

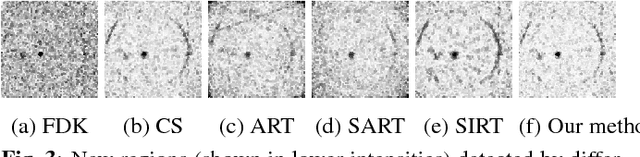
The need for tomographic reconstruction from sparse measurements arises when the measurement process is potentially harmful, needs to be rapid, or is uneconomical. In such cases, prior information from previous longitudinal scans of the same or similar objects helps to reconstruct the current object whilst requiring significantly fewer `updating' measurements. However, a significant limitation of all prior-based methods is the possible dominance of the prior over the reconstruction of new localised information that has evolved within the test object. In this paper, we improve the state of the art by (1) detecting potential regions where new changes may have occurred, and (2) effectively reconstructing both the old and new structures by computing regional weights that moderate the local influence of the priors. We have tested the efficacy of our method on synthetic as well as real volume data. The results demonstrate that using weighted priors significantly improves the overall quality of the reconstructed data whilst minimising their impact on regions that contain new information.
A Large Dataset for Improving Patch Matching
Apr 17, 2018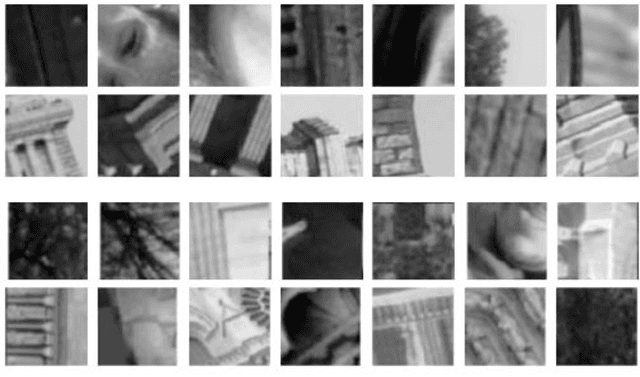
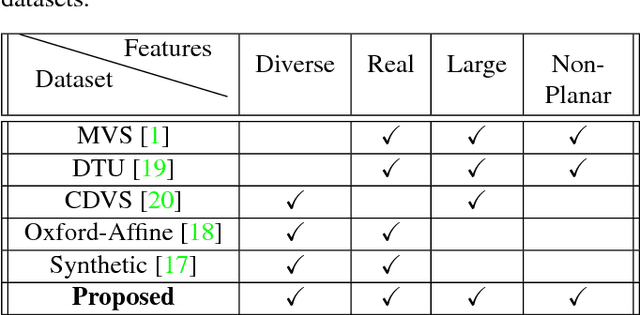

We propose a new dataset for learning local image descriptors which can be used for significantly improved patch matching. Our proposed dataset consists of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) dataset from Brown et al. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. Our dataset also provides supplementary information like RGB patches with scale and rotations values, and intrinsic and extrinsic camera parameters which as shown later can be used to customize training data as per application. We train an existing state-of-the-art model on our dataset and evaluate on publicly available benchmarks such as HPatches dataset and Strecha et al.\cite{strecha} to quantify the image descriptor performance. Experimental evaluations show that the descriptors trained using our proposed dataset outperform the current state-of-the-art descriptors trained on MVS by 8%, 4% and 10% on matching, verification and retrieval tasks respectively on the HPatches dataset. Similarly on the Strecha dataset, we see an improvement of 3-5% for the matching task in non-planar scenes.
Tomographic Reconstruction using Global Statistical Prior
Dec 06, 2017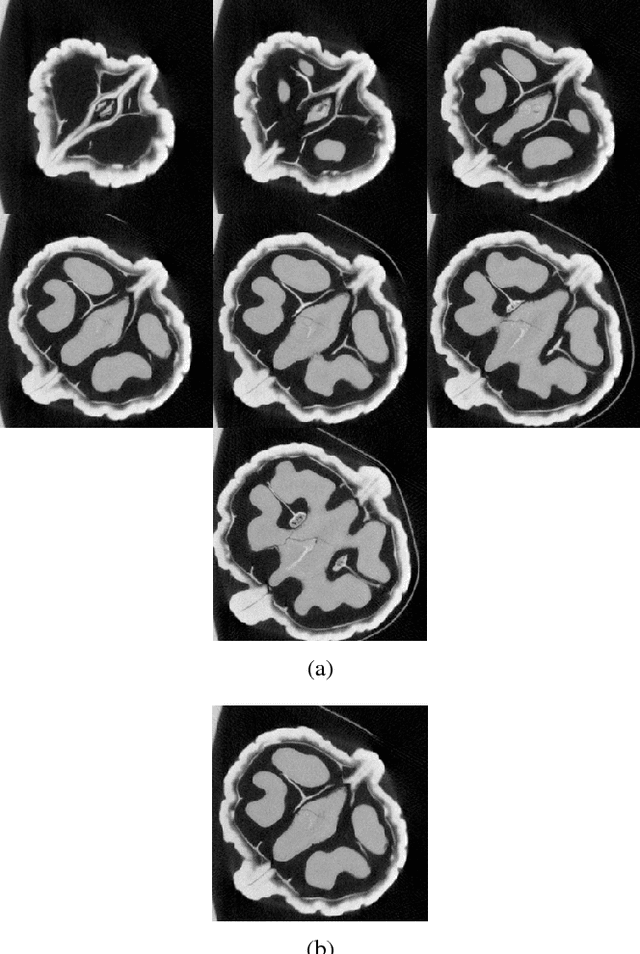



