 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Multi-Person 3D Human Pose Estimation from Monocular Images
Sep 24, 2019
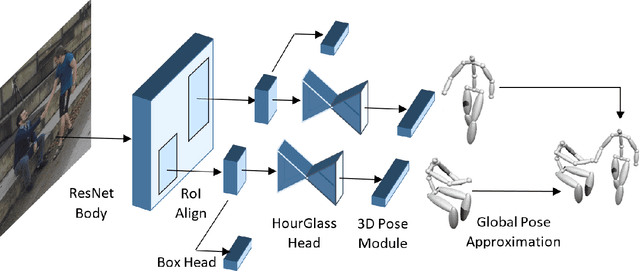

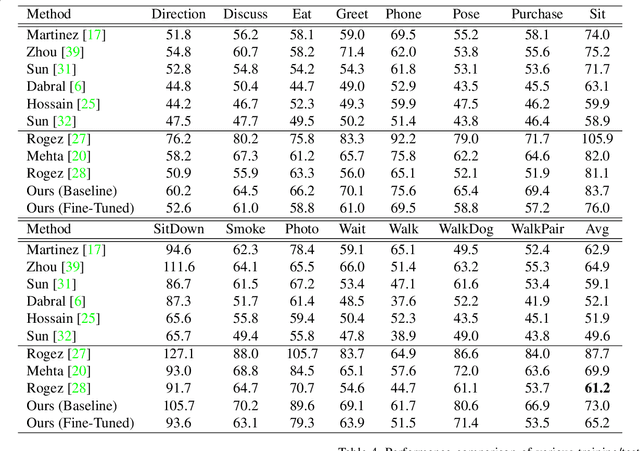
Multi-person 3D human pose estimation from a single image is a challenging problem, especially for in-the-wild settings due to the lack of 3D annotated data. We propose HG-RCNN, a Mask-RCNN based network that also leverages the benefits of the Hourglass architecture for multi-person 3D Human Pose Estimation. A two-staged approach is presented that first estimates the 2D keypoints in every Region of Interest (RoI) and then lifts the estimated keypoints to 3D. Finally, the estimated 3D poses are placed in camera-coordinates using weak-perspective projection assumption and joint optimization of focal length and root translations. The result is a simple and modular network for multi-person 3D human pose estimation that does not require any multi-person 3D pose dataset. Despite its simple formulation, HG-RCNN achieves the state-of-the-art results on MuPoTS-3D while also approximating the 3D pose in the camera-coordinate system.
ProtoGAN: Towards Few Shot Learning for Action Recognition
Sep 17, 2019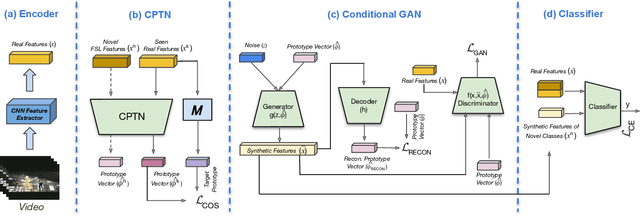
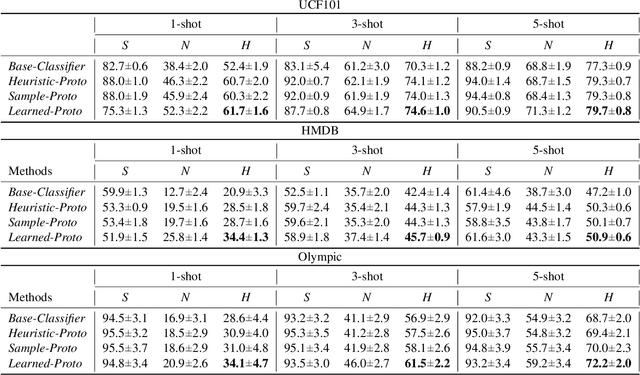
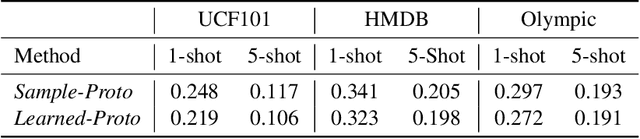
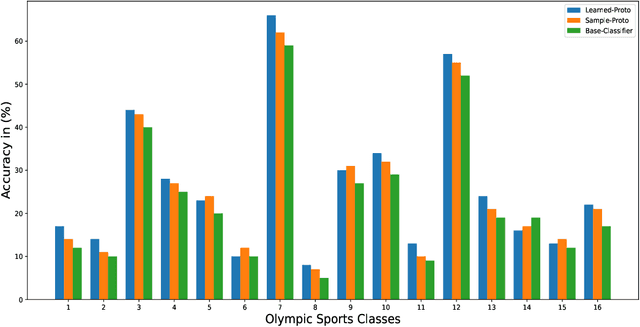
Few-shot learning (FSL) for action recognition is a challenging task of recognizing novel action categories which are represented by few instances in the training data. In a more generalized FSL setting (G-FSL), both seen as well as novel action categories need to be recognized. Conventional classifiers suffer due to inadequate data in FSL setting and inherent bias towards seen action categories in G-FSL setting. In this paper, we address this problem by proposing a novel ProtoGAN framework which synthesizes additional examples for novel categories by conditioning a conditional generative adversarial network with class prototype vectors. These class prototype vectors are learnt using a Class Prototype Transfer Network (CPTN) from examples of seen categories. Our synthesized examples for a novel class are semantically similar to real examples belonging to that class and is used to train a model exhibiting better generalization towards novel classes. We support our claim by performing extensive experiments on three datasets: UCF101, HMDB51 and Olympic-Sports. To the best of our knowledge, we are the first to report the results for G-FSL and provide a strong benchmark for future research. We also outperform the state-of-the-art method in FSL for all the aforementioned datasets.
3D Human Pose Estimation under limited supervision using Metric Learning
Aug 14, 2019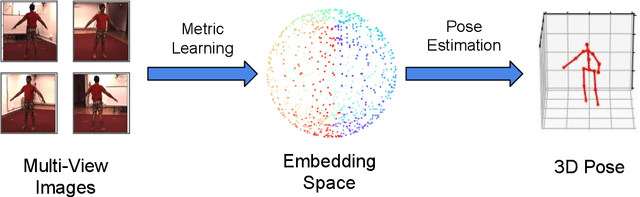
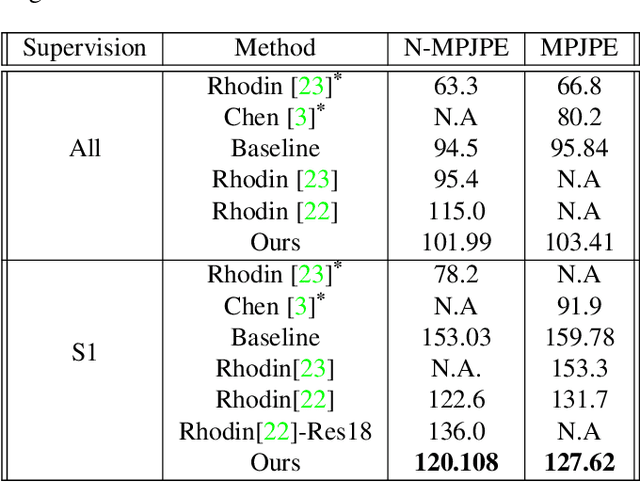
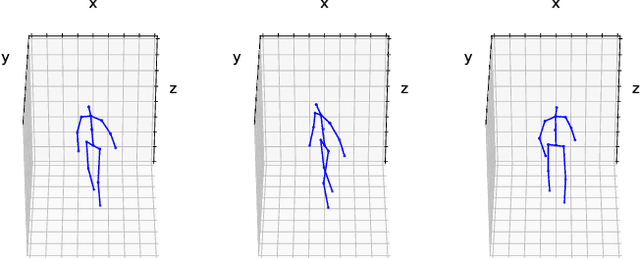

Estimating 3D human pose from monocular images demands large amounts of 3D pose and in-the-wild 2D pose annotated datasets which are costly and require sophisticated systems to acquire. In this regard, we propose a metric learning based approach to jointly learn a rich embedding and 3D pose regression from the embedding using multi-view synchronised videos of human motions and very limited 3D pose annotations. The inclusion of metric learning to the baseline pose estimation framework improves the performance by 21\% when 3D supervision is limited. In addition, we make use of a person-identity based adversarial loss as additional weak supervision to outperform state-of-the-art whilst using a much smaller network. Lastly, but importantly, we demonstrate the advantages of the learned embedding and establish view-invariant pose retrieval benchmarks on two popular, publicly available multi-view human pose datasets, Human 3.6M and MPI-INF-3DHP, to facilitate future research.