Recent research in tomographic reconstruction is motivated by the need to efficiently recover detailed anatomy from limited measurements. One of the ways to compensate for the increasingly sparse sets of measurements is to exploit the information from templates, i.e., prior data available in the form of already reconstructed, structurally similar images. Towards this, previous work has exploited using a set of global and patch based dictionary priors. In this paper, we propose a global prior to improve both the speed and quality of tomographic reconstruction within a Compressive Sensing framework. We choose a set of potential representative 2D images referred to as templates, to build an eigenspace; this is subsequently used to guide the iterative reconstruction of a similar slice from sparse acquisition data. Our experiments across a diverse range of datasets show that reconstruction using an appropriate global prior, apart from being faster, gives a much lower reconstruction error when compared to the state of the art.
Improved Descriptors for Patch Matching and Reconstruction
Aug 27, 2017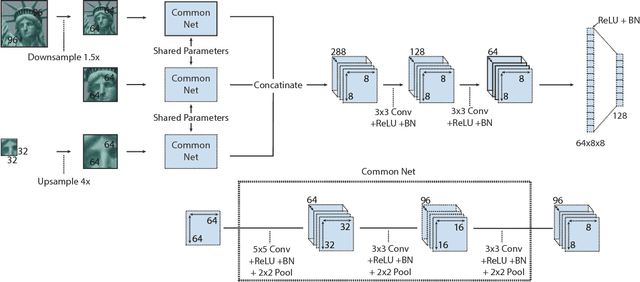
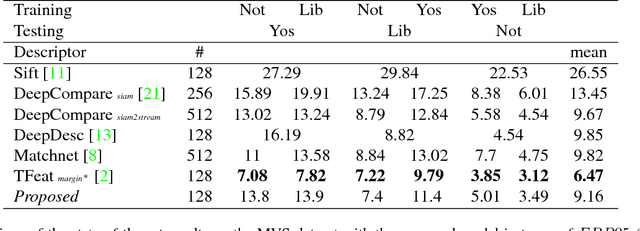
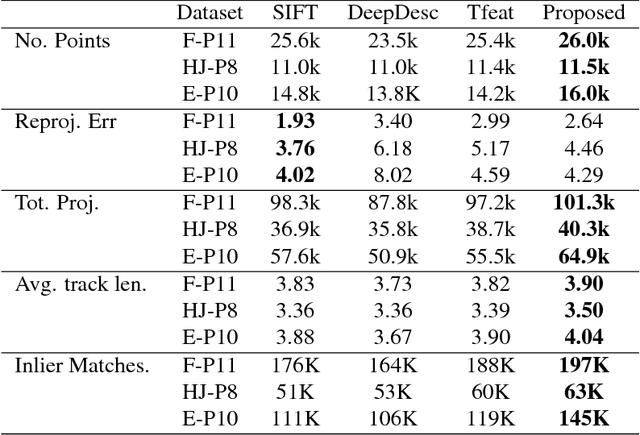
We propose a convolutional neural network (ConvNet) based approach for learning local image descriptors which can be used for significantly improved patch matching and 3D reconstructions. A multi-resolution ConvNet is used for learning keypoint descriptors. We also propose a new dataset consisting of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) [18] dataset. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. We evaluate our approach on publicly available datasets, such as Oxford Affine Covariant Regions Dataset (ACRD) [12], MVS [18], Synthetic [6] and Strecha [15] datasets to quantify the image descriptor performance. Scenes from the Oxford ACRD, MVS and Synthetic datasets are used for evaluating the patch matching performance of the learnt descriptors while the Strecha dataset is used to evaluate the 3D reconstruction task. Experiments show that the proposed descriptor outperforms the current state-of-the-art descriptors in both the evaluation tasks.