An Improved Learning Framework for Covariant Local Feature Detection
Nov 01, 2018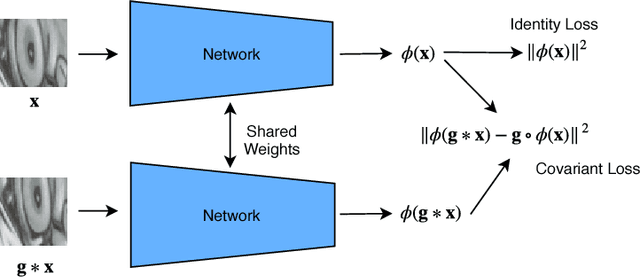
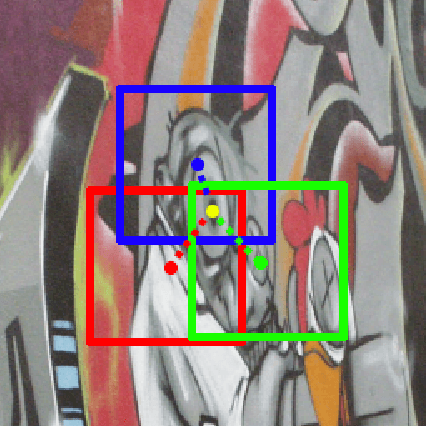
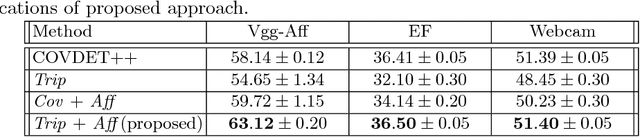

Learning feature detection has been largely an unexplored area when compared to handcrafted feature detection. Recent learning formulations use the covariant constraint in their loss function to learn covariant detectors. However, just learning from covariant constraint can lead to detection of unstable features. To impart further, stability detectors are trained to extract pre-determined features obtained by hand-crafted detectors. However, in the process they lose the ability to detect novel features. In an attempt to overcome the above limitations, we propose an improved scheme by incorporating covariant constraints in form of triplets with addition to an affine covariant constraint. We show that using these additional constraints one can learn to detect novel and stable features without using pre-determined features for training. Extensive experiments show our model achieves state-of-the-art performance in repeatability score on the well known datasets such as Vgg-Affine, EF, and Webcam.
* 15 pages
A Large Dataset for Improving Patch Matching
Apr 17, 2018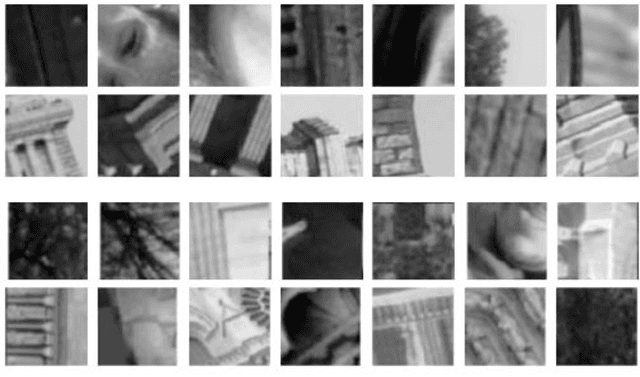
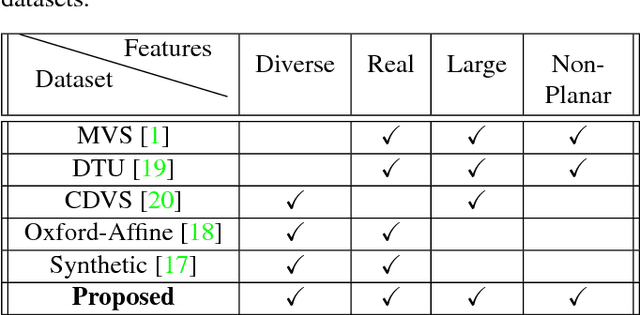

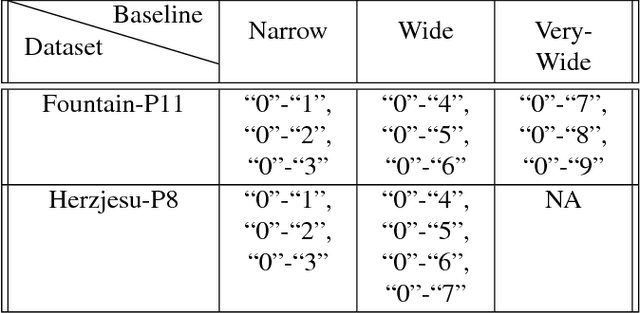
We propose a new dataset for learning local image descriptors which can be used for significantly improved patch matching. Our proposed dataset consists of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) dataset from Brown et al. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. Our dataset also provides supplementary information like RGB patches with scale and rotations values, and intrinsic and extrinsic camera parameters which as shown later can be used to customize training data as per application. We train an existing state-of-the-art model on our dataset and evaluate on publicly available benchmarks such as HPatches dataset and Strecha et al.\cite{strecha} to quantify the image descriptor performance. Experimental evaluations show that the descriptors trained using our proposed dataset outperform the current state-of-the-art descriptors trained on MVS by 8%, 4% and 10% on matching, verification and retrieval tasks respectively on the HPatches dataset. Similarly on the Strecha dataset, we see an improvement of 3-5% for the matching task in non-planar scenes.
Improved Descriptors for Patch Matching and Reconstruction
Aug 27, 2017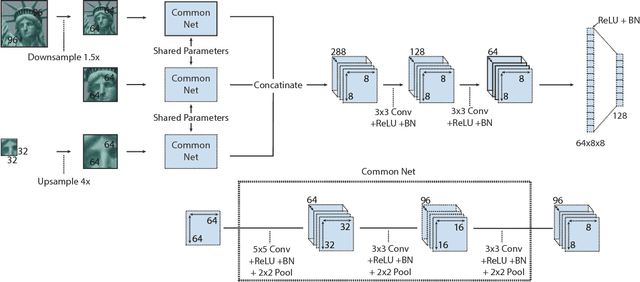
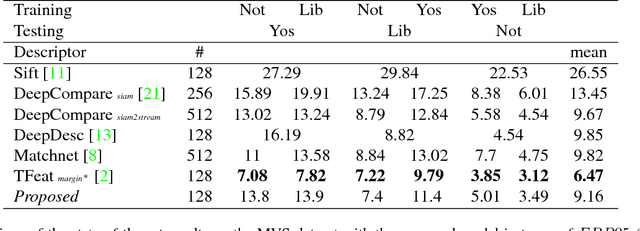
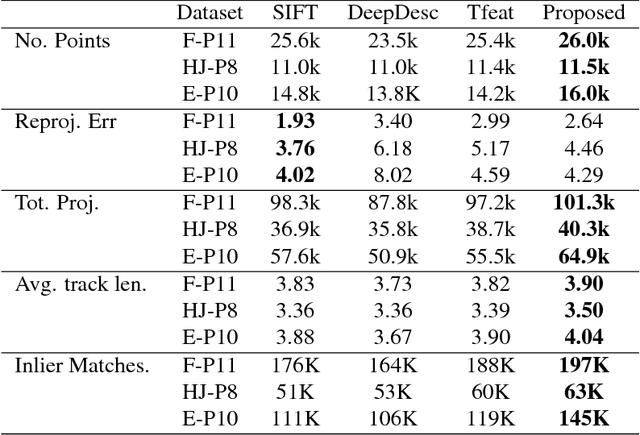
We propose a convolutional neural network (ConvNet) based approach for learning local image descriptors which can be used for significantly improved patch matching and 3D reconstructions. A multi-resolution ConvNet is used for learning keypoint descriptors. We also propose a new dataset consisting of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) [18] dataset. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. We evaluate our approach on publicly available datasets, such as Oxford Affine Covariant Regions Dataset (ACRD) [12], MVS [18], Synthetic [6] and Strecha [15] datasets to quantify the image descriptor performance. Scenes from the Oxford ACRD, MVS and Synthetic datasets are used for evaluating the patch matching performance of the learnt descriptors while the Strecha dataset is used to evaluate the 3D reconstruction task. Experiments show that the proposed descriptor outperforms the current state-of-the-art descriptors in both the evaluation tasks